
Descubra como o RabbitMQ pode otimizar o processamento de dados em seu sistema web
O RabbitMQ é um software de controle e gerenciamento de filas de mensagens. Ele recebe e armazena mensagens em filas até que alguém solicite essas mensagens.
As mensagens podem ser qualquer tipo de dado que possa ser representado como texto pois o valor não é lido pelo RabbitMQ.
Exemplos de uso
Quando pensamos em um sistema web temos a impressão de ser algo muito imediato, e essa é a sensação que os desenvolvedores tentam passar.
Mas na realidade, sistemas grandes possuem regras de negócio complexas e dificilmente é possível realizar o processamento de tudo que é necessário nos poucos segundos que dura uma requisição HTTP. Se faz necessário então que exista um processamento paralelo.
Pode-se dizer que com crons tudo isso seria resolvido. Mas uma cron ainda precisaria ter um parâmetro para saber o que exatamente ela deveria processar. Existiria então algum tipo de sistema de fila.
E o RabbitMQ vem para ajudar com isso. Ele pode ser utilizado para diminuir o custo de processamento e tempo de resposta em requisições web, fazendo com que tarefas complexas que podem demorar alguns segundos, minutos ou até horas, sejam processadas de forma assíncrona e podendo ser realizadas até mesmo por outros sistemas e máquinas.
Imagine um cenário onde temos um sistema que realiza correção de provas. E nesse sistema os professores precisam que seja gerado um PDF com as respostas de todos alunos. Buscar todos esses dados, dependendo da quantidade de informações pode demorá alguns minutos. O usuário não vai ficar todo esse tempo parado em uma página esperando o processamento concluir. E ainda por ser um sistema web, caso o usuário muda de página ou feche, a solicitação será perdida.
Para esse caso o RabbitMQ resolveria o problema muito bem. Com ele, quando o professor solicitar o PDF, a aplicação irá criar uma mensagem solicitando a criação do PDF. Com isso a requisição WEB já pode ser concluída e informar que o resultado será enviado por e-mail. Em seguida, de forma assíncrona e isolada, essa mesma aplicação ou até mesmo uma outra, irá se conectar a fila, solicitar uma mensagem e realizar o processamento conforme definido.
E a arquitetura basicamente é essa: Aplicativos clientes conhecidos como produtores (producers) criam mensagens e publicam em uma fila. Aplicativos consumidores (consumers) se conectam a fila e pega mensagens que precisam ser processadas. E um mesmo software pode atuar como produtor e consumidor. As mensagens permanecem disponíveis até que alguém busque por ela.
Como funciona
Na prática o RabbitMQ utiliza uma sequência com um pouco mais de etapas do que simplesmente publicar e consumir.
Temos basicamente a seguinte sequência:
- O producer (produtor) publica uma mensagem em um exchange. Sendo que esse exchange já precisa estar previamente definido e especificado seu tipo.
- Ao receber a mensagem, o exchange precisa fazer o roteamento. Será utilizado atributos da mensagem como cabeçalhos e propriedades para realizar o processo.
- Bindings são criados para realizar a ligação entre exchange e queues. Eles são utilizadas para realizar esse roteamento. Diferentes tipos de exchanges podem mudar o comportamento de uso dos bindings e regras de roteamento.
- Ao fazer o roteamento, as mensagens ficarão nas queues (filas) esperando serem consumidas.
- Um consumer (consumidor) faz a leitura da mensagem.
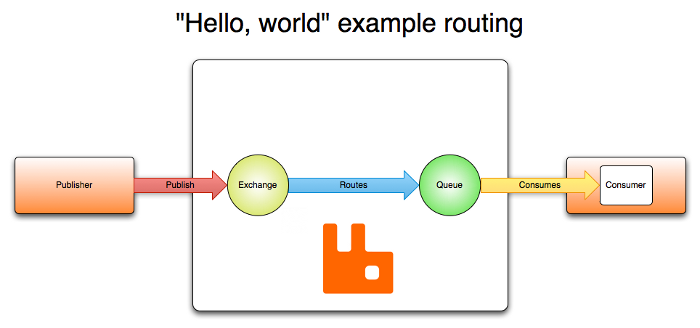
Como forma de se precaver de falhas de comunicação, as mensagens não são removidas até que haja uma confirmação que está tudo certo com ela.
Essa confirmação pode ser realizada automaticamente pelo o cliente ou manualmente conforme a regra de negócio implementada na aplicação.
Tipos de exchanges
O RabbitMQ possui quatro tipos de exchanges: direct, fanout, topic e headers.
Cada um podendo receber uma mensagem e retear para uma ou mais filas. O algorítimo a ser utilizado nesse roteamento vai depender do tipo do exchange e dos bindings definidos.
Temos basicamente a definição de cada tipo sendo:
- direct – A mensagem é encaminhada para todas filas que possuem a routing key que corresponda a definida no binding.
- fanout – A mensagem é encaminhada para todas filas que estão associadas ao exchange independente da routing key ou outros metadados fornecidos.
- topic – A mensagem é encaminhada para todas filas que possuem uma correspondência entre a routing key e o padrão especificado no binding. Esse padrão possui caracteres coringas, logo diferentes routing keys poderão ser aceitos.
- headers – A mensagem é encaminhada para todas filas conforme cabeçalhos definidos.
Por padrão o RabbitMQ possui um exchange do tipo direct chamado AMPQ default. Ele é pré definido para facilitar o uso em aplicações com regras simples. Para cada fila criada, automaticamente é adicionado uma routing key com o mesmo nome da fila. Assim é possível apenas declarar a fila e ao tentar publicar uma mensagem, fornecer seu nome e então ele receberá a informação desejada.
Um ponto importante é que o RabbitMQ não faz balanceamento entre filas. Ou seja, se mais de uma fila atender as regras do exchange, todas receberão a mensagem.
Algo a se lembrar é que caso não exista nenhuma regra que a fila se encaixe, ela será automaticamente descartada.
Inicializado o RabbitMQ
O jeito mais simples de começar a utilizar o RabbitMQ é via Docker. Imagens oficiais são disponibilizadas, podendo escolher apenas o serviço ou juntamente com uma ferramente de gerenciamento web.
Para iniciar a aplicação, podemos executar o comando:
docker run --rm -it -p 15672:15672 -p 5672:5672 rabbitmq:3.9-management
Com isso já termos a aplicação funcional e acessível.
Dentre as portas utilizadas, temos:
- 15672 – Interface de gerenciamento web.
- 5672 – Porta para conexão com a aplicação. Será utilizando ela que os consumidores e produtores irão se comunicar.
Podemos então acessar a interface web pelo endereço: http://localhost:15672 utilizando o usuário guest e senha guest.
Outra forma de utilizar o RabbitMq, podendo ser utilizado gratuitamente para desenvolvimento ou pagando para um ambiente produtivo, é via a CloudAMPQ https://www.cloudamqp.com.
Além disso, como forma de estudo, pode também utilizar um simulador (não oficial): http://tryrabbitmq.com.
Conclusão
Tivemos uma introdução sobre o RabbitMQ, falamos sobre oque ele nos ajuda e resolver e como que ele funciona.
Em breve traremos um mão na massa, mostrando exemplos de como utilizar esse sistema de fila e as diferenças entre os tipos de exchanges.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Descubra o Jitsi: a solução completa para videoconferências
Logo do Jitsi Introdução Durante o momento que vivemos, basicamente todas nossas interações se tornaram virtuais, com o home office sendo a alternativa primaria para muitas empresas, tivemos um súbito

Como Migrar do VMware ESXi para o Proxmox VE: Guia Prático de Quem Já Fez
Migrar de uma solução consolidada como o VMware ESXi para o Proxmox VE pode parecer arriscado à primeira vista. Mas se a sua empresa está sentindo o peso do licenciamento

Conexão com Cluster Kafka Hospedado em Kubernetes: Guia Completo
Nesse artigo vamos discutir questões relacionadas a como disponibilizar um cluster kafka hospedado em um k8s para aplicações que estejam hospedadas fora do cluster kubernetes. Não vamos tratar da instalação





