Como utilizar o serviço RDS da AWS e receber o endpoint diretamente pelo Terraform
Contexto
Vemos no a necessidade de utilização de bancos para armazenar dados, sejam quais forem. Para tanto, temos a solução RDS da AWS, um serviço de banco de dados relacional.
Essa tecnologia nos provê um endpoint para poder conectar no banco e realizar operações, mas como podemos receber este endpoint diretamente no Terraform?
Criando a infraestrutura
Vamos utilizar somente o RDS neste post, visto que nosso maior objetivo é receber seu endpoint diretamente pelo terraform
Para tanto é preciso criar um arquivo chamado main.tf e nele indicar nosso provider, no caso a AWS
# No bash o ">" redireciona a saida padrão para um arquivo, porem quando utilizado sem saída ele cria um arquivo ^^ >main.tf
Coloque o código abaixo para iniciarmos o plugin do terraform aws
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "3.64.1"
}
}
}
provider "aws" {
region = "us-east-1"
}
Rode o comando para inicializar o plugin
terraform init
Depois disso podemos criar o código que conterá nosso rds em um arquivo chamado rds.tf
resource "aws_db_instance" "default" {
allocated_storage = 10
engine = "mysql"
engine_version = "8.0.23"
instance_class = "db.t2.micro"
name = "linux"
username = "teste"
password = "testandoRDS"
skip_final_snapshot = true
}
Agora podemos subir a infraestrutura:
terraform apply
Assim, já teremos nosso banco criado na aws e rodando prontinho para uso 🙂
Porém ainda precisamos do endpoint deste banco, motivo pelo qual vamos utilizar os outputs do terraform.
Que nada mais são do que as saídas que a própria API do nosso provider(aws) nos fornecerá.
Basta criarmos um arquivo chamado output.tf e inserir o código abaixo.
Neste caso buscamos somente o endpoint pois é o que nos interessa:
output "rds_endpoint" {
value = aws_db_instance.default #é importante ressaltar que o value se torna o nome_do_recurso.id_do_recurso
description = "endpoint do RDS"
sensitive = true
}
Agora ao rodar novamente o terraform apply teremos a seguinte saída
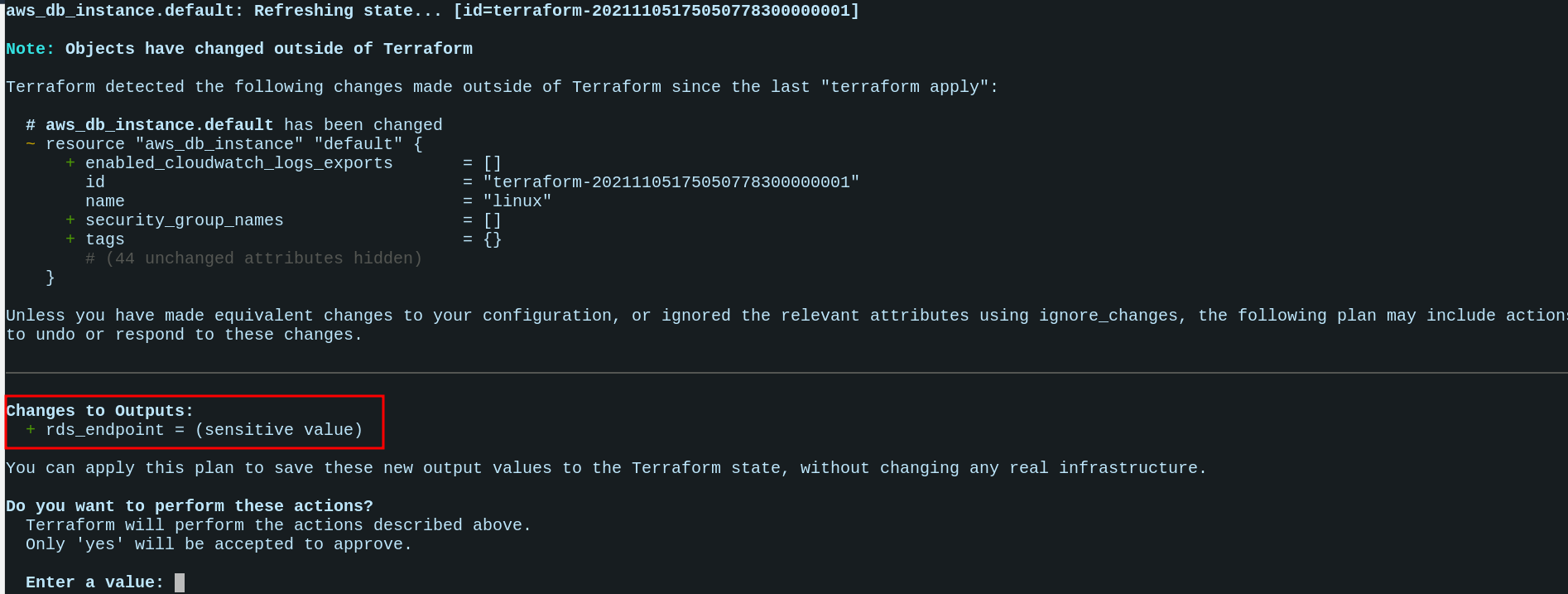
Dessa forma, podemos agora visualizar os outputs gerados pelo terraform.
Por padrão, ele gera diversos outputs, mas criamos esse em especial para que possamos ter acesso ao nosso banco de forma facilitada.
Para visualizar o output é preciso rodar o comando abaixo:
terraform output -json
e teremos uma saída em formato json no terminal, no meio desta bagunça está o nosso endpoint

Para facilitar a visualização podemos utilizar o parser de json chamado jq
![]()
Com isto temos a visualização exata do valor do nosso endpoint 😀
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Aprenda a criar módulos com Terraform na prática
Este seria o último capítulo da nossa série de postagens sobre Terraform, mas se podemos também falar sobre versionamento de infraestrutura, acho que vale a pena no aprofundarmos em mais

Docker BuildX: Otimizando sua Pipeline de Infraestrutura como Código
Transforme seu processo de criação de imagens Docker e eleve sua infraestrutura ao próximo nível com esta extensão poderosa do Docker CLI. Por que ainda usar apenas Docker Build em

OpenClaw na prática: 10 ideias reais para usar no dia a dia
Quando alguém conhece o OpenClaw, a primeira dúvida quase sempre é a mesma: beleza, mas onde isso realmente pode ser usado no dia a dia? Na teoria, muita coisa parece





