Descubra o TimescaleDB: O banco de dados SQL para séries temporais
Hoje vamos falar um pouco sobre o TimescaleDB …
Mas afinal, o que seria esse tal de TimescaleDB?
Respondendo a pergunta acima, TimescaleDB (TSDB) é um banco de dados de código aberto desenvolvido para tornar o SQL escalável para dados de séries temporais, lançado em abril de 2017 ele foi desenvolvido a partir do banco de dados PostgreSQL (PG) fornecendo o particionamento automático e preservando o padrão do PostgreSQL, ele é implementado como uma extensão no PostgreSQL, o que significa que roda dentro do próprio PostgreSQL.
Embora existam diversas soluções escalonáveis de séries temporais, o TimescaleDB se destaca por utilizar séries temporais sobre um banco de dados SQL convencional, isso significa que você obtém o melhor que os dois mundos podem oferecer.
O TimescaleDB faz com que o banco de dados saiba quais tabelas devem ser tratadas como dados de séries temporais (com todas as otimizações necessárias), mas nada impede você de continuar utilizando SQLs para séries temporais e tabelas regulares em seu banco de dados. As aplicações nem notam a existência de uma extensão TimescaleDB sob uma interface SQL convencional.
Para você utilizar uma tabela como séries temporais (chamada de hypertable), é necessário executar o procedimento create_hypertable do TSDB. Você pode pensar em blocos como partições de tabela que são gerenciadas automaticamente. E cada pedaço possui um intervalo de tempo associado. Para cada chunks, o TSDB também configura os índices dedicados assim as aplicações podem trabalhar com intervalos de dados sem tocar nas linhas e índices que pertencem a outros.
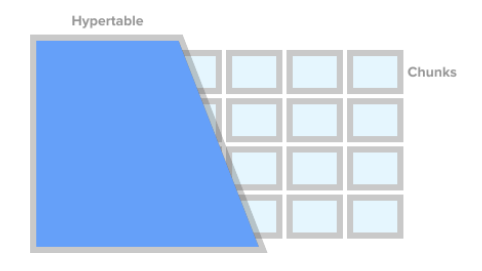
Imagem de exemplo de uma Hypertable de timescaledb.com
Hypertable ou Hipertabela: É a camada de abstração e o ponto principal de interação com seus dados usados para criar as tabelas e os índices, alterando as tabelas, inserindo novos dados, selecionando os dados.
Chunks: A hypertable é automaticamente dividida em chunks, cada chunks corresponde a um intervalo de tempo específico em uma região do espaço da partição.
Hora de praticar !
Chega de enrolação, vamos ver agora na prática como instalamos o TimescaleDB, supondo que você já possua um ambiente com o PostgreSQL instalado, pois nesse cenário é necessário possuir o PostgreSQL instalado.
Nesse laboratório utilizarei o PostgreSQL 11 no Ubuntu 18.04 caso esteja utilizando uma outra distribuição consulte o procedimento no manual de instalação através do link: https://docs.timescale.com/latest/getting-started/installation.
Agora o primeiro passo precisamos adicionar o repositório oficial do TimescaleDB e em seguida realizar um update na lista de pacotes nos repositórios:
add-apt-repository ppa:timescale/timescaledb-ppa apt-get update
Após realizar a instalação do repositório, vamos instalar o pacote do TimescaleDB apropriado para a versão do PostgreSQL instalado:
apt install timescaledb-postgresql-11
Feito a instalação vamos realizar o tunning do TimescaleDB:
timescaledb-tune --quiet --yes
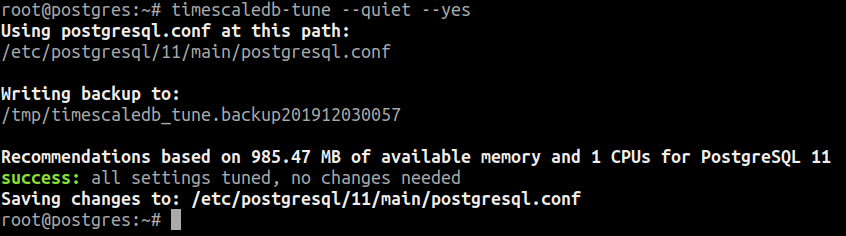
O comando timescaledb-tune é uma ferramenta criada para ajustar as configurações automaticamente, essas alterações são gravadas no arquivo de configuração do PostgreSQL postgresql.conf.
Em seguida reinicie o serviço do PostgreSQL:
systemctl restart postgresql
Vamos nos tornar o superusuário do PostgreSQL chamado “postgres” executando o comando:
su - postgres
![]()
Agora com o superusuário postgres vamos nos conectar no PostgreSQL utilizando o comando:
psql

Conectado no PostgreSQL podemos criar nossa primeira database chamada de website:
CREATE database website;

Vamos nos conectar na database criada e aplicar a extensão do TimescaleDB:
c website CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Agora vamos desconectar da database criada utilizando com comando:
exit

Podemos realizar um teste de conexão na database criada, executando o comando abaixo:
psql -U postgres -d website
Para criarmos uma hypertable, primeiro precisamos criar uma tabela, e depois convertê-la para hypertable através da função create_hypertable.
Vamos criar uma tabela chamada blog com as colunas time, post e acessos:
CREATE TABLE blog ( time TIMESTAMPTZ NOT NULL, post TEXT NOT NULL, acessos DOUBLE PRECISION NULL );
Em seguida, vamos transformá-la em uma hypertable com a função create_hypertable:
SELECT create_hypertable('blog', 'time');

Dessa forma estamos criando uma hypertable que será particionada por tempo usando os valores da coluna time.
Também podemos executar o comando ALTER TABLE na hypertable para adicionar novas colunas, vamos adicionar uma nova coluna chamada usuarios:
ALTER TABLE blog ADD COLUMN usuarios DOUBLE PRECISION NULL;

Dessa forma o TimescaleDB realizará automaticamente essa alteração no schema para as chunks que constituem essa hypertable.
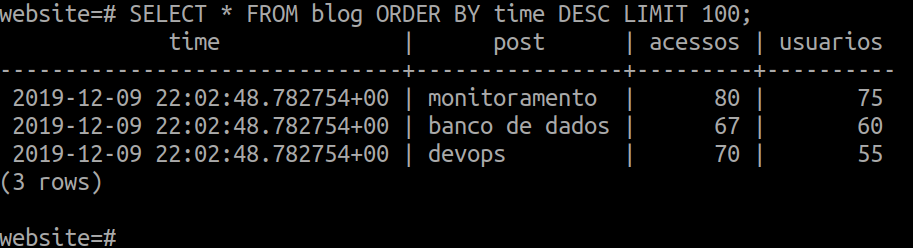
Também é possível utilizar o comando INSERT para inserir dados na hypertable, vamos popular as colunas time, post, acessos e usuarios com alguns valores:
INSERT INTO blog
VALUES
(NOW(), 'devops', 70, 55),
(NOW(), 'banco de dados', 67, 60),
(NOW(), 'monitoramento', 80, 75);

Podemos realizar consulta de dados através do comando SELECT, e visualizar as colunas com os dados que foram inseridos:
SELECT * FROM blog ORDER BY time DESC LIMIT 100;
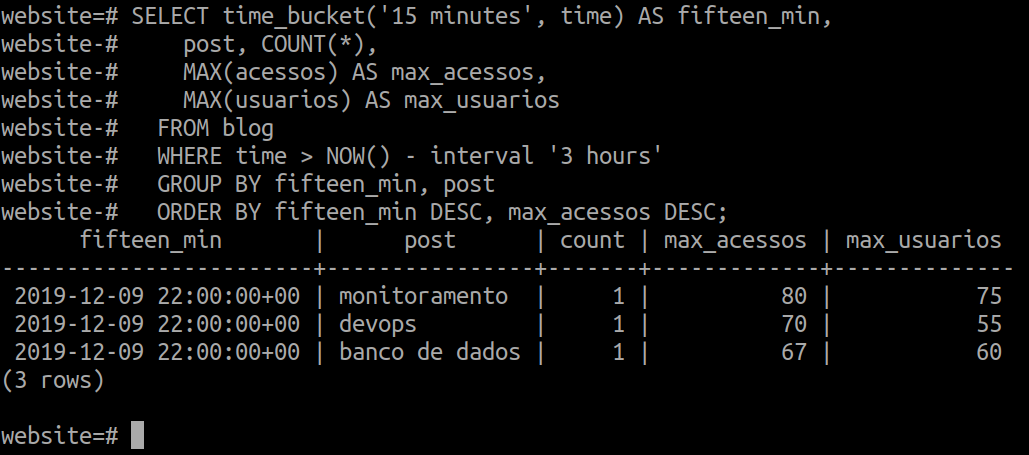
E também podemos realizar consultas mais elaboradas, utilizando WHERE, GROUP BY e ORDER BY:
SELECT time_bucket('15 minutes', time) AS fifteen_min,
post, COUNT(*),
MAX(acessos) AS max_acessos,
MAX(usuarios) AS max_usuarios
FROM blog
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, post
ORDER BY fifteen_min DESC, max_acessos DESC;
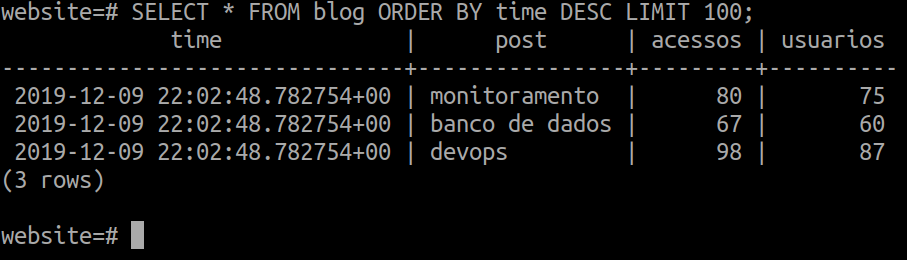
As atualizações de dados no TimescaleDB funcionam através do comando UPDATE, vamos atualizar os valores das colunas post, acessos e usuarios da tabela blog:
UPDATE blog SET acessos = 98, usuarios = 87 WHERE time = '2019-12-09 22:02:48.782754+00' AND post = 'devops';

Podemos realizar uma nova consulta com comando SELECT, e visualizar as mudanças realizadas:
SELECT * FROM blog ORDER BY time DESC LIMIT 100;
Os dados podem ser excluídos de uma hypertable usando o comando DELETE, vamos remover os dados com o valor menor que 80 na coluna acessos e também menor que 60 na coluna usuarios:
DELETE FROM blog WHERE acessos< 80 OR usuarios < 60;

Realizando uma nova consulta podemos visualizar os dados que foram removidos:
SELECT * FROM blog ORDER BY time DESC LIMIT 100;

Bom pessoal, esse post foi apenas uma introdução ao recurso TimescaleDB e o início de uma série de postagens, onde nos próximos irei demonstrar como o TimescaleDB pode ser útil em ambientes de monitoramento, sendo utilizado em conjunto com o Zabbix e também com o Prometheus.
Espero que tenham gostado, até a próxima!
สล็อตทดลองเล่นฟรีสล็อตเว็บตรงทดลองสล็อต PGทดลองเล่นสล็อตสล็อตเว็บตรงเว็บสล็อต PGเว็บสล็อตเว็บตรงสล็อตเว็บตรงufa191ไฮดร้า888
About author

Você pode gostar também

Como Recuperar a Senha do Root no MySQL: Guia Passo a Passo
Em muitas situações é necessário resgatar a senha para o usuário root no banco de dados MySQL. Entre elas, a mais comum é a necessidade de prestar manutenção a um
Curso de JBoss EAD em português: aprenda com os maiores especialistas do Brasil
A 4Linux com o seu já reconhecido pioneirismo no ensino de tecnologias livres acaba de lançar o curso de JBoss EAD, o único em português. O foco do curso é oferecer

Entenda o Snapshot: a ferramenta de backup que não para seu serviço
Atualmente, o termo snapshot tem se popularizado por sua utilidade nas mais variadas Clouds. Este snapshot em questão funciona na sua casa, na sua infraestrutura local e até mesmo na






