
Gerenciamento eficiente de dispositivos em bloco com LVM no ambiente GNU/Linux
LVM ou Logical Volume Management é uma solução para o fácil gerenciamento de dispositivos em bloco dentro do ambiente GNU/Linux via blocos virtuais. Como assim ? Vamos explicar.
Primeiramente todo o sistema GNU/Linux possui dispositivos, esses em sua maioria estão reconhecidos sobre o diretório /dev/ sendo os principais tipo bloco e caracter. Podemos ver um exemplo abaixo:

Nesse caso, temos a lista de 3 elementos dentro do /dev sendo eles:
- /dev/tty – Terminal interativo
- /dev/nvme0n1p1 – NVMe
- /dev/sda3 – SSD Sata 3
No início do output do comando ls -l podemos ver que a primeira letra identifica o tipo de dispositivo, sendo b para block devices ou dispositívos de bloco como HDDs, SSDs, NVMes, CD-ROM, USBs … entre outros que servem para armazenar dados de forma permanentes. Já os que começam com c ou character devices são dispositivos utilizados para transmissão de dados, como terminais virtuais, /dev/kmsg para mensagens do kernel via userspace ou o /dev/random que é o gerador de números pseudo-aleatórios.
LVM
Agora que sabemos disso, vamos para o LVM.
Todos que já formataram um disco no ambiente GNU/Linux sabem que existem alguns passos e limitações como o número de partições virtuais e estendidas, e também caso crie um particionamento errado, deixando pouco espaço para o /var/log ,por exemplo, pode acabar com os serviços que rodam naquela máquina parados, pois não existe mais espaço em disco.
E qual seria a solução ? Adicionar outro disco , formatar, particionar e posteriormente mover o seu /var/log para esse local. Muito trabalho, mas resolve, e imagine que isso pode ocorrer com partições mais importantes como o seu database path do PostgreSQL (/var/lib/postgresql/X.X/main), seu MongoDB (/var/lib/mongo) ou MySQL (/var/lib/mysql).
A alternativa que temos com o LVM é justamente o gerenciamento desses dispositivos de bloco de uma maneira mais inteligente e que permita algumas facilidades como a expansão em caso de disco cheio.
Basicamente pegamos nossos block devices , que podem ser – HDs, SSDs ou NVMes e agrupamos eles em grupos de volumes que posteriormente são consumidos em volumes lógicos. Portanto na arquitetura do LVM temos 3 elementos importantes, PV, VG e LV sendo:
- PV: Physical Volume, volume físico ou nosso HD sem ser particionado.
- VG: Volume Group, grupo de volumes ou o conjunto de PVs.
- LV: Logical Volume, volume lógico, ou seja, nossa partição.
Nessa estrutura o LV acaba sendo algo similar a partição que teríamos no disco rígido, mas nesse caso ele é parte de uma estrutura que pode envolver um ou mais discos. Na ordem de criação devemos seguir essa mesma sequência, criar nossos PVs, agrupar em um ou mais VGs e por fim criar os LVs.
LVM – Forma de Consumo
Dentro do LVM temos duas formas de consumo dos discos, ou PVs, uma Linear e outro Striped ou traduzindo para português algo como tiras ou marcações. O formato linear faz com que os discos que fazem parte de um VG sejam consumidos um a um, ou seja, se tenho dois discos de 1TiB primeiramente seria consumido todo 1TiB do primeiro disco para somente então começar a fazer uso do segundo disco. Já o striped teriamos a distribuição dos dados entre os dois discos levando a melhor utilização do recurso e aumentando seu IOPs (input/output operations per second, operações de entrada e saída por segundo), uma métrica de performance de disco muito importante.

Hands-on lab
Criando o Laboratório de LVM
Vamos explorar um pouco do LVM colocando a mão na massa. Crie uma maquina virtual e adicione 3 discos extras alem do disco principal. No VirtualBox deve ficar algo similar a imagem a seguir:
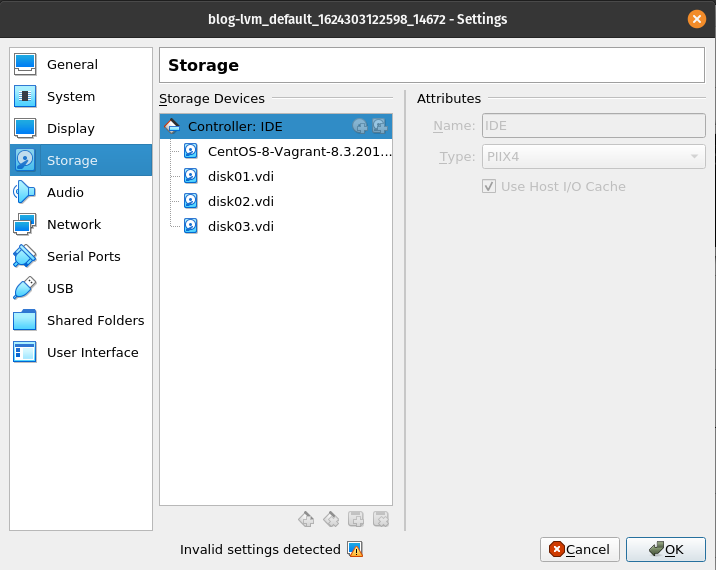
Se estiver em um ambiente GNU/Linux com Vagrant e VirtualBox instalados pode utilizar o Vagrantfile abaixo para criar de uma única vez:
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.box = "centos/8"
config.vm.network "private_network", ip: "192.168.100.10"
config.vm.disk :disk, name: "disk01", size: "100MB"
config.vm.disk :disk, name: "disk02", size: "100MB"
config.vm.disk :disk, name: "disk03", size: "100MB"
config.vm.provider "virtualbox" do |vb|
vb.cpus = "1"
vb.memory = "512"
end
end
Atenção! Estou fazendo uso do experimental flag (flags experimentais) para ativar o recurso de criação de disco extras. Então no seu terminal exporte a variável VAGRANT_EXPERIMENTAL=”disks” antes de iniciar a máquina.
Caso não conheça sobre Vagrant recomendo a leitura dos blogs a seguir:
- Vagrant: Crie ambientes de Desenvolvimento Ágil – Alison Machado
- Virtualização com Vagrant – Júlio Ballot
- Provisionando sua infraestrutura com Vagrant-Shell – Gabriel Nascimento
Assim que tiver a máquina rodando acesse seu terminal e como usuário root identifique se os discos estão presentes com o comando lsblk:
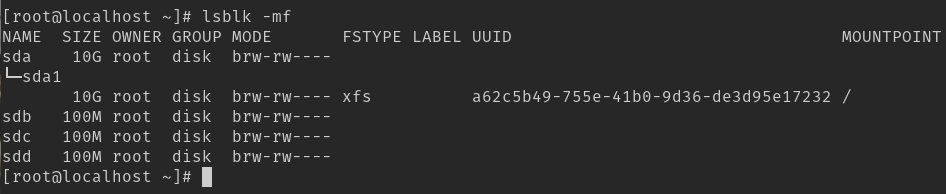
Os três discos sdb, sdc e sdd serão utilizados para criação do nosso LVM.
Instalando LVM
A instalação do LVM é bem simples e basicamente consiste em de instalar o pacote lvm2 presente na maioria das distribuições GNU/Linux. Como estamos utilizando o Centos 8 faremos uso do dnf para instalação.
dnf install -y lvm2
Assim que terminar de instalar, alguns utilitários estarão disponíveis no terminal:
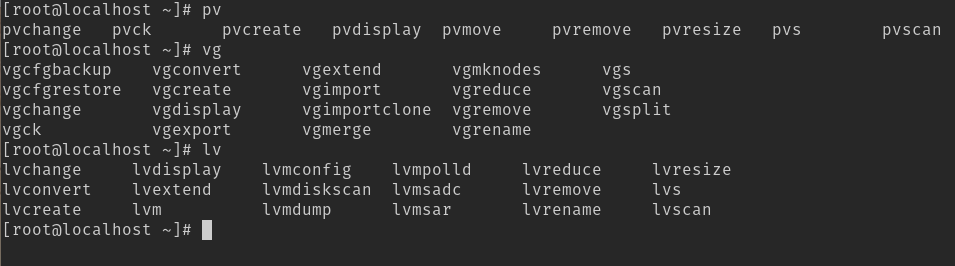
Não faremos uso de todos, mas recomendo a leitura do man de cada um ou pelomenos o entendimento geral das suas funcionalidades e usos.
Criando o primeiro LV
Como já mencionado para criarmos o LV precisamos antes criar o PV e VG. Portanto, iremos começar por criar o PV para cada disco extra presente no nosso sistema.
pvcreate /dev/sdd /dev/sdc /dev/sdb
É possível visualizar esses PVs via dois comandos: pvs e pvdisplay
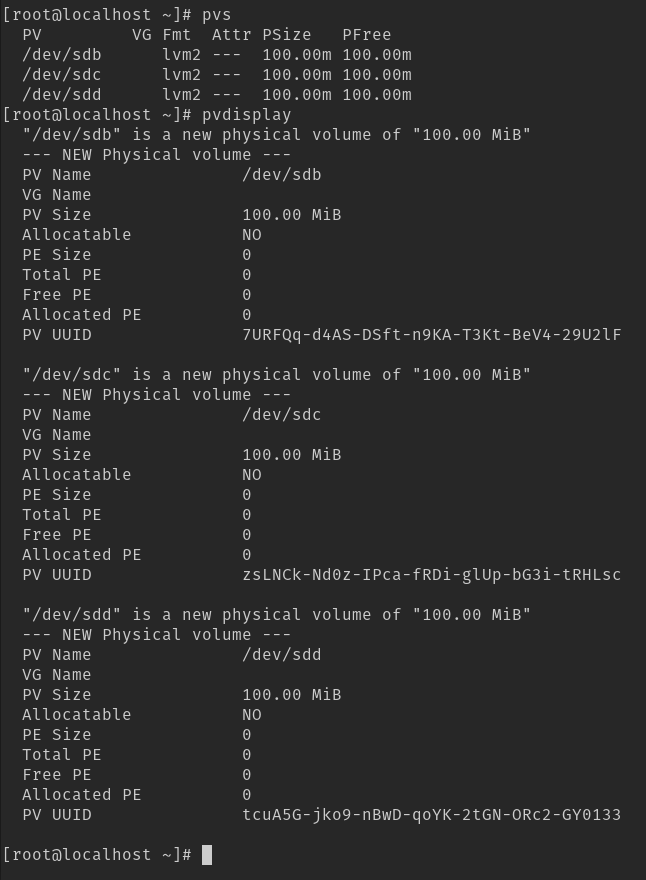
Agora criaremos o VG agrupando essas HDs em um único grupo. Para isso utilizamos o comando vgcreate:
vgcreate /dev/sdb /dev/sdc /dev/sdd
Da mesma maneira que visualizamos a configuração do PV com pvs e pvdisplay, podemos utilizar o vgs e vgdisplay para os Volume Groups:

Basicamente nesse momento nosso Volume Group, vg01, atua como um grande block device que iremos quebrar em LVs que se comportam como partições. Criando nossos LVs precisamos informar o nome e tamanho que iremos utilizar.
lvcreate -L 50Mib -n lv_var_log vg01

Dos parâmetros informados temos:
- -L 50MiB: Determina o tamanho do espaço que será criado, nesse caso 50MiB.
- -n lv_var_log: Esse é o nome dado ao LVM.
- vg01: O Volume Group que será utilizado para criar esse LV.
Neste caso como não foi especificada a forma de consumo, ficamos com a default Linear. Agora sim podemos formatar essa partição e montar para nossa utilização. Mas antes vamos visualizar o novo disco que está no caminho /dev/vg01/lv_var_log. Para isso, usamos o lvs e lvdisplay e podemos ver seu formato Linear via dmsetup, um utilitário de gerenciamento de disco de baixo nível.
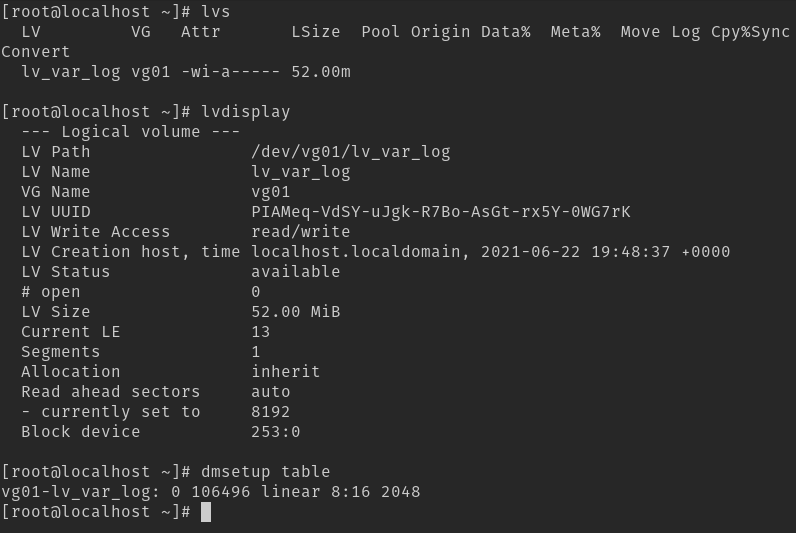
Existem muitas informações nessas saídas, portanto, recomendo a leitura do man de cada comando. Nesse momento o ponto mais importante é validar que foi criado e que está em modo Linear.
Formatar e utilizar a partição é bem simples, utilizaremos o comando mkfs.xfs e posteriormente poderemos montar esse LVM com o comando mount.

Resolvendo o Problema de Disco Cheio
Agora que temos um diretório montado, vamos explorar nosso problema inicial de disco cheio. Primeiramente vamos consumir nossos 50MiB de espaço. Para isso iremos rodar um simples comando que irá gerar um arquivo desse tamanho, o dd.
dd if=/dev/urandom of=/mnt/var_log/large_file bs=1MiB count=50
Nesse comando temos os seguintes parâmetros:
- if=/dev/random: Character device que usamos para Input File ou arquivo de entrada.
- of=/mnt/var_log/large_file: Nosso Output File ou arquivo de saída
- bs=1MiB: Quantidade de dados para ler/gravar por vez
- count=50: Quantidade de blocos que serão gravados
De forma mais livre podemos entender que leremos e gravaremos 1MiB por vez, 50 vezes, tentando gerar um arquivo de 50MiB. De cara encontraremos o problema a seguir:

Isso indica que não temos mais espaço em disco. Diferente de uma instalação sem LVM onde seria necessário adicionar outro disco para resolver esse problema, com LVM iremos simplesmente expandir nosso lv_var_log com o comando lvextand:
lvextand -L +50MiB vg01/lv_var_log

Os argumentos são similares ao lvcreate mas nesse caso iremos adicionar mais espaço em disco, por isso o +50MiB. Somente isso não irá resolver, precisamos informar o File Systems que ele deve utilizar esse espaço. Utilize o xfs_growfs:
xfs_growfs /mnt/var_log
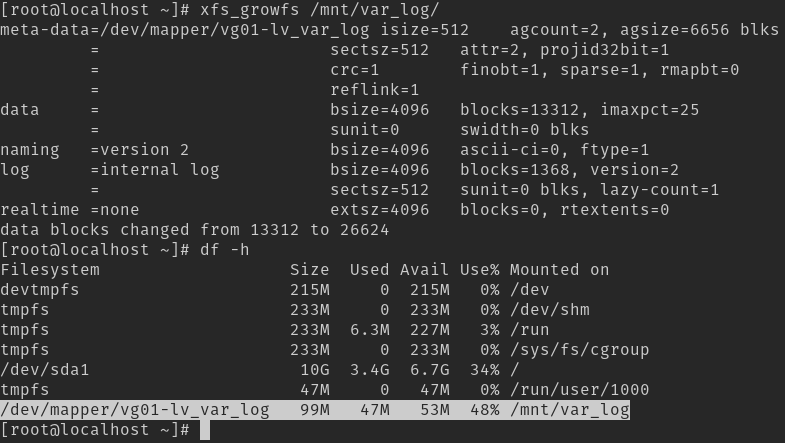
Isso já resolverá nosso problema e conseguiremos criar nosso arquivo.
Utilizando o próprio lvs conseguirmos verificar quais discos estão sendo utilizados para atender esse LV:
lvs vg01 -o +devices
Aqui estamos adicionando o output dos dispositivos a saída do lvs, gerando o resultado abaixo:

Criando um LV Striped
Como mencionado o LV striped irá utilizar da distribuição dos dados sobre um grupo de disco, fazendo melhor uso do espaço e permitindo maior IOPs. Para criar um LV Striped utilizaremos o mesmo lvcreate, só que agora com o parâmetro –stripes 2:
lvcreate -L 50MiB -n lv_striped --stripes 2 vg01

Olhando os discos via dmsetup veremos que o formato utilizado é striped, indicando que o dados foi distribuído. Podemos visualizar também via lvs como já mencionado.

Removendo LV
Para remover o LV é bem simples, basta utilizar o comando lvremove e informar o LV que deseja remover junto do VG:
lvremove vg01/lv_striped

Conclusão
Trabalhar com LVM vai muito além dos tópicos que discutimos aqui, mas já conseguimos perceber como ele é um poderoso aliado na administração de discos. Mesmo que clouds não venham a utilizar LVM é importante entender que muitas das tecnologias de base das Cloud, a virtualização, utilizam bastante de LVM. Ainda existem soluções em cluster que podem te ajudar bastante como o cLVM, mas nesse ponto já podemos começar a pensar em cluster distribuídos como o próprio Ceph.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Entenda o Processo de Consulta SQL no Sistema Gerenciador de Banco de Dados Postgres
Sempre que utilizamos o Sistema Gerenciador de Banco de Dados (SGBD) Postgres ou PostgreSQL, o foco principal de sua utilização é a realização de consultas (Querys), afinal de nada adiantaria

Avaliando a Segurança em Ambientes Kubernetes com Kubeaudit
Essa é a segunda parte falando de segurança em ambientes Kubernetes. Caso você ainda não tenha visto a Parte 1, fique a vontade para clicar no link abaixo: No post

Guia completo sobre PromQL: a linguagem de consulta do Prometheus
Nesse post vamos falar sobre o PromQL, que nada mais é do que uma linguagem de consulta do Prometheus, ela nos possibilita selecionar e agregar dados de séries temporais em





