
Melhore a performance do seu Elasticsearch com um eficiente Capacity Planning

E aí meus amiguinhos, hoje vamos falar um pouquinho sobre o ElasticSearch, um motor de buscas para indexar dados de maneira fácil.
A ideia aqui é discutir um pouco sobre como fazer um Capacity Planning dos nossos clusters Elasticsearch de maneira assertiva e como mensurar o tamanho das máquinas necessárias para os dados.
Propósito do seu Cluster
O primeiro passo para medir e fazer um bom planejamento é saber qual o propósito do seu Elasticsearch, uma vez que isso determinará itens importantes como: quantidade de máquinas, valor investido, treinamento de equipe e etc.
Uso intenso ou moderado?
Você vai utilizar o seu cluster para pesquisas com transações que beiram a casa dos Gigas de transações por minuto ou seu uso será esporádico?
Os dados que você pretende salvar no Elastic serão tratados ou gravados diretamente da forma que chegam?
Tudo isso ajudará a determinar o número de máquinas e/ou configurações necessárias para planejar adequadamente o seu cluster.
Mas como fazer isso na prática? Vamos para o Hands On?
Colocando a Mão na Massa (Hands on)
Uma ideia comum ao falar sobre Capacity Planning é a de instalar uma ferramenta que testará a infraestrutura para você. Mas antes disso devemos pensar em como melhorar nossos índices, semelhante ao que faríamos em um banco de dados SQL, melhorando as queries e o desempenho das bases antes de pensar em apenas Hardware e, para isso, um bom ponto de partida é:
- Criar um ambiente simulado de produção e o teste a exaustão;
- Com base nos testes de simulação do ambiente, otimizar as configurações o máximo possível;
- Buscar consultas e corrigir qualquer pesquisa com coringa que possa degradar o ambiente;
- Instalar uma ferramenta de Capacity Planning para auxiliar você a mensurar;
Vamos detalhar o passo a passo então?
Simule a produção
O primeiro passo é criar um ambiente igual ao de produção que você possa usar para rodar todos os testes possíveis. Esse ambiente não precisa ter exatamente o mesmo tamanho do de produção, mas esse ambiente deve conter todos os itens que você teria em um ambiente de produção real, como os mapeamentos, analisadores, e transformadores, além de possuir a mesma fonte de dados. Você pode inclusive duplicar o Output do Logstash para atingir esse objetivo.
Teste, Teste e Teste mais
Teste todas as capacidades do seu índice, forçando-os até que quebre e deixe seu shard indisponível. Faça-o utilizar toda a capacidade de configuração disponível e todos os ajustes finos possíveis, e teste novamente até que ele falhe.
A ideia aqui é otimizar ao máximo as configurações do índice e shard para somente então partirmos para o Capacity Planning propriamente dito.
Faça a limpa em consultas coringa
Outro ponto crítico, que muitas vezes é negligenciado, é a consulta não otimizada dentro do cluster. Você deixaria uma consulta como “SELECT * FROM” sem “WHERE” dentro de um banco SQL de produção? Então por que será que muitos administradores de Elasticsearch esquecem de olhar justamente as consultas coringas, que podem estar degradando o ambiente todo?
Não existe exceção, uma consulta usando coringa “*” em uma base gigante vai causar degradação e sempre existe uma forma de refinar essa busca. Procure essas consultas e remova-as da base, trocando por uma pesquisa mais específica.
Outro ponto importante é ter cuidado com a distribuição da senha do Kibana, pois quem a tiver pode criar consultas com coringa e é importante também verificá-las no Kibana.
Finalmente faça o Capacity Planning
Agora que você já fez todos os tunnings possíveis e deu uma boa limpada na base, pode fazer um bom Capacity Planning, já que eliminou gargalos do índice e shards.
Uma ferramenta sugerida pela comunidade e pela Elastic é a EsRally. Ela produz uma saída detalhada de cada passo que o Elasticsearch executa, demostrando a volumetria e os tempos de resposta, medindo os tempos de indexação, merges, estatísticas do garbage collector e throughput de documentos indexados por segundo.
Usando EsRally
# yum install -y gcc python34.x86_64 python34-devel.x86_64 python34-pip.noarch # pip install virtualenv # virtualenv -p python3 /opt/esteste # source /opt/esteste/bin/activate # pip install esrally
Listando testes do EsRally:
# esrally track list
Executando um teste local no cluster
# esrally --distribution-version=7.14.0 --track=geopoint --challenge=append-fast-with-conflicts
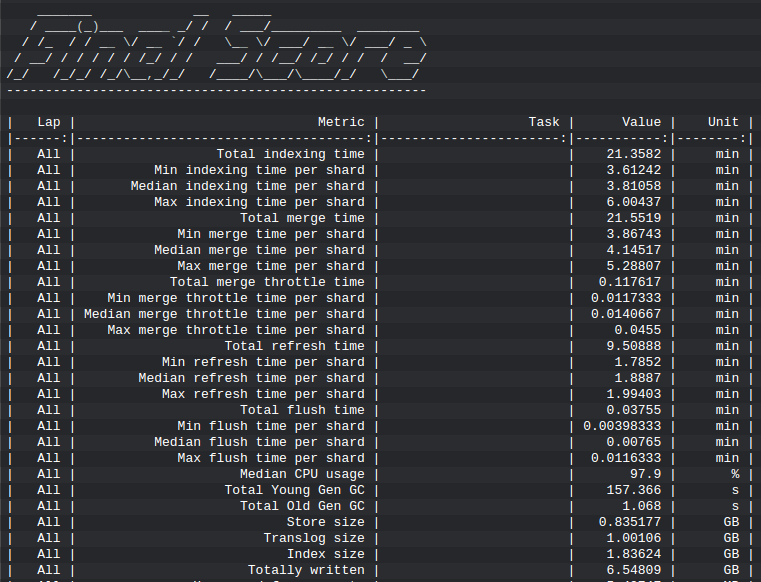
Principais resultados do EsRally
Index Time: Por quanto tempo o nó levou para indexar os documentos
Indexing Throttle Time: A indexação de tempo total, quanto menor melhor
Throughput: Medida de quantos eventos por segundo o cluster pôde manipular
Error Rate: Taxa de erros ou execeções lançadas pelo cliente ElasticSearch, idealmente isso deveria ser próximo de zero, mas sempre ocorre uns erros, o mais próximo de zero é melhor, se for muito grande, deve-se analisar os logs para procurar a causa raiz.
Com esses resultados e todo o pente fino que você já fez nos índices e shards, agora é só correr pro abraço, testando a capacidade desse cluster e adicionar hardware se necessário.
Finalizando
Bom pessoal, por hoje é isso. Vimos como podemos melhorar a performance dos nossos clusters Elasticsearchs de formas simples e como fazer um bom Capacity Planning.
Até a próxima.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Domine Monitoramento e Observabilidade em Cloud com a 4Linux
Você é um profissional de TI que busca se destacar no mercado e maximizar a eficiência da sua infraestrutura? A 4Linux traz para você a atualização do curso “Monitoramento e

4Linux atualiza seus cursos na área de Big Data!
Conheça os cursos de Big Data da 4Linux A fim de atender demandas específicas do mercado por profissionais de Ciência de Dados e Engenharia de Dados, a 4Linux decidiu reformular
Guia Completo: Instalação e Migração do Sistema OTRS na Google Cloud
Introdução OTRS, Open-source Ticket Request System (Sistema Livre de Requisição de Chamados), é um sistema de gerenciamento de incidentes, livre e de código aberto, que qualquer organização pode usar na





