Desvendando o Machine Learning: entenda o que é e como funciona
Afinal, o que é Machine Learning ?
Atualmente, muito se discute sobre o aprendizado de máquina, Deep Learning e Inteligência Artificial, acredita-se que esses três termos são sinônimos, mas na verdade não é bem assim. Inteligência Artificial é um conceito amplo que inclui o aprendizado de máquina ou Machine Learning como um dos seus recursos, e o Deep Learning é uma subcategoria do Machine Learning.
Machine Learning é uma área da computação que estuda a implementação de algoritmos que aprendem a executar uma tarefa baseando-se nos dados disponibilizados. Primeiramente, ao utilizar o Machine Learning, o algoritmo utilizado cria um modelo matemático a partir das informações extraídas dos dados e então utiliza esse modelo para classificar novos dados. Existem diversos algoritmos capazes de realizar isto, mas atualmente o que mais se utiliza são as redes neurais.
Para melhor compreensão de onde é possível aplicar Machine Learning, será utilizado como exemplo um filtro de spam. Tradicionalmente, pode-se escrever um filtro de spam criando regras para identificar padrões que são comuns em e-mails de spam, como palavras específicas presentes no corpo, assunto e até mesmo no campo de remetente. Após a criação do filtro, geralmente realiza-se alguns testes para verificar se o funcionamento está ocorrendo conforme o esperado e caso não esteja, os erros devem ser analisados e as regras reescritas.
Veja que o parágrafo acima mostra um ciclo de um trabalho manual para que o filtro de spam possa entrar em produção. Porém, mesmo com o filtro funcionando corretamente e em produção, com o passar do tempo, podem surgir novos “padrões” de spam e com isso o ciclo deve se repetir, desde identificar os padrões até a execução dos testes.
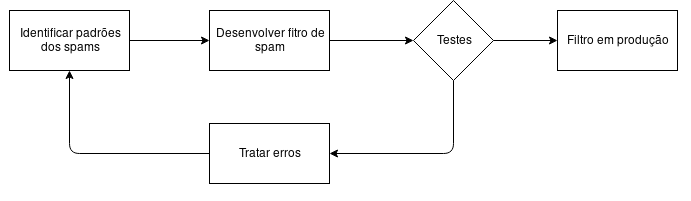
Ciclo de implementação manual do filtro de spam
Com este cenário, temos um trabalho manual que pode ser automatizado e ter até uma eficiência melhor se utilizarmos o Machine Learning.
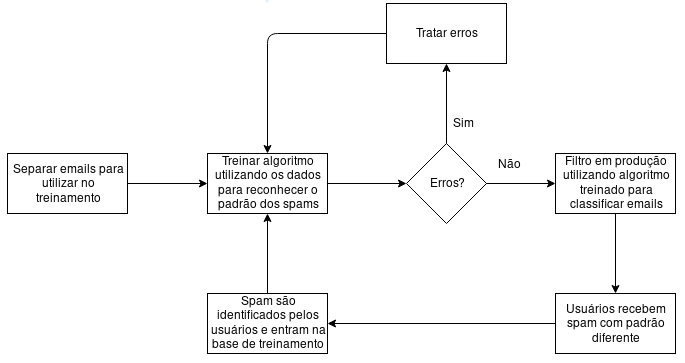
Utilizando um algoritmo de Machine Learning para classificar os e-mails
Mas como utilizar Machine Learning?
Há alguns tipos de sistemas de Machine Learning que são categorizados em tipo de treinamento, tipo de aprendizado e tipo de funcionamento. Essas categorias podem ser combinadas de acordo com a necessidade. São elas:
- Treinamento supervisionado, não supervisionado, semi-supervisionado ou aprendizado por reforço;
- Aprendizado incremental, conhecido como Learning-on-the-fly, ou aprendizado por lote, chamado também de batch learning;
- Funcionamento comparando dados conhecidos com novos dados ou detectar padrões nos dados conhecidos para criar um modelo preditivo.
Para melhor entendimento vamos explorar um pouco mais essas categorias:
Treinamento
Como supracitado, há quatro maneiras de realizar o aprendizado com Machine Learning. A definição principal no treinamento supervisionado é a “classificação“, onde rotula-se os dados antes do treinamento, criando classes para estes e assim garantindo a possibilidade de classificar novos dados. Por exemplo, se o objetivo de um trabalho é reconhecer tumores cerebrais em imagens de radiografia, antes do treinamento deve-se rotular as imagens que possuem e não possuem câncer, respectivamente como “positivo” e “negativo” e então com essas duas classes de dados, utilizando um algoritmo correto para lidar com imagens e realizar o treinamento supervisionado, é possível obter a classificação da presença de tumor cerebral em outras imagens.
O treinamento não-supervisionado é exatamente o oposto do supervisionado, pois não se informa para o algoritmo o que são os dados e assim fica como dever da máquina aprendê-los. A robótica tem um bom exemplo para esse tipo de treinamento – os robôs inteligentes que limpam a casa. Suponha que todo dia o robô encontre poeira de baixo da cama. Este tipo de dado vai fazer com que o robô entenda que todo dia vai ter sujeira de baixo da cama e por isso ele deve, todo dia, limpar a sujeira de baixo da cama.
O semi-supervisionado utiliza parte dos dados rotulados e como exemplo para este tipo de treinamento, temos as redes sociais que conseguem reconhecer usuários em fotos postadas na rede. Isso é possível porque quando um usuário Y posta uma foto com o usuário X, o algoritmo reconhece que a mesma pessoa está presente em algumas imagens, mas ainda não reconhece como usuário X. Então o usuário Y identifica o usuário X em algumas fotos e a partir deste ponto o algoritmo é capaz de reconhecer o usuário X.
Por último, temos o aprendizado por reforço que utiliza um sistema para que a máquina aprenda sozinha, mas com um fator de recompensa para cada tarefa executada. Assim, a máquina é capaz de aprender o que fazer em cada situação, ou seja, a máquina como um papel de agente realiza tarefas em um ambiente e aprende de acordo com sua política de recompensa.
Aprendizado
O aprendizado por lote utiliza dados disponíveis para o treinamento de forma offline e apenas entra em produção depois do treinamento estar completo. Se houver necessidade de atualizar os dados do sistema, o treinamento deve ser refeito do zero com os novos dados. Este tipo de aprendizado consome muito recurso computacional e também muito tempo para executar o treinamento devido aos lotes possuírem uma grande quantidade de dados, mas é recomendado para sistemas nos quais não há um fluxo contínuo ou o treinamento será executado uma vez só. Aqui se encaixa como exemplo o caso da detecção de tumores cerebrais em imagens.
No caso do aprendizado online, o sistema possui aprendizado incremental, ou seja, é possível adicionar novos dados para o treinamento enquanto o sistema opera, criando assim um aprendizado mais rápido e menos custoso computacionalmente. Esse tipo de aprendizado é recomendado para cenários que possuem um fluxo contínuo como o caso do filtro de spams, pois enquanto o sistema opera, se algum usuário receber um spam, basta sinalizar o email e o mesmo será reconhecido pelo sistema e incrementado nos dados disponíveis.
Funcionamento
Por fim, temos o tipo de funcionamento dos algoritmos. A ideia nesta etapa é generalizar as métricas para poder aplicar em novos dados. Primeiramente, abordando o método de comparação de dados conhecidos com dados desconhecidos, o sistema é capaz de medir a similaridade dos dados conhecidos com o dado desconhecido que deve ser classificado e desta forma o sistema generaliza para cada dado que aparecer para ser classificado.
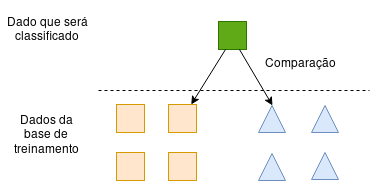
Ilustração para o método de comparação
Outra maneira de se generalizar a partir dos dados disponíveis é criar um modelo baseado nos dados utilizados para treinamento e utilizar este modelo para classificar novos dados. Por exemplo, se o objetivo de um trabalho é reconhecer gatos e cachorros, deve-se utilizar todo dataset de imagens separando gatos e cachorros. Com isso, durante o treinamento é criado um modelo para reconhecer ambos.
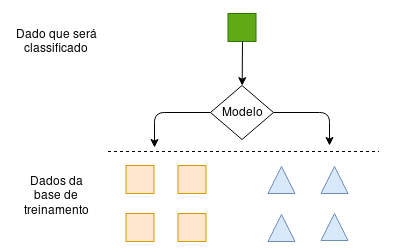
Ilustração para o método utilizando um modelo
Possíveis problemas ao trabalhar com Machine Learning
Pode haver problemas com os resultados do sistema caso a base utilizada para o treinamento seja pequena, tenha muito ruído ou até mesmo tenha sido construída de maneira incorreta. Além disso, por mais que a base esteja boa, também podem ocorrer erros durante o treinamento que alteram o resultado de forma significativa, como o overfitting e underfitting.
O overfitting acontece quando há muito ruído na base de treinamento, estes ruídos podem ocorrer por:
- Não realização de um pré-processamento ou não tratamento de dados antes do treinamento;
- O ruído estar sendo introduzido na amostragem porque a base utilizada para o treinamento é tão pequena que o aprendizado não consegue generalizar os padrões.
Para tratar o overfitting deve-se considerar como solução:
- Aumentar os dados da base de treinamento;
- Tratar os dados retirando ruído dos mesmos;
- Simplificar o modelo reduzindo o número de atributos ou parâmetros.
O underfitting é exatamente o oposto do overfitting. Geralmente acontece quando o modelo de aprendizagem é muito simples e não consegue capturar os padrões necessários para classificação da base de treinamento, não sendo possível também generalizar corretamente. Para tratar o underfitting, deve-se considerar um modelo com mais parâmetros e características dos dados que não foram consideradas anteriormente, e reduzir as restrições do modelo.
Considerações finais
Agora que vimos os conceitos de Machine Learning, é possível também entender melhor o termo Deep Learning. De maneira geral, é uma subcategoria do Machine Learning e trata o desenvolvimento de um sistema de Inteligência Artificial, possibilitando solucionar problemas e criar soluções inovadoras como reconhecimento de padrões em imagens, reconhecimento de fala e até auxiliar o ser humano na tomada de decisões em um problema com uma grande quantidade de dados.
Tudo depende da criatividade de quem estiver implementando um algoritmo para o aprendizado de máquina, pois há diversas soluções que foram desenvolvidas para áreas da saúde, química, entretenimento etc. A cada dia, aparecem mais soluções inovadoras capazes de mudar nossa realidade atual com melhorias na tecnologia com o uso de Machine Learning.
About author

Você pode gostar também

MySQL 805: Alta Performance e Alta Disponibilidade — Curso Atualizado para o MySQL 8.4 LTS
O curso MySQL 805 – Alta Performance e Alta Disponibilidade, da 4Linux, foi totalmente atualizado para acompanhar a evolução do MySQL e as demandas atuais do mercado. Criado originalmente em 2019,
Descubra por que o PHP é a linguagem ideal para desenvolvimento web
O PHP é uma linguagem orientada a objetos, server-side, interpretada, com tipagem dinâmica voltada para WEB. Outras linguagens para WEB que você pode ter ouvido falar são ASP, Python e

Como implementar e recuperar backups PITR no PostgreSQL
Neste artigo você aprenderá: como implementar um simples sistema de replicação através dos xlog. como recuperar o seu banco PostgreSQL em qualquer ponto no tempo. Sobre backups PITR Quando






