Entenda o Log Binário do MySQL e suas aplicações práticas
O log binário do MySQL é, por vezes, mal compreendido, principalmente por usuários de outros bancos de dados. Nesta postagem pretendo abordar alguns aspectos desse importante mecanismo.
Write-ahead logging?
Também conhecidos como “WAL”…
Não! O log binário não é o log transacional do MySQL, ou, mais precisamente, do InnoDB. O log transacional do InnoDB são os arquivos ib_logfileN, onde “N” representa um número maior ou igual a 0. Geralmente o log transacional do InnoDB está no diretório de dados e são apenas dois arquivos: ib_logfile0 e ib_logfile1.
Estes logs não estão relacionados com o log binário e são utilizados pelo InnoDB para refazer operações que eventualmente ficaram incompletas em algum processo de desligamento inesperado.
O Log Binário
Também conhecido como “binary log”, “binlog” ou log binário, são os arquivos que guardam de maneira sequencial e cronológica todas as operações que modificam os dados e as estruturas das tabelas do MySQL. O MySQL fará isso desde que a função de log binário esteja habilitada. Podemos habilitá-la através da variável log_bin.
O log binário é muito utilizado para PITR e para replicação, já que a replicação simplesmente lê o log binário para aplicar as modificações em si.
A ferramenta para ler o log binário chama-se mysqlbinlog. Normalmente a utilizamos em processos administrativos de recuperação.
Por padrão o MySQL guarda os logs binários no diretório de dados com o prefixo “binlog.” acrescido de um número sequencial, por exemplo, binlog.000001. O arquivo de terminação “.index”, por exemplo, binlog.index, é utilizado internamente pelo MySQL para identificar qual arquivo é o atual.
Como cada operação de escrita que acontece dentro do banco acontece também dentro do log binário, na prática estamos dobrando a escrita. Sendo assim, os arquivos binários são bons candidatos a utilizarem um disco específico para evitar concorrência de I/O com os dados em bancos operando perto do limite. Isso pode ser feito através da variável log_bin, que pode tanto indicar um diretório como o prefixo do nome do arquivo.
Os logs binários são rotacionados quando chegam ao tamanho especificado pela variável max_binlog_size, que por padrão é 1GB, ou quando o comando “FLUSH LOGS/FLUSH BINARY LOGS” é executado.
Durante a rotação, o MySQL acrescenta o contador do prefixo gerando um novo arquivo, por exemplo, binlog.000002.
O MySQL não expurga os logs binários automaticamente, isso deve ser feito através das variáveis expire_logs_days e binlog_expire_logs_seconds.
Formato do Log Binário
O MySQL trabalha com dois formatos de escrita dentro do log binário: o “statement-based logging” e o “row-based logging”.
É possível controlar o formato através da variável binlog_format para “STATEMENT”, “ROW” ou “MIXED”, que escolhe automaticamente uma forma ou outra, dependendo do caso.
Independentemente do formato, o log binário “começa” e “termina” sempre da mesma forma. Existe uma espécie de cabeçalho indicando a versão do servidor que o gerou, a versão do binlog e um rodapé indicando qual o próximo arquivo na cadeia e onde ele começa:
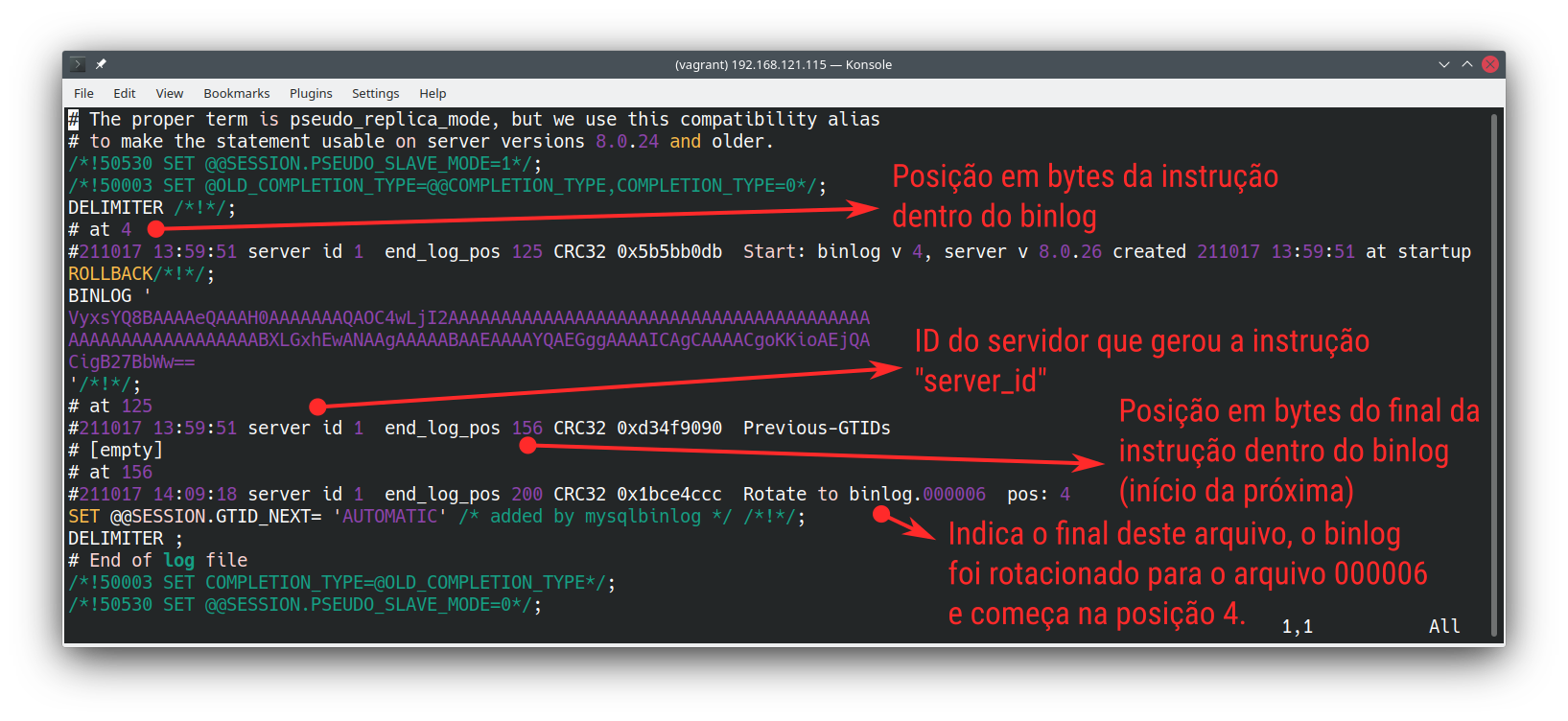
O binlog acima foi extraído com a ferramenta mysqlbinlog, ele começa e termina sem nenhuma instrução, isso significa que foi rotacionado antes de alguma operação acontecer dentro do banco. Quando observamos um binlog que ainda está em uso pelo servidor ou que não foi finalizado por algum motivo, não há aquela mensagem de rotação ao final e haverá um aviso no início avisando esse possível “problema”, afinal, o binlog pode estar corrompido.
As posições indicadas na figura, juntamente com as datas, podem ser utilizadas para extrair uma janela específica de instruções. Normalmente fazemos isso com PITR ou na inicialização dos “slaves” da replicação.
É importante lembrar que o binlog sempre começa aos 4 bytes do arquivo, isso é útil para iniciar réplicas sem restauração, quando tudo ainda está nos logs binários.
Statement
No formato “statement”, ou lógico, as operações são escritas no log binário da mesma forma que foram executadas no banco. Isso significa que o comando “UPDATE” executado dentro do MySQL é escrito exatamente desta forma dentro do log binário.
Este tipo de log binário é mais simples, utiliza menos espaço do disco e menor tráfego de rede para as replicações, mas caso seja replicado, pode gerar resultados não determinísticos, tornando as réplicas inconsistentes.
Abaixo, executo dois comandos no banco e em seguida os encontro no log binário. A saída foi extraída, jogada em um arquivo “.sql” e aberta com o editor:
mysqlbinlog /var/lib/mysql/binlog.000006 > mysql.sql
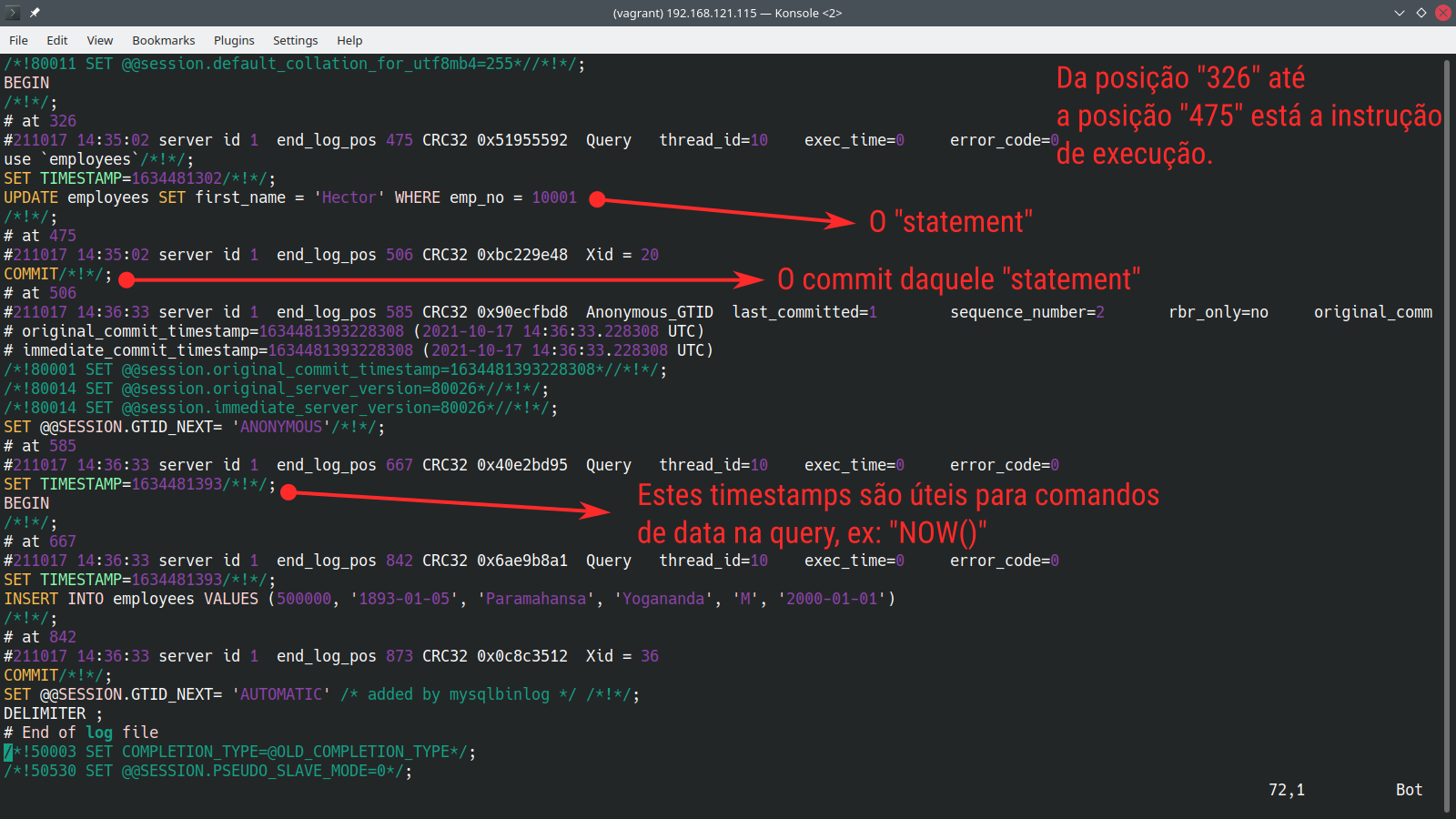
Neste caso eu simplesmente fui até o final da saída do comando mysqlbinlog. É possível observar que o comando está salvo no arquivo exatamente da mesma forma que foi digitado, sem nenhuma alteração.
Aqueles timestamps são necessários para queries que utilizem comandos de data. Desta forma é garantido que a data será a mesma quando esta instrução for reexecutada em algum lugar.
Uma outra desvantagem do formato “statement” está na reexecução destes comandos, os servidores de réplica precisam retrabalhar toda a lógica novamente. Antigamente isso era um problema maior, pois os “slaves” não podiam executar os comandos de forma paralela e acabavam ficando para trás.
Se fôssemos filtrar pela posição ou pela data, executaríamos o seguinte comando:
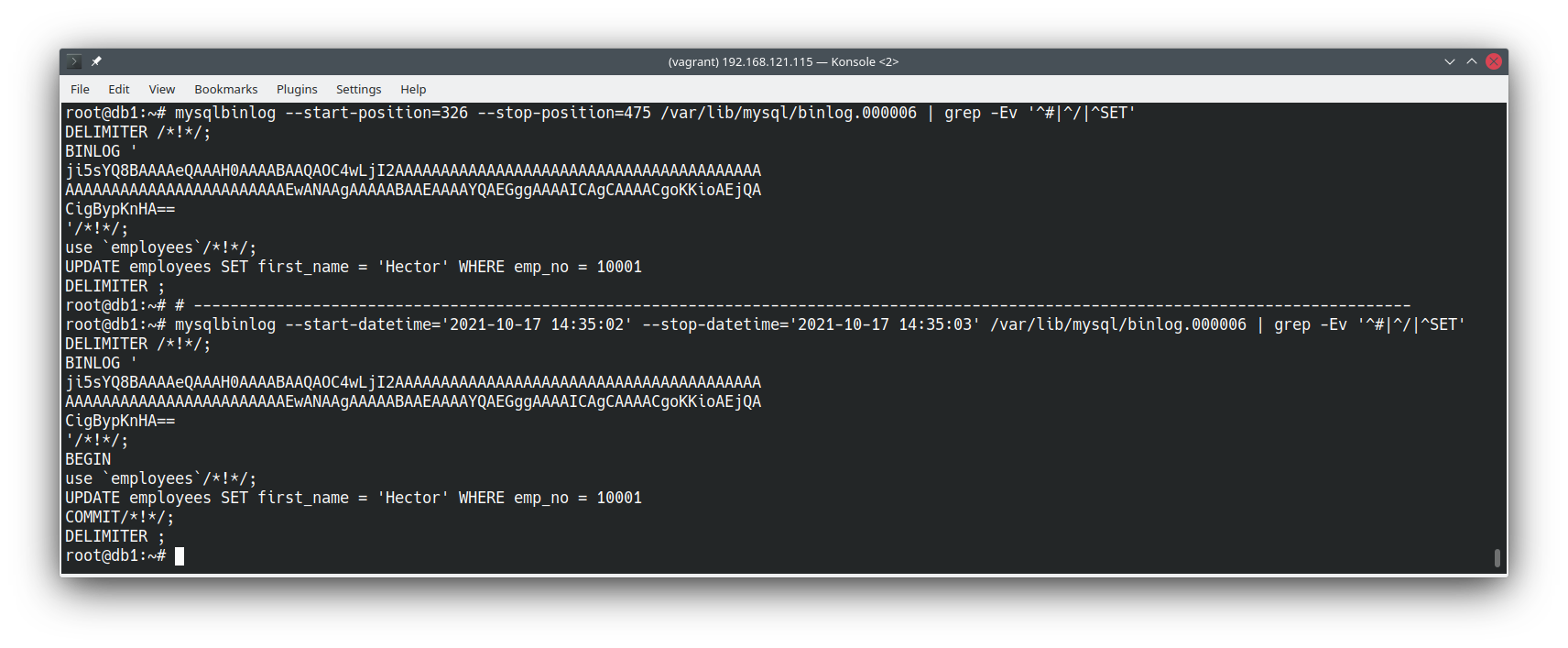
No caso acima, eu removi, através do grep, comentários e outras instruções que não são importantes para o nosso caso de uso, afinal, a saída sempre acrescenta aquele cabeçalho com o base64 e outras dezenas de comentários.
Row
No formato “row”, ou físico, as alterações de como a “linha tem que ficar” são adicionadas no binlog, a diferença é grande.
Abaixo temos os mesmos dois comandos executados, porém com o formato de log diferente. Veja como a saída é mais extensa:
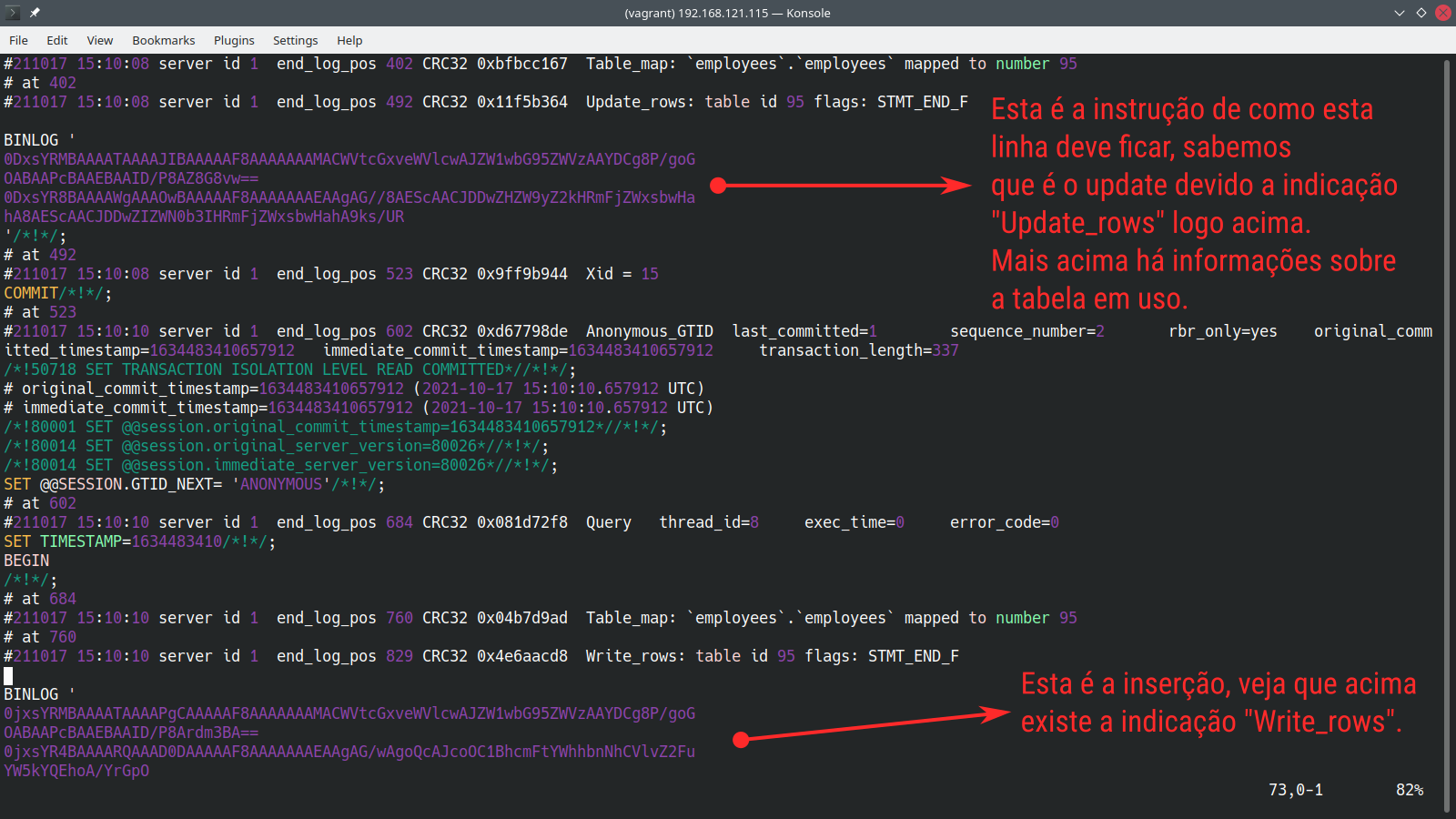
A saída do formato “row” assusta um pouco e por vezes dificulta encontrar as instruções que queremos, mas existe uma vantagem muito interessante: os comandos update guardam tanto a alteração como a versão anterior. O trecho a seguir foi extraído com o seguinte comando:
mysqlbinlog -vv /var/lib/mysql/binlog.000008
Um único “v” escreve também a query completa, um segundo “v” traz os tipos daqueles campos. A saída ficará muito maior:
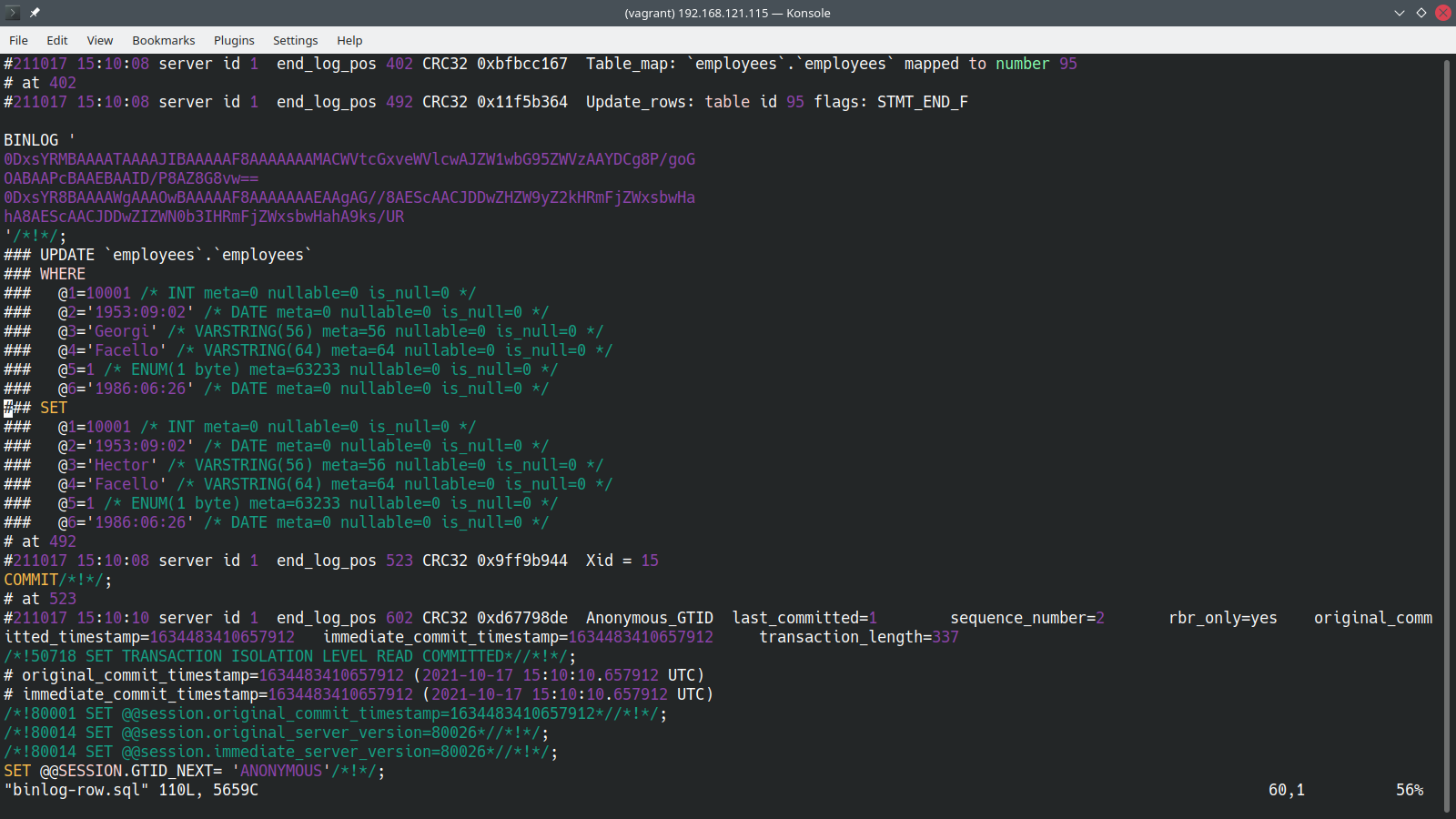
É possível notar que a condição do “WHERE” do “UPDATE” engloba todos os valores anteriores, já o “SET”, todos os valores atuais.
Através destas informações, é possível restaurar registros específicos que foram alterados indevidamente.
Mixed
O formato “mixed” é uma mistura dos dois e tenta trazer o melhor dos dois mundos. O MySQL escolhe automaticamente o formato utilizado visando menor tamanho do arquivo e menor tráfego de rede. A escolha é feita pela possibilidade do comando ser determinístico ou não. Caso exista algum risco daquele comando gerar um resultado diferente do original, a instrução é salva como “ROW”, do contrário, o formato “STATEMENT” é utilizado.
PITR
O log binário é muito útil para restaurar os dados restantes entre as janelas de backup. Caso façamos backups todos os dias à meia-noite, se algum problema ocorrer entre um backup e outro, o máximo que poderemos restaurar é o dia anterior. Se utilizarmos os logs binários, poderemos restaurar todo o restante até determinado ponto.
É possível reaplicar o log binário diretamente no MySQL da mesma forma que aplicamos um dump, por exemplo:
mysqlbinlog /var/lib/mysql/binlog.0* > restore.sql mysql < restore.sql
É claro que não é tão simples assim, é necessário saber o que estamos restaurando e fazer filtragens de períodos específicos em situações de recuperação de desastres.
Como este assunto é mais extenso, farei uma publicação a respeito aqui mesmo no nosso fórum.
Replicação
Como já disse, o log binário é utilizado também para replicação, e neste caso a quantidade de log binário presente no “master” é quem define a janela de manutenção que temos no “slave”. Caso o “slave” seja parado e o último log que ele tenha ciência tenha sido expurgado pelo “master”, a replicação não poderá continuar, será necessária uma restauração completa.
Durante a replicação é que encontramos a maioria dos problemas dos tipos de formato. O formato “ROW” é excelente para consistência, mas ruim para transferências através da internet ou redes sobrecarregadas.
O formato “STATEMENT” é menor. Excelente para transferências em redes mais fracas, mas pode gerar problemas de consistência e alguns cuidados do lado da aplicação são necessários.
Conclusão
Nesta postagem vimos para que serve o log binário, quais as diferenças entre seus formatos e como inspecioná-lo.
É uma postagem mais teórica, mas este assunto será base para outras postagens que farei em seguida.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Guia completo: Instalação e configuração do SQL Server no Linux
O SQL server é um sistema gerenciador de banco de dados relacional, mantido pela Microsoft. Originalmente estava disponível apenas para distribuições Windows, como o Windows Server. Desde a versão do

Guia definitivo: Como gerenciar sua infraestrutura com Terraform
Em meio ao caos que o Corona Vírus tem causado em todo o globo, chegamos ao último post da nossa série de postagens sobre Terraform. Caso tenha perdido os 5

Kubernetes – Configurando um Cluster Multi-Master
Neste post vamos configurar um cluster Kuberentes Multi-Master apenas com a sua máquina. Mas antes de falarmos sobre um cluster em Kubernetes trabalhando em modo Multi-Master… Uma palavra sobre containers…





