
DeepSeek – Reinforcement Learning – RL
Como a DeepSeek Funciona? A Arquitetura por Trás do Modelo
A DeepSeek não é apenas mais um modelo de linguagem de grande escala (LLM). Sua abordagem inovadora de treinamento e arquitetura a diferencia significativamente de outras inteligências artificiais, como as desenvolvidas pela OpenAI e pela Anthropic. Mas o que torna a DeepSeek única? Vamos explorar sua tecnologia e como ela funciona na prática.
O Aprendizado por Reforço Puro (RL) da DeepSeek
A DeepSeek utiliza um método revolucionário de aprendizado chamado Aprendizado por Reforço Puro (Reinforcement Learning – RL). Diferente dos modelos tradicionais, que são treinados com grandes volumes de dados supervisionados, a DeepSeek permite que sua IA aprenda sozinha, ajustando seu raciocínio de maneira autônoma.
Principais pilares do treinamento da DeepSeek-R1
O DeepSeek-R1 é construído sobre três conceitos fundamentais:
- Aprendizado por Reforço Puro (R1-Zero): O modelo é treinado sem exemplos pré-definidos de raciocínio, permitindo que ele desenvolva padrões cognitivos emergentes através de tentativa e erro.
- Treinamento Progressivo em Estágios (R1): A IA é aprimorada ao longo do tempo, refinando suas respostas e melhorando sua interpretabilidade.
- Destilação de Modelos: O conhecimento adquirido é transferido para versões mais compactas e eficientes, mantendo a qualidade do raciocínio.
Como a DeepSeek se Compara a Modelos Tradicionais?
A principal diferença da DeepSeek para modelos como o GPT-4 está na forma como ela aprende e evolui. Modelos como o GPT-4 utilizam aprendizado supervisionado, onde um conjunto de dados rotulados ajuda a IA a gerar respostas mais precisas. Já a DeepSeek se ajusta automaticamente sem precisar de intervenção humana direta.
Isso traz várias vantagens:
- Menor custo de treinamento: Sem a necessidade de supervisão humana, o DeepSeek-R1 reduz os gastos operacionais.
- Mais flexibilidade: O modelo pode se adaptar a novas situações sem precisar de um conjunto de treinamento pré-definido.
- Melhor desempenho em raciocínio lógico e matemática: Em benchmarks, a DeepSeek-R1 superou modelos concorrentes em tarefas complexas.
Benchmarks: A DeepSeek em Testes de Desempenho
Para provar sua eficiência, a DeepSeek foi submetida a diversos testes de performance e os resultados impressionaram:
- AIME 2024 (Competição de Matemática Avançada): Precisão de 79,8%, superando o OpenAI o1.
- Codeforces (Desafio de Programação): Acertou mais de 96,3% das questões, superando a maioria dos humanos.
- Benchmark MATH-500: 97,3% de precisão, rivalizando com o modelo da OpenAI.
A imagem a seguir detalha estes números:
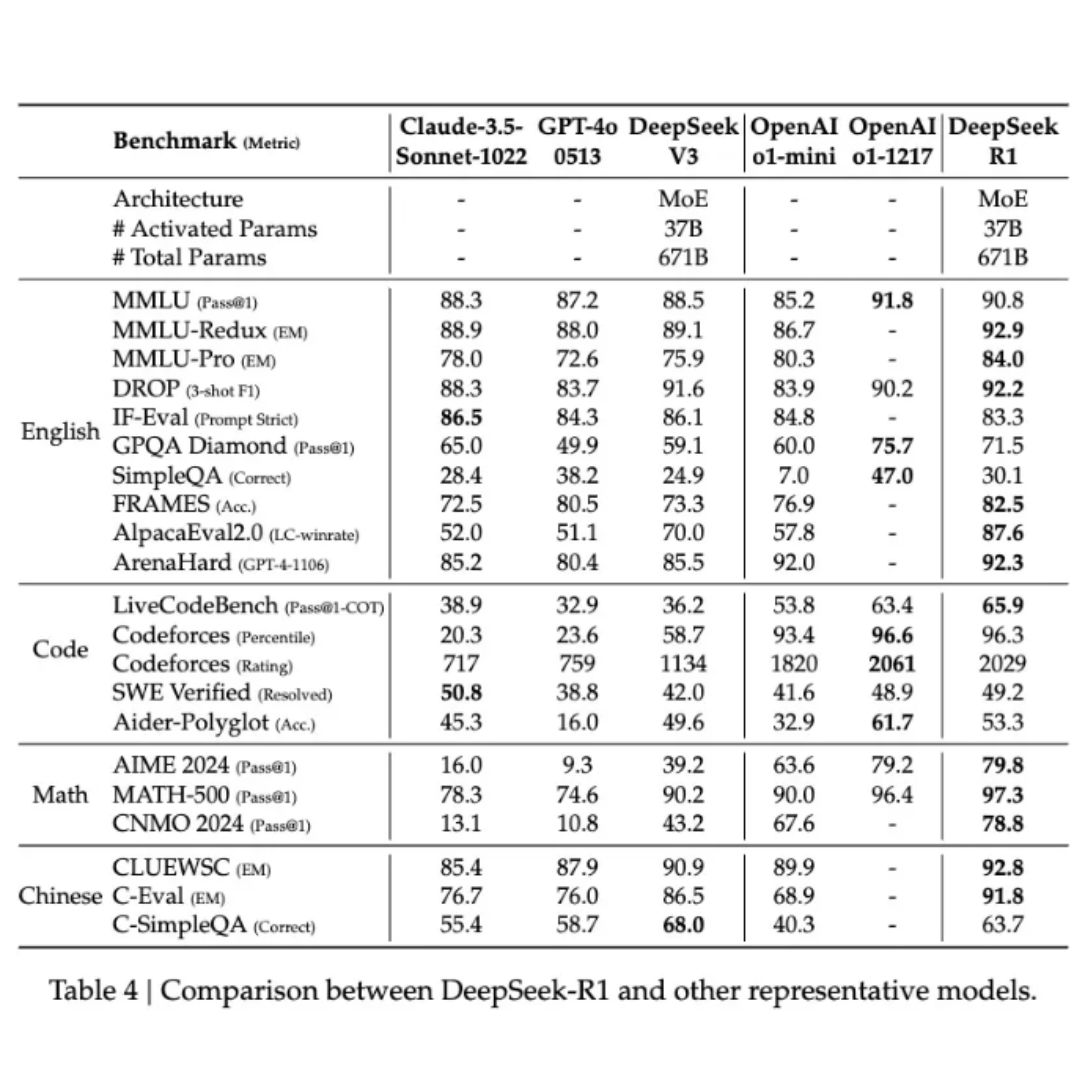
Fonte: Artigo científico da própria DeepSeek
Explicando a imagem acima de maneira didática:
English (Inglês) → Mede a capacidade dos modelos de entender e responder perguntas em inglês, incluindo interpretação de textos, raciocínio lógico e avaliação de instruções complexas.
Code (Código) → Avalia a capacidade dos modelos de gerar e entender código de programação, resolvendo problemas de lógica e desenvolvimento de software.
Math (Matemática) → Testa o desempenho dos modelos em resolver problemas matemáticos, incluindo álgebra, cálculo e desafios de raciocínio lógico avançado.
Chinese (Chinês) → Mede a habilidade dos modelos em interpretar e responder perguntas em chinês, abrangendo compreensão de texto e desafios linguísticos específicos da língua.
Dentro dos quatro grupos acima, existem outras siglas. Seguem abaixo um exemplo do que são tais siglas.
MMLU (Massive Multitask Language Understanding) (por exemplo) – Avalia o conhecimento geral da IA com perguntas de diversas áreas, como ciências, história e matemática.
CodeForces (por exemplo) – Plataforma de desafios de programação usada para testar a capacidade da IA de resolver problemas de código.
Math-500 (por exemplo) – Conjunto de problemas matemáticos avançados que mede a habilidade da IA em raciocínio lógico e cálculos complexos.
Tabelas assim são comuns para que as LLMs possam ser medidas entre si.
Esses números mostram que a DeepSeek não apenas rivaliza com modelos proprietários, mas os supera em diversas categorias essenciais para IA avançada.
Como o Aprendizado por Reforço Puro Funciona?
Diferente dos modelos tradicionais, que são treinados com exemplos supervisionados e ajustados com redes neurais de recompensa complexas, a DeepSeek-R1 abandonou completamente essa abordagem. Em vez disso, o modelo foi exposto a um sistema de recompensas extremamente simples, baseado apenas em dois critérios:
Recompensa de Precisão
Se a resposta estiver correta, o modelo recebe pontos positivos. Se estiver errada, perde pontos. Para questões matemáticas, a validação ocorre automaticamente com base na resposta final gerada.
Recompensa de Formato
O modelo deve colocar seu processo de pensamento entre as tags <think> … </think>. Se não seguir essa estrutura, perde pontos. Isso permite que a IA organize seu raciocínio de forma legível. Com esse método, a IA é incentivada a testar, errar e refinar seu raciocínio até desenvolver capacidades de reflexão espontânea, sem necessidade de exemplos explícitos fornecidos por humanos.
Um dos grandes momentos da DeepSeek
Uma das descobertas mais impressionantes durante o treinamento do DeepSeek-R1-Zero foi a emergência (no contexto da IA, comportamento emergente refere-se a capacidades inesperadas que surgem espontaneamente em modelos complexos, sem que tenham sido explicitamente programadas) de um comportamento semelhante ao pensamento humano.
Isso demonstra um nível inédito de raciocínio reflexivo, onde a IA percebe suas próprias falhas e se ajusta sem intervenção externa. Esse fenômeno é completamente espontâneo e não foi programado na arquitetura do modelo.
A imagem a seguir mostra esse grande momento na prática, destacando como o DeepSeek-R1 interrompe a resolução da equação e reavalia seu próprio raciocínio.

Fonte: Artigo científico da própria DeepSeek
Explicação para leigos da imagem acima
1. A questão apresentada à IA
A pergunta pede que o modelo encontre a soma das soluções reais da equação matemática:
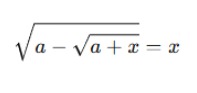
2. O processo de resolução
- O modelo começa elevando ambos os lados da equação ao quadrado para simplificá-la.
- Em seguida, ele reorganiza os termos para isolar a raiz quadrada.
- Continua transformando a equação para encontrar os valores de x.
3. O “momento aha” da IA
- No meio do processo, a IA para e sinaliza um possível erro:
→ “Wait, wait. Wait. That’s an aha moment I can flag here.”
(Espere, espere. Esse é um momento aha que posso sinalizar aqui.) - O modelo percebe que pode ter cometido um erro e decide reavaliar seu próprio raciocínio antes de continuar.
4. Por que isso é impressionante?
- Tradicionalmente, as IAs seguem instruções rigidamente e não costumam questionar seus próprios processos.
- No entanto, o DeepSeek-R1-Zero está demonstrando um comportamento emergente de reflexão.
- Ele age de forma parecida com um ser humano que resolve um problema matemático e percebe que pode ter cometido um erro, voltando para conferir.
5. O impacto dessa descoberta
- Esse comportamento emergente sugere que a IA está desenvolvendo habilidades de raciocínio em vez de apenas seguir padrões pré-programados.
- Isso pode ser um passo importante para Inteligência Artificial Geral (AGI), onde os modelos de IA não apenas geram respostas, mas também avaliam se elas fazem sentido.
Essa imagem mostra que o DeepSeek-R1-Zero pode reconhecer erros e ajustar seu raciocínio autonomamente, sem intervenção humana. Isso representa um avanço significativo na forma como as IAs aprendem, permitindo que se tornem mais inteligentes, flexíveis e autônomas em problemas complexos.
O Reinforcement Learning explicado de forma simples!
Imagina que você está treinando para uma prova de matemática. Existem duas formas de aprender:
1. Método da OpenAI (com ajuda de professores)
- Você faz os exercícios e os professores corrigem, dizendo se sua resposta está certa ou errada.
- Eles também dão dicas sobre como melhorar, mas essas dicas podem depender da opinião de cada professor.
2. Método do DeepSeek-R1 (aprendendo sozinho com um sistema de pontos)
- Em vez de esperar um professor corrigir, você usa um sistema automático que verifica se a resposta está certa ou errada.
- Se estiver certa, ganha pontos. Se errar, perde pontos.
- O sistema também mostra onde você errou, ajudando você a aprender sem precisar de um professor humano.
Agora, por que isso é uma grande inovação?
O método da OpenAI, que usa aprendizado por reforço com feedback humano (RLHF), pode ser mais lento e caro, porque depende de pessoas corrigindo as respostas manualmente. Além disso, os professores podem ter opiniões diferentes sobre o que é certo ou errado, o que pode confundir o modelo.
Já o DeepSeek-R1 usa Recompensa de Precisão, um método automático e objetivo, onde as respostas certas são verificadas matematicamente. Isso significa que a IA aprende sem interferência humana, tornando o treinamento mais rápido, mais barato e sem erros de julgamento.
O DeepSeek-R1 aprende sozinho, como um aluno que usa um jogo de perguntas e respostas, enquanto a OpenAI precisa de professores humanos para corrigir suas respostas. Isso faz com que o DeepSeek-R1 aprenda de forma mais eficiente e com menos custos!
O Futuro da DeepSeek: Uma IA Verdadeiramente Autônoma?
O fato da DeepSeek-R1 conseguir corrigir seus próprios erros e refazer seus cálculos sem intervenção humana é um passo significativo para o desenvolvimento da Inteligência Artificial Geral (AGI). Isso significa que estamos caminhando para modelos que não apenas executam tarefas, mas refletem sobre seu próprio processo de pensamento.
A DeepSeek está liderando essa mudança com um modelo mais eficiente, acessível e inovador, abrindo portas para novas possibilidades no campo da inteligência artificial.
Gostou deste artigo. Veja outros relacionados:
DeepSeek para Empresas: Como Implementar IA de Código Aberto e Reduzir Custos
Curiosidades DeepSeek Liang Wenfeng
Opinião: Em Defesa de IAs Generativas Open Source – Questão de Soberania Digital para o Brasil
About author

Você pode gostar também

Descubra a importância do Python na cultura DevOps e na automatização
Automatização de Infraestrutura – DevOps e Python Hoje em dia os profissionais de TI estão olhando cada vez mais para DevOps e Python. Se você quer saber por que a

Engenheiro de Dados: a profissão essencial na era da informação
Profissões tendem a desaparecer e surgir com outras roupagens em um mundo onde a quantidade de conhecimento cresce exponencialmente. Embora esse fenômeno cause crises em algumas áreas, ele pode ser

Compartilhando conhecimento em IA – De ‘Pense por Mim’ a ‘Penso Menos’: O Custo do Atalho Cognitivo
Saudações, pessoal! ทดลองเล่นสล็อตราคาบอล Aqui estamos para mais uma edição da Newsletter da 4Linux, e hoje quero refletir com vocês sobre a extrema dependência de LLMs que vem sendo criada na sociedade,






