
Entenda a Alta Disponibilidade com Pacemaker e Corosync
Fugindo um pouco dos tópicos mais quentes como Cloud Pública, IaC, DevOps e SRE, hoje veremos alguns elementos que são usados como base de muitos serviços que utilizamos: Clusters. Entender sobre clusters é reconhecer quais elementos da nossa solução precisam ser definidos em Alta Disponibilidade (HA – High Availability) e como configurá-los para que, em caso de uma falha, da infraestrutura de rede ou da própria máquina física, possamos continuar fornecendo o serviço.
Hoje em dia se fala muito da utilização de tecnologias de containers para essa função, fazendo uso de orquestradores em cloud pública como EKS (AWS), GKS (GCP) ou AKS (Azure) ou até mesmo serviços como ECS Fargate e outros. Mas como empresas que não podem utilizar essas soluções ou até mesmo não se encaixam em uma infraestrutura de containers conseguiria alcançar Alta Disponibilidade de seus serviços em um ambiente on-premises (ambiente local)? É isso que iremos ver.
Para que serve uma solução de HA ?
Primeiramente precisamos entender o porque de estarmos necessitando de uma solução de Alta Disponibilidade. A resposta óbvia seria garantir que o serviços sempre permaneçam ativos, mas expandindo um pouco mais esse ponto o que queremos de fato é a redução do nosso tempo de indisponibilidade.
Mas como assim? Como nada na área de tecnologia é 100% confiável, serviços, appliances e servidores acabam sofrendo panes, falhas ou erros de operação gerando assim o famigerado downtime. Em nível de negócio e administração lidamos com isso usando elementos como SLA (Service Level Agreement), SLO (Service Level Objective) e SLI (Service Level Indicators), monitorando nosso estado atual e validando se está de acordo com os objetivos que desejamos alcançar para uma solução ou cliente, gerando por fim um acordo caso isso não sejá possível de alcançar. Nesse momento ambientes de HA entram como solução para reduzir esse downtime, permitindo uma plataforma/solução estar sempre em estado satisfatório para quem for utilizar.
Pacemaker e Corosync
Agora que já temos uma ideia do que exatamente e uma solução de HA e para que a utilizamos, iremos entender como na prática podemos utilizar o Pacemaker e Corosync para criar esse ambiente de alta disponibilidade.
Pacemaker e Corosync são soluções que trabalham juntas, enquanto um realiza o gerenciamento de recursos no cluster o outro irá fornecer uma camada abaixo de serviços para o funcionamento do cluster, como soluções de notificações e mensagens sobre alterações do ambiente, garantia de quorum e restart dos serviços com falha. Podemos definir, por tanto, que o Corosync serve como um framework para soluções de HA como Pacemaker.
Informações mais detalhadas sobre as features de cada um podem ser encontradas no sites abaixo:
- Corosync: https://corosync.github.io/corosync/
- ClusterLabs: https://clusterlabs.org/pacemaker
Laboratório de teste
Já entrando na parte prática iremos criar um ambiente virtual utilizando Vagrant e Virtualbox. Caso você não conheça essas soluções, basta acessar o posts abaixo para se familiarizar:
– Vagrant: Crie ambientes de Desenvolvimento Ágil – Alison Machado
– Virtualização com Vagrant – Júlio Ballot
– Provisionando sua infraestrutura com Vagrant-Shell – Gabriel Nascimento
Para esse ambiente iremos utilizar um conjunto de 3 maquinas virtuais rodando a box atual do Debian versão Buster (10). Crie uma pasta e dentro adicione o arquivo de nome Vagrantfile com o conteúdo abaixo:
</pre>
# -*- mode: ruby -*-
# vi: set ft=ruby :
##
## Quantidade de CPUs e Memoria para o ambiente
##
cpus=1
memory=512
##
## Lista de machinas do cluster
##
machines = {
"node01" => {"ip"=>"192.168.100.10"},
"node02" => {"ip"=>"192.168.100.11"},
"node03" => {"ip"=>"192.168.100.12"}
}
##
## Script para definir o hosts
##
$HOSTS = <<-SCRIPT
echo '
127.0.0.1 localhost
192.168.100.10 node01.example.org node01
192.168.100.11 node02.example.org node02
192.168.100.12 node03.example.org node03' > /etc/hosts
SCRIPT
Vagrant.configure("2") do |config|
config.vm.box = "debian/buster64"
machines.each do |name,conf|
config.vm.define "#{name}" do |machine|
machine.vm.network "private_network", ip: "#{conf["ip"]}"
machine.vm.hostname = "#{name}.example.org"
machine.vm.provider "virtualbox" do |vb|
vb.cpus = cpus
vb.memory = memory
vb.gui = false
end
# chamada do script para definir o /etc/hosts
machine.vm.provision "shell", inline: $HOSTS
end
end
end
Agora com tudo no lugar execute o comando vagrant up, de dentro deste diretório, aguarde alguns instantes e logo teremos acesso ao laboratório com as 3 máquinas prontas.
Cada máquina representa um nó genérico da rede, ainda sem qualquer serviços configurado ou cluster definido. A ideia aqui é configurar um serviço em cluster de modo que as 3 máquinas possam manter o serviço respondendo.
Instalação do Pacemaker e Corosync
Voltando para o seu terminal, assim que o vagrant up terminar de subir o ambiente, abra um terminal ou aba para cada máquina e acesse o node01, node02 e node03 utilizando o comando vagrant ssh node0X.
Como todo sistema Debian ou baseado em Debian iremos utilizar o gerenciador de pacotes APT para installar pacemaker, corosync e pcs. Esse último sendo o utilitário de configuração para o pacemaker.
root@node01:~# apt update root@node01:~# apt install pacemaker corosync pcs -y
Repita essa instalação para os demais nós. Assim que a instalação finalizar poderemos validar se o serviço está ativo com o comando systemctl status, nos seguintes alvos:
- pacemaker.service – Serviço do systemd para Pacemaker
- corosync.service – Serviço do systemd para o Corosync
- pcsd.service – Serviço do systemd para o PCS
Qualquer erro deve ser ignorado, ainda não configuramos o ambiente.
Criando cluster a adicionando nós
Com a instalação finalizada não somente os serviços foram adicionados mas também um usuário hacluster foi criado:

Esse usuário será utilizado para autenticação entre os nós durante os processo executados pelo Pacemaker/Corosync. Para alterar a senha basta executar o passwd hacluster e definir a nova senha, utilize algo simples incialmente. Esse processo deve ser repetido nas demais máquinas.
Agora que estamos com tudo alinha podemos criar nosso cluster, primeiro vamos verificar seu status:
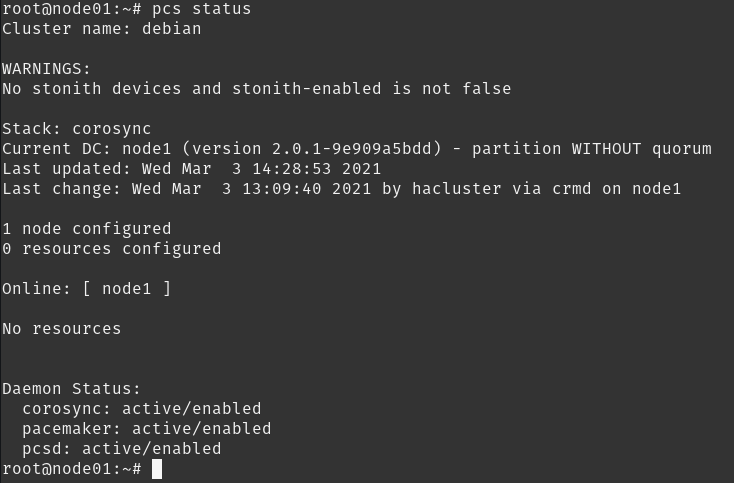
Ops… Aparentemente já temos um cluster criado. Mas como assim? No ambiente Debian e derivados o cluster já é criado, utilizando a máquina local, durante o processo de instalação. Como queremos criar nosso próprio cluster vamos removê-lo e criar um novo:
root@node01:~# pcs cluster destroy --all
Como resultado a mensagem Error: cluster is not currently running on this node deve ser apresentada. Caso o comando acima não funcione, basta limpar o arquivo de configuração do Corosync localizado no diretório /etc/corosync/corosync.conf. Não esquece de reiniciar o Corosync, mesmo que ele falhe por não ter uma configuração não precisaremos nos preocupar pois nos próximos passos já iremos criar o novo cluster.
Para criação do cluster precisamos autenticar todas as máquinas.
root@node01:~# pcs host auth node01 node02 node03 -u hacluster -p SUA_SENHA

Agora sim podemos criar o cluster. Node que estamos utilizando a opção –force que irá sobreescrever qualquer configuração de cluster das demais máquinas.
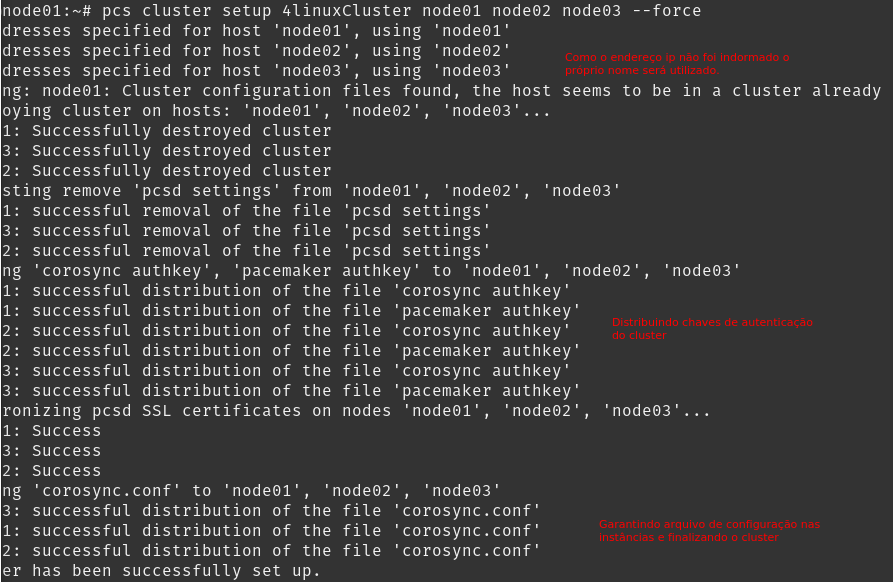
Nosso próximo passo será habilitar o cluster e iniciá-lo. Iremos utilizar o comando pcs cluster enable e pcs cluster start para isso:
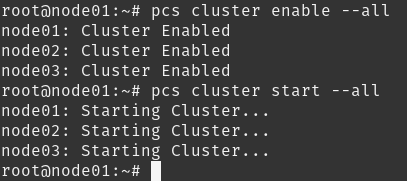
Com isso finalizamos nosso cluster, podemos agora verificar seu status em qualquer uma das máquinas.
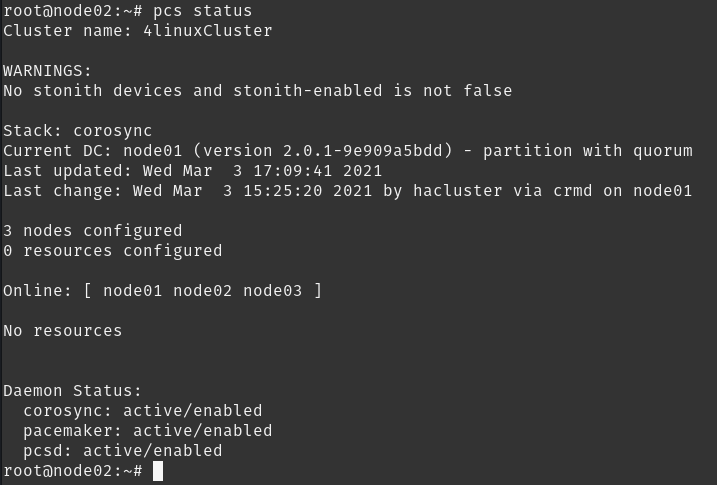
Nesse momento iremos começar a entender o que são os resources dentro do cluster, mas por agora iremos somente desativar o recurso de STONITH que explicaremos no decorrer do post.
root@node01:~# pcs property set stonith-enabled=false
Recursos do cluster
Dentro da arquitetura do Pacemaker/Corosync você terá a definição de resource e resource agents como sendo os serviços que o cluster está gerenciando e scripts extras que permitem ao cluster monitorar, interromper ou iniciar um resource dentro de um nó do ambiente.
Tais resource agents são separados por providers. Podemos visualizar tais elementos dentro do diretório /usr/lib/ocf/resource.d/:
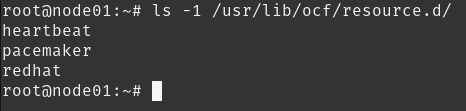
Portanto temos Heartbeat, Pacemaker e RedHat como provedores de resources agents. Em cada diretório encontraremos Shell Scripts que fazem o controle do resource, conforme mencionado anteriormente. Alguns exemplos:
- heartbeat/nginx
- heartbeat/LVM
- heartbeat/IPaddr2
- heartbeat/docker
- heartbeat/rabbitmq-cluster
- heartbeat/mariadb
- heartbeat/tomcat
- heartbeat/zabbixserver
Já podemos entender pelo próprio nome do script a qual serviço ele está relacionado, somente o IPaddr2 que necessita explicações. Esse resource agent é utilizado para gerenciar configurações de alias e endereços IPv4/IPv6. Existe um recurso similar, de nome IPaddr que funciona somente para IPv4.
Vamos começar com o exemplo mais banal de configuração e também um dos mais utilizados: Configuração de Floating IP para Web Server. Essa definição teremos um ip da nossa read “flutuando” entre as máquinas e o serviços do Nginx como um recurso em HA.
Criando resources
Para criarmos um resource é bem simples, precisaremos somente definir um nome o _resource agent_ e argumentos.
root@node01:~# pcs resource create IP_VIRTUAL ocf:heartbeat:IPaddr2 ip=192.168.100.200 cidr_netmask=24 op monitor interval=60s
Onde:
- IP_VIRTUAL: nome do _resource_
- ocf:heartbeat:IPaddr2: é o _resource agent_
- ip: definição do ip
- cidr_netmask: mascara de rede
- op monitor interval=60s: monitora o _resource_ a cada 60 segundos.
Assim que o recurso for criado, você poderá consultar o status do cluster e identificar onde o recurso está aplicado:
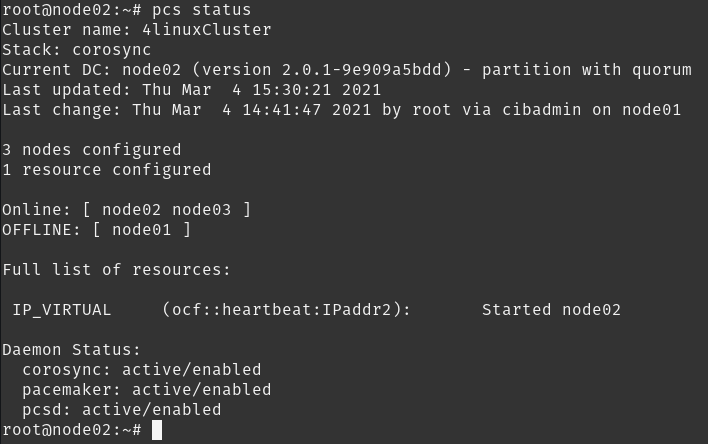
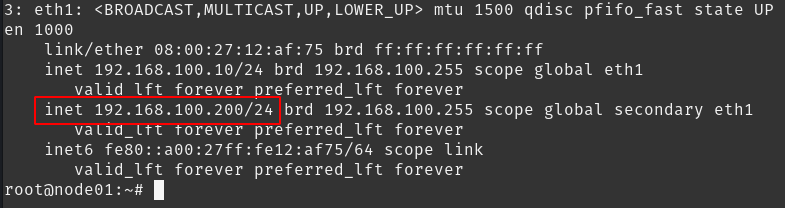
Listando as configurações de rede veremos que o ip 192.168.100.200 está configurado como alias na interface de rede correspondente a rede 192.168.100.0/24.
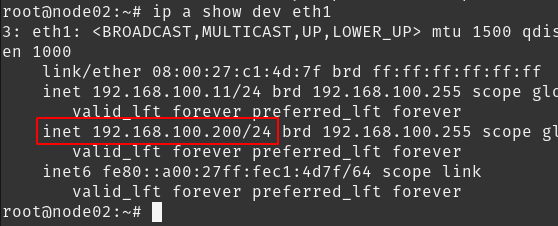
Se porventura essa máquina parar de responder ou o serviço nela ficar indisponível, o Pacemaker irá identificar e automaticamente migrar esse recurso para outro nó do cluster. Faça esse teste, de outro terminal ou deslogando na node01, execute o comando vagrant halt node01, assim que o nó for reconhecido como OFFLINE o failover ocorrer, ou seja, o IP é migrado para um dos nós restantes.
Validando na configuração da interface:
Desta maneira eu consigo acessar esse ip mesmo que os nós apresentem falhas, o que é útil se você tiver um serviço associado a esse elemento ou um serviço comum rodando entre os clusters. Por exemplo, você poderia instalar o WebServer Nginx em todas as máquinas e simplesmente ter o acesso a sua página por esse IP_VIRTUAL.
Em cada maquina realize a instalação do Nginx com comando apt install nginx -y e posteriormente defina uma página para cada servidor:
Node01 root@node01:~# echo "node01" &amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt; /var/www/html/index.html Node02 root@node02:~# echo "node02" &amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt; /var/www/html/index.html Node03 root@node03:~# echo "node03" &amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt; /var/www/html/index.html
Em seguida tente acessar do seu navegador o ip 192.168.100.200. Após o acesso desative o servidor que estiver com o IP_VIRTUAL rodando e tente acessar novamente o endereço.
Claro que isso é muito similar a uma solução de LoadBalance, que por si só é melhor do que trabalhar com um cluster tendo somente o resource do ip em HA. LoadBalancer conseguem trabalhar com algoritmos específicos para balancear seu acesso de acordo com sua necessidade, como por exemplo Round Robin, Weighted Round Robin, Source IP Hash, URL hash, Least Connections ou Sticky Session entre muitos outros que existem.
Quando criando ambientes de HA com Pacemaker procuramos por definir recursos que muitas vezes não podem possuir mais de uma instância caracterizando clusters com recursos configurados como Ativo/Passivo (active/passive) ou em outros casos quando a aplicação possui suporte para rodar múltiplas instâncias e portanto configuramos como recursos Ativo/Ativo (active/active). Nesse caso nosso IP_VIRTUAL é um exemplo de activo/passivo, não podemos ter esse mesmo ip na nossa rede definido em duas instâncias distintas, isso levaria a erros de conflito de endereço. Exemplos de active/active são alguns recursos relacionados a sistemas de arquivos de armazenamento compartilhado, como OCFS2 e GFS2.
Chegamos a fim da primeira parte, a base de conhecimento foi apresentada e já temos nosso primeiro exemplo de recurso em Alta Disponibilidade dentro de um cluster montado sobre a distribuição Debian Buster, utilizando o Pacemaker e Corosync. Na próxima parte entraremos em mais detalhes sobre a utilização , utilitários e a criação de mais recursos.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
CURSOSCONSULTORIAสล็อต88สล็อตเว็บตรงหนังออนไลน์ 24ทดลองเล่นสล็อต pgสล็อต88ทดลองเล่นสล็อต
About author

Você pode gostar também

Descubra as vantagens do MongoDB para o desenvolvimento Web
Bancos de dados são a base dos projetos de desenvolvimento Web. Muitos desenvolvedores estão voltando sua atenção para o MongoDB, um banco de dados sem esquema que é popular para uma

Guia passo a passo para configurar um ReplicatSet no MongoDB
O MongoDB é um banco com foco em escalabilidade horizontal, sendo assim ele possui um recurso chamado ReplicatSet que serve para replicar os dados em um cluster de servidores para

Prometheus: A revolução do monitoramento open source em TI
Conheça o Prometheus, ferramenta open source de monitoramento adaptada ao atual modelo de TI focada em serviços e opção aos tradicionais Zabbix/Nagios.






