
Entenda o Snapshot: a ferramenta de backup que não para seu serviço
Atualmente, o termo snapshot tem se popularizado por sua utilidade nas mais variadas Clouds. Este snapshot em questão funciona na sua casa, na sua infraestrutura local e até mesmo na Cloud. Me refiro aos snapshots de LVM, termo recentemente abordado em uma postagem e espero que agora todos estejam habituados com o que é LVM e como usá-lo.
Snapshots são muito úteis para criar backups de coisas que não podem parar e é essa a característica que será abordada aqui.
O que é snapshot?
Snapshot também pode ser traduzido como “instantâneo de disco” e, apesar deste nome ser um pouco estranho, ele descreve bem o resultado, pois realmente criamos um “disco instantâneo”.
Um snapshot nada mais é do que uma foto. Uma foto é a definição de um todo em um determinado momento do tempo, ela não muda.
Para fazer snapshots é necessário utilizar alguma tecnologia que possua controle sobre o sistema de arquivos ou o próprio sistema de arquivos. Alguns sistemas de arquivos, como BTRFS e ZFS, suportam snapshots nativamente, mas normalmente não utilizamos estes sistemas de arquivos no Linux. O BTRFS vem sendo utilizado pela SUSE e o ZFS pertence mais à família do BSD do que à do Linux.
Sabemos que no Linux os dois grandes sistemas de arquivos são EXT4 e XFS, mas não fique triste, podemos contornar esta baixa com LVM.
Os snapshots do LVM são feitos através dos volumes lógicos. Os dados que pretendemos “tirar uma foto” precisam estar em um volume lógico, assim como o nosso próprio snapshot resultante do processo. No LVM, o snapshot nada mais é do que uma outra partição criada através de um comando especial.
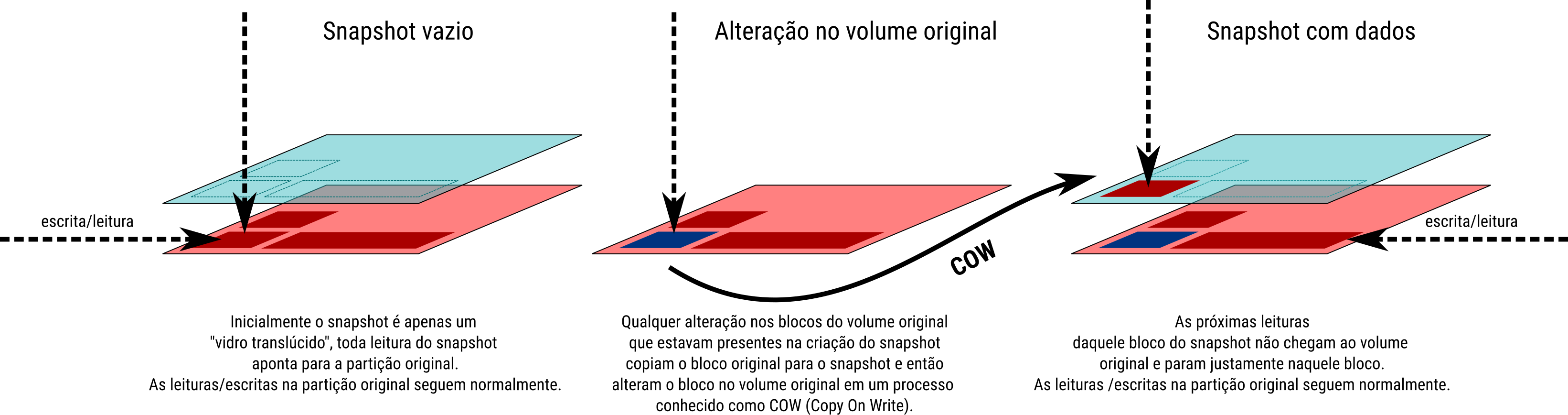
A partir do momento em que criamos o snapshot, o volume original passa a se comportar de uma maneira interessante:
- O volume passa a “monitorar” suas alterações;
- O bloco da partição a ser alterado é primeiramente copiado para o snapshot onde está a salvo;
- O bloco original então é alterado;
- Novas alterações no mesmo bloco não disparam mais o mecanismo anterior.
Dentro do volume de snapshot ficam apenas os blocos dos arquivos alterados e nada mais, isso significa que nosso snapshot tem tamanho dinâmico e é tão grande quanto todas as alterações que afetaram o bloco original:
- As leituras dos blocos presentes no snapshot retornam os dados do momento em que o snapshot foi criado;
- As leituras dos blocos que não foram alterados atravessam o snapshot e acessam o volume original de forma transparente;
- As escritas no snapshot acontecem normalmente e não afetam a partição original (normalmente não faremos isso).
Eu costumo explicar que o snapshot é como um vidro translúcido:
Como o snapshot acontece de forma instantânea, todo o estado da partição é salvo, isso inclui o estado exato da escrita de um banco de dados, incluindo a sua inconsistência.
Para os bancos de dados, é interessante que o log transacional esteja na mesma partição que os dados, para assim evitar operações mais complexas.
Para o MongoDB, após o snapshot ser restaurado, qualquer inconsistência será corrigida pelo WiredTiger automaticamente através do journal. Esta é a única forma de fazer um “hot-backup” no MongoDB Community.
Já o MySQL consegue restaurar seu estado através dos arquivos ib_logfile0 e ib_logfile1, que nada mais são do que os logs transacionais.
O Postgres, por sua vez, fará essa restauração através dos WAL files: seus próprios logs transacionais.
- Colocar o banco em estado de leitura;
- Forçar o descarregamento do buffer de memória no disco;
- Criar o snapshot (a operação menos demorada).
Neste caso, o snapshot já estará consistente, pois nenhuma escrita, commit ou rollback ficou pela metade.
Como fazer o snapshot
Neste exemplo utilizarei um MySQL 8.0.26, mas esta operação pode ser feita em praticamente qualquer versão do MySQL 8, do Postgres ou do MongoDB maior que 3.2 utilizando WiredTiger.
Também é possível utilizar versões menores do que MySQL 8, mas é necessário ter um certo cuidado com as operações DDL, pois elas não são transacionais e correm um pequeno risco de acontecerem no instante exato do snapshot, corrompendo o resultado.
Abaixo tenho um MySQL com seus dados dentro de um volume lógico do LVM montado no diretório padrão, este é o primeiro passo:
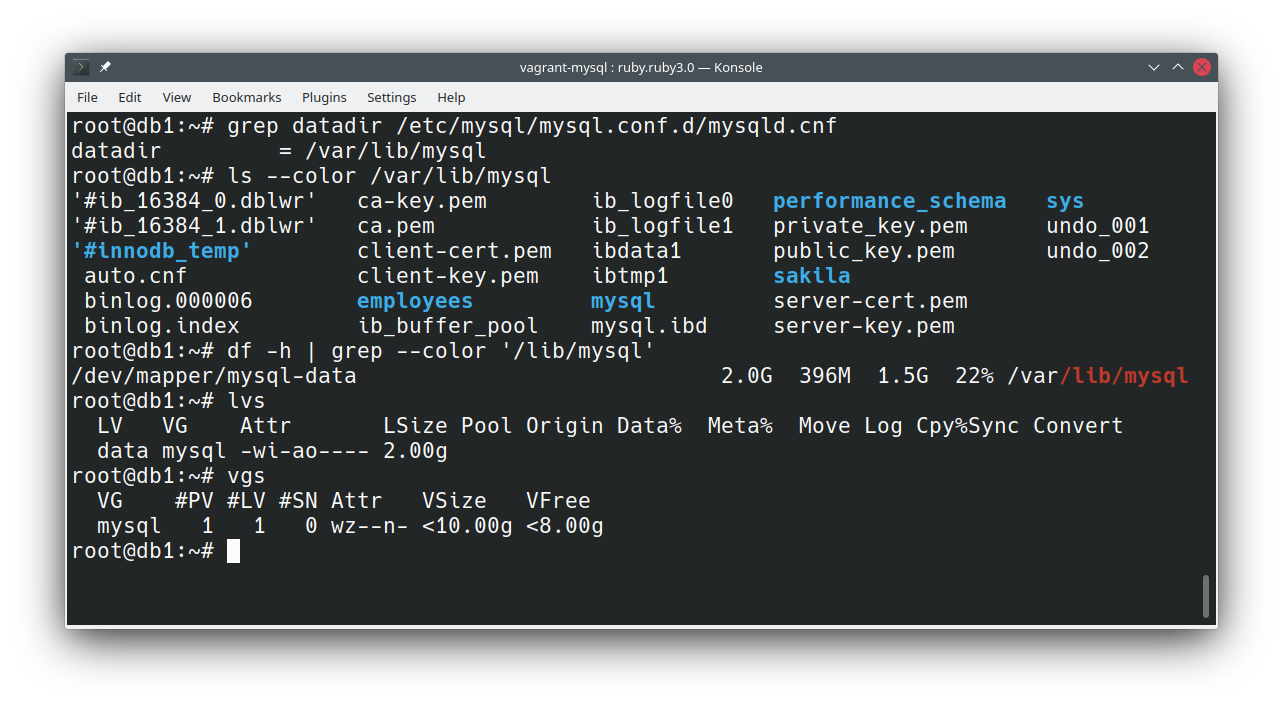
Em teoria, já estamos prontos. Temos nosso banco dentro de um LVM e temos espaço dentro do grupo.
Vou deixar um script rodando para simular a escrita das aplicações, algo parecido com o que mostrei em aprenda a gerar dados aleatórios:
#!/bin/bash
function _insert {
TEXTO=$(tr -dc [:alpha:] < /dev/urandom | head -c 10)
NUMERO=$(tr -dc [:digit:] < /dev/urandom | head -c 5)
mysql pseudo -e "INSERT INTO aleatorio (numero, texto) VALUES ($NUMERO, '$TEXTO')"
}
for X in {1..999999}; do
_insert &
if [ $(($X % 10)) == 0 ]; then
wait
fi
done
waitÉ possível constatar que as inserções estão acontecendo: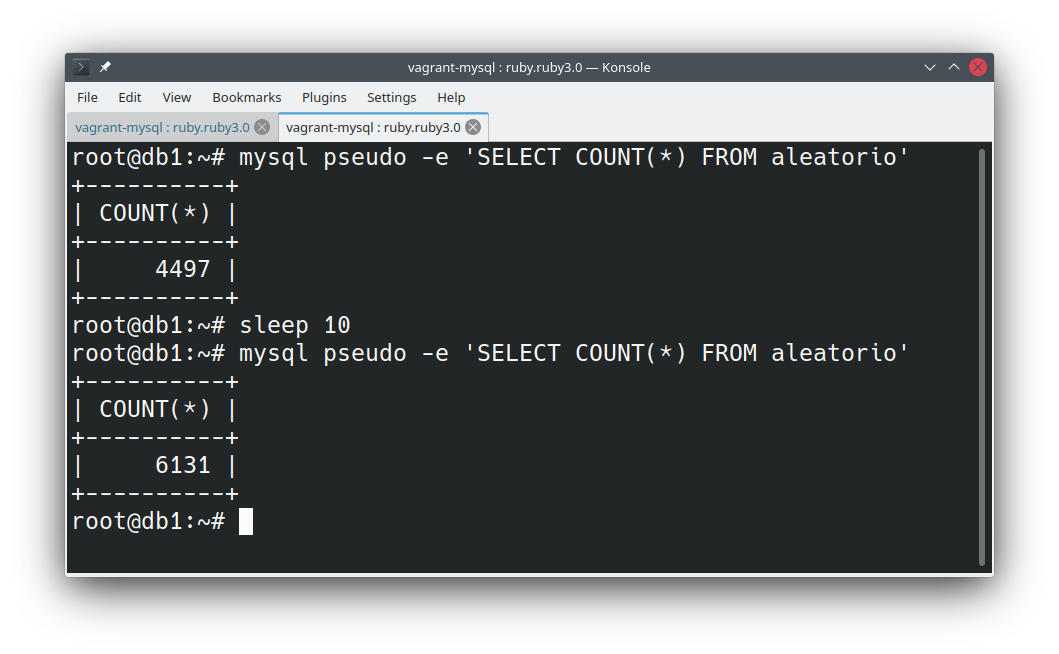 Com o banco operando normalmente, vou extrair o snapshot com apenas um comando:
Com o banco operando normalmente, vou extrair o snapshot com apenas um comando:
lvcreate --snapshot --name snap --size 512M /dev/mysql/data
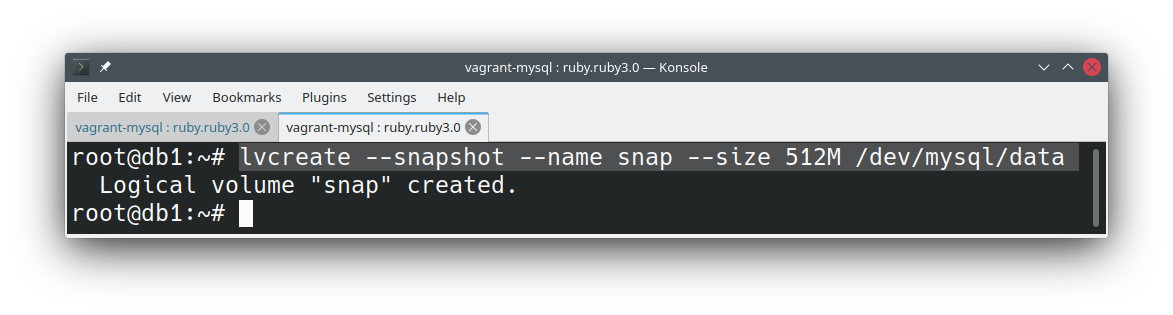
Simples assim, não é? Teoricamente, já temos o nosso backup.
O tamanho parece pequeno, mas os snapshots são criados vazios e são alimentados conforme os blocos são alterados na partição original. Isso significa que teremos uma janela para mexer com o snapshot tão grande quanto o tamanho especificado para comportar alterações.
Não há problemas em criar snapshots grandes, na dúvida, sempre utilize mais espaço.
Para visualizar o espaço restante no snapshot podemos utilizar o comando lvs:
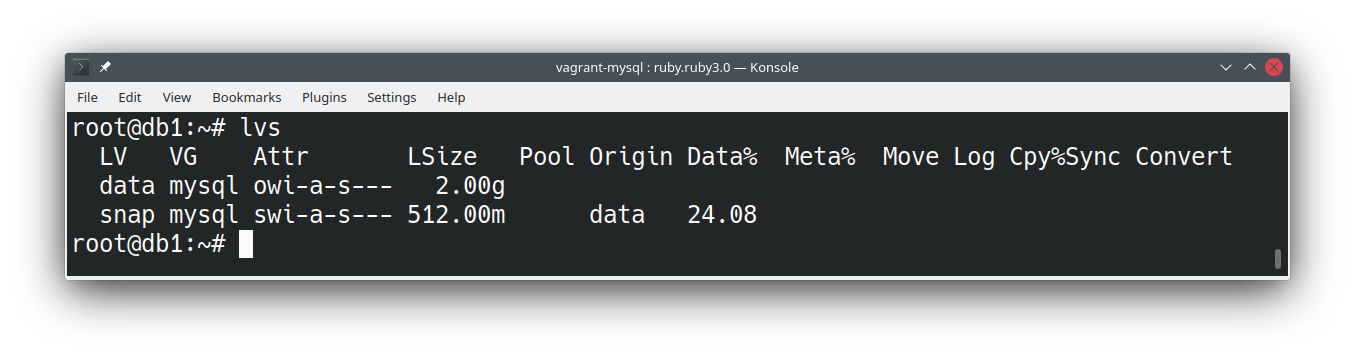
Com o snapshot pronto, podemos montá-lo em uma partição e trabalhar com os dados naquela partição. Lembre-se que estes dados são o estado do banco no momento em que o snapshot foi criado e não os dados presentes em /var/lib/mysql, pois a esta altura eles já estão diferentes.
Na imagem abaixo criamos uma base, montamos o snapshot e comparamos o conteúdo dos diretórios:
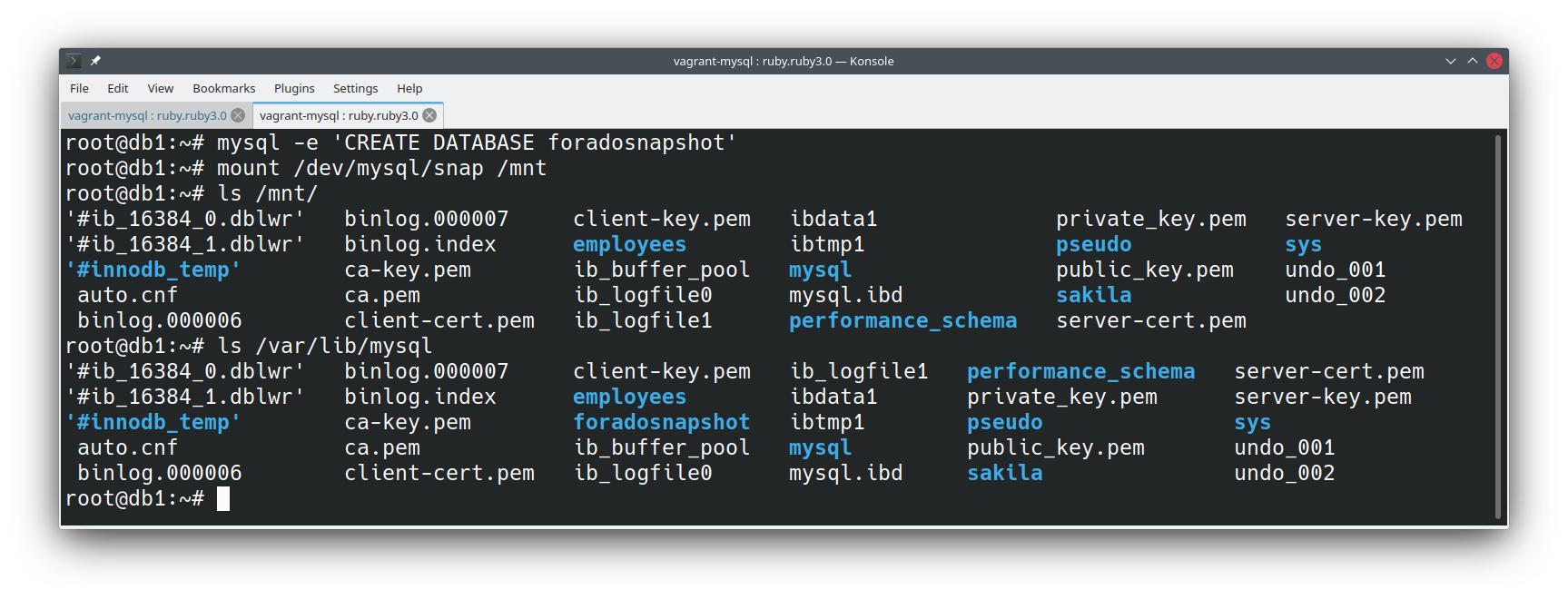
Veja que no diretório /var/lib/mysql existe a base foradosnapshot que criei anteriormente, mas o mesmo diretório não aparece dentro do /mnt, onde está no snapshot.
Agora que nosso snapshot está pronto, podemos copiar os arquivos na partição /mnt para qualquer outra máquina através de rsync e iniciar uma nova instância para criar replicação ou mesmo extrair a partição toda como um grande gzip e salvar em algum storage:
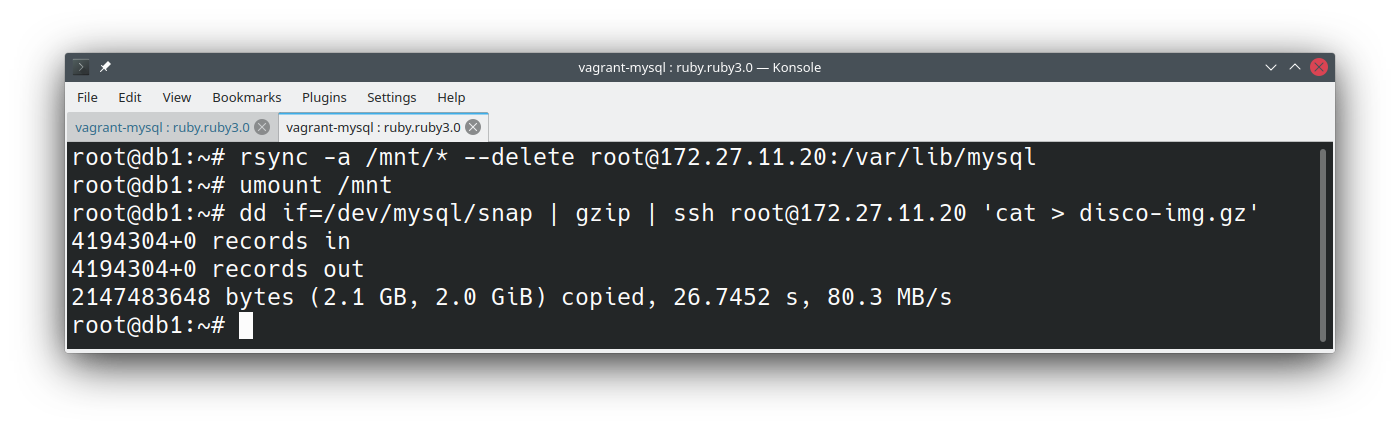
Normalmente utilizamos o rsync quando temos a intenção de iniciar uma réplica ou nos recuperarmos de alguma crise, pois os arquivos são copiados diretamente e estarão prontos para uso.
Utilizando o dd podemos compactar a partição inteira com qualquer ferramenta (gzip, bzip2, xz) e guardar o resultado em algum lugar. O tamanho final não será o tamanho total do disco, pois os espaços em branco são ignorados. Normalmente guardamos os arquivos compactados em algum storage.
Assim que terminarmos de operar com o snapshot, podemos simplesmente removê-lo com um comando lvremove e tudo voltará ao normal.
Conclusão
Utilizar snapshots facilita operações de backup, restauração e qualquer outro tipo de cópia de arquivos originais sem a necessidade de parar o serviço durante a operação.
Como o snapshot é fornecido pelo próprio LVM, podemos utilizá-lo em qualquer tipo de infraestrutura.
É necessário se atentar às peculiaridades de cada cenário, como: utilizar diferentes engines no MySQL ou diferentes partições no MongoDB.
A ativação do snapshot cria um pequeno stress no servidor, então é necessário atentar-se a gargalos de disco e qualquer outro comportamento inesperado quando a máquina estiver operando perto do limite.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Garantindo Alta Disponibilidade no Redis com Redis Sentinel
O Redis, como já conhecemos, é um banco de dados em memória responsável pelo caching. No entanto, por se tratar de um banco de dados, ele também oferece suporte à
Graylog – Gerenciando todos os seus Logs
Este post tem como objetivo apresentar um guia para instalação e configuração do Graylog em Debian 8 (Jessie), suportado pelos bancos de dados noSQL MongoDB e ElasticSearch e com alta

Descubra o Opensearch: a ferramenta opensource para análise de logs e monitoramento
Heeey! Podemos nos referir ao Opensearch como um fork do Elasticsearch e Kibana 7.10. Basicamente, o Opensearch é uma ferramente de monitoração de aplicação e análise de logs totalmente opensource





