
Guia sobre como criar um cluster com o centralizador de logs Graylog 3.3
O Graylog [1] é uma ferramenta open source e serve para monitorar, centralizar e organizar mensagens de log em sua infraestrutura. É uma alternativa ao famoso ELK. O Graylog oferece vários recursos que facilitam toda a parte de extração e análise de logs. Possui uma interface web e utiliza tecnologias como MongoDB [3] e Elasticsearch [4].
Na documentação do Graylog essa configuração, que iremos fazer neste artigo, se chama Multi-node Setup [5]. Utilizaremos três servidores com Graylog e MongoDB, três servidores com Elasticsearch e um servidor com HAProxy.
Para ter uma ideia, nossa arquitetura ficará desta forma:
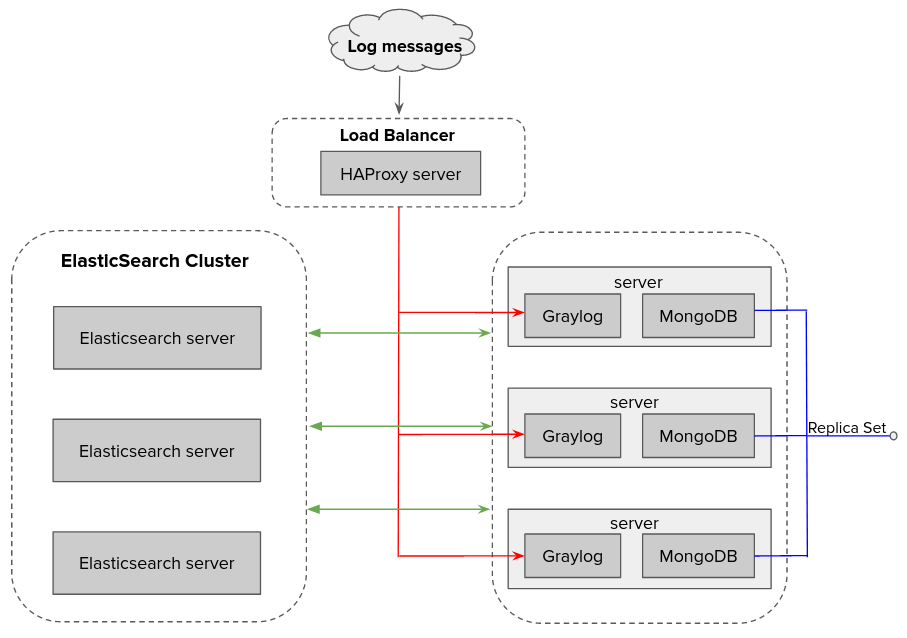
Os servidores foram criados com a distribuição CentOS 7. Logo, caso queira realizar os procedimentos em outra distribuição, terá que rever os processos de instalação. Vamos lá 😉
Elasticsearch
O Elasticsearch é o mecanismo de busca e análise de dados que o Graylog utiliza para indexar os logs recebidos.
Instalação
O Graylog suporta até no máximo a versão 6.x do Elasticsearch. Um pré-requisito para todos servidores é o Java. Então vamos começar por ele:
# yum update && yum -y install java-1.8.0-openjdk-headless.x86_64Para a instalação do Elasticsearch, vamos importar a Elastic GPG key:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchE adicione o arquivo elasticsearch.repo no diretório /etc/yum.repos.d/:
# vim elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/oss-6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
Após isso basta instalar:
# yum install elasticsearch-ossConfiguração
Nos servidores utilizados neste artigo, foram disponibilizados o mínimo de RAM (1Gb), desta forma foi necessário modificar algumas opções do Java, limitando seu uso de memória. Caso você tenha mais do que 1Gb para seus servidores, não precisará passar por esta etapa.
Altere as linhas:
# vim /etc/elasticsearch/jvm.options
-Xms512m
-Xmx512m
Edite o arquivo de configuração:
# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: graylog
node.name: ${HOSTNAME}
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["elastic1.lab", "elastic2.lab", "elastic3.lab"]Para melhorar a identificação dos servidores, configurei o DNS no /etc/hosts. Feito isso, basta configurar basta iniciar o serviço:
# systemctl daemon-reload
# systemctl enable elasticsearch.service
# systemctl restart elasticsearch.service
Você poderá checar o status do Elasticsearch através do curl:
# curl http://elastic1.lab:9200
$ curl http://elastic1.lab:9200
{
"name" : "elastic1",
"cluster_name" : "graylog",
"cluster_uuid" : "qMtqk9hUTcm9gT8a6wF7-w",
"version" : {
"number" : "6.8.12",
"build_flavor" : "oss",
"build_type" : "rpm",
"build_hash" : "7a15d2a",
"build_date" : "2020-08-12T07:27:20.804867Z",
"build_snapshot" : false,
"lucene_version" : "7.7.3",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
No meu caso não foi de primeira, por um bloqueio do SELinux. Então caso não consiga, verifique se o SELinux ou o firewall está bloqueando a conexão.
Você pode apenas desabilitar o firewall ou deixá-lo ativo e liberar a conexão do Elasticsearch.
Para desabilitar basta executar o comando:
# systemctl disable firewalldApós replicar esses processos nos outros dois servidores, o cluster do Elasticsearch estará pronto!
MongoDB
Agora vamos configurar três servidores com MongoDB e Graylog, então recomendo no mínimo 2Gb de RAM.
O MongoDB é um serviço de banco de dados NoSQL que o Graylog utiliza para armazenar os dados de configuração e autenticação.
Instalação
Crie um arquivo mongodb-org-4.4.repo no diretório /etc/yum.repos.d/.
# vim mongodb-org-4.4.repo
[mongodb-org-4.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc
Após isso basta instalar:
# yum update && yum install -y mongodb-orgConfiguração
Crie os diretórios:
# mkdir -p /var/lib/mongo
# mkdir -p /var/log/mongodb
# mkdir -p /data/db
Configure as permissões do usuário mongod:
# chown -R mongod:mongod /var/lib/mongo
# chown -R mongod:mongod /var/log/mongodb
Na documentação do MongoDB, existe uma seção para configurar a política do SELinux para que permita os acessos. Caso sua distribuição não use SELinux, pode pular essa etapa.
# yum install checkpolicy policycoreutils-python
# cat > mongodb_cgroup_memory.te <<EOF
module mongodb_cgroup_memory 1.0;
require {
type cgroup_t;
type mongod_t;
class dir search;
class file { getattr open read };
}
#============= mongod_t ==============
allow mongod_t cgroup_t:dir search;
allow mongod_t cgroup_t:file { getattr open read };
EOF
$ checkmodule -M -m -o mongodb_cgroup_memory.mod mongodb_cgroup_memory.te
$ semodule_package -o mongodb_cgroup_memory.pp -m mongodb_cgroup_memory.mod
$ semodule -i mongodb_cgroup_memory.pp
Após configurar basta iniciar o serviço:
# systemctl daemon-reload
# systemctl enable mongod
# systemctl start mongod
Você consegue testar a conexão executando o comando:
# mongoCaso seja exibida alguma falha, verifique o firewall. Para a configuração das réplicas do MongoDB basta executar (antes é preciso parar a instância do mongod que está em execução):
$mongod --replSet "rs0" --bind_ip localhost,mongodb1.lab --fork --logpath /var/log/mongodb/mongodSobre esta linha de comando:
- Mude mongodb1.lab para o endereço do servidor
- O parâmetro –fork é para que o processo seja executado em segundo plano
- O parâmetro –replSet servirá para inserir o nome da configuração de replicação
Após fazer esses procedimentos nos três servidores, defina apenas um e o conecte ao mongo shell:
$ mongo
Inicialize a configuração da réplica:
# rs.initiate( {
_id : "rs0",
members: [
{ _id: 0, host: "mongodb1.devops.lab:27017" },
{ _id: 1, host: "mongodb2.devops.lab:27017" },
{ _id: 2, host: "mongodb3.devops.lab:27017" }
]
})
você consegue verificar a configuração em execução:
# rs.status()
a saída deve estar mais ou menos desta forma:
rs0:PRIMARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2020-10-07T04:23:25.190Z"),
"myState" : 1,
"term" : NumberLong(12),
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"majorityVoteCount" : 2,
"writeMajorityCount" : 2,
"votingMembersCount" : 3,
"writableVotingMembersCount" : 3,
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1602044601, 9),
"t" : NumberLong(12)
},
"lastCommittedWallTime" : ISODate("2020-10-07T04:23:21.627Z"),
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1602044601, 9),
"t" : NumberLong(12)
},
"readConcernMajorityWallTime" : ISODate("2020-10-07T04:23:21.627Z"),
"appliedOpTime" : {
"ts" : Timestamp(1602044604, 11),
"t" : NumberLong(12)
},
"durableOpTime" : {
"ts" : Timestamp(1602044602, 11),
"t" : NumberLong(12)
},
"lastAppliedWallTime" : ISODate("2020-10-07T04:23:24.975Z"),
"lastDurableWallTime" : ISODate("2020-10-07T04:23:22.958Z")
},
"lastStableRecoveryTimestamp" : Timestamp(1602044492, 7),
"electionCandidateMetrics" : {
"lastElectionReason" : "electionTimeout",
"lastElectionDate" : ISODate("2020-10-07T04:19:54.787Z"),
"electionTerm" : NumberLong(12),
"lastCommittedOpTimeAtElection" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"lastSeenOpTimeAtElection" : {
"ts" : Timestamp(1601673721, 7),
"t" : NumberLong(11)
},
"numVotesNeeded" : 2,
"priorityAtElection" : 1,
"electionTimeoutMillis" : NumberLong(10000),
"numCatchUpOps" : NumberLong(0),
"newTermStartDate" : ISODate("2020-10-07T04:19:55.550Z"),
"wMajorityWriteAvailabilityDate" : ISODate("2020-10-07T04:19:56.455Z")
},
"members" : [
{
"_id" : 0,
"name" : "mongodb1.devops.lab:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 424,
"optime" : {
"ts" : Timestamp(1602044604, 11),
"t" : NumberLong(12)
},
"optimeDate" : ISODate("2020-10-07T04:23:24Z"),
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"electionTime" : Timestamp(1602044395, 1),
"electionDate" : ISODate("2020-10-07T04:19:55Z"),
"configVersion" : 1,
"configTerm" : 12,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "mongodb2.devops.lab:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 219,
"optime" : {
"ts" : Timestamp(1602044604, 6),
"t" : NumberLong(12)
},
"optimeDurable" : {
"ts" : Timestamp(1602044601, 9),
"t" : NumberLong(12)
},
"optimeDate" : ISODate("2020-10-07T04:23:24Z"),
"optimeDurableDate" : ISODate("2020-10-07T04:23:21Z"),
"lastHeartbeat" : ISODate("2020-10-07T04:23:24.801Z"),
"lastHeartbeatRecv" : ISODate("2020-10-07T04:23:25.012Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncSourceHost" : "mongodb1.devops.lab:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 1,
"configTerm" : 12
},
{
"_id" : 2,
"name" : "mongodb3.devops.lab:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 212,
"optime" : {
"ts" : Timestamp(1602044604, 6),
"t" : NumberLong(12)
},
"optimeDurable" : {
"ts" : Timestamp(1602044601, 5),
"t" : NumberLong(12)
},
"optimeDate" : ISODate("2020-10-07T04:23:24Z"),
"optimeDurableDate" : ISODate("2020-10-07T04:23:21Z"),
"lastHeartbeat" : ISODate("2020-10-07T04:23:24.801Z"),
"lastHeartbeatRecv" : ISODate("2020-10-07T04:23:25.031Z"),
"pingMs" : NumberLong(1),
"lastHeartbeatMessage" : "",
"syncSourceHost" : "mongodb1.devops.lab:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 1,
"configTerm" : 12
}
],
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1602044604, 11),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1602044604, 11)
}
Crie um banco de dados e um usuário para o Graylog:
# use graylog;
# db.createUser( { user: "mongo_admin", pwd: "graylog", roles: [ { role: "root", db: "admin" } ] } )
Certo, com o Elasticsearch e o MongoDB configurados, vamos para o Graylog!
Graylog
Instalação
# rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-3.3-repository_latest.rpm
# yum update && yum -y install java-1.8.0-openjdk-headless.x86_64 graylog-server
Configuração
Você também consegue alterar o uso de memória do Java, no arquivo de configuração dessas opções que fica em /etc/sysconfig/graylog-server.
Antes de editar o arquivo de configuração, será preciso gerar duas senhas.
Para gerar a password_secret basta executar o comando:
# pwgen -N 1 -s 96
Caso não tenha o pwgen instalado basta seguir esses passos:
# yum install epel-release
# yum install pwgen
Para gerar a root_password_sha2, execute esse comando:
# echo -n "Enter Password: " && head -1 </dev/stdin | tr -d '\n' | sha256sum | cut -d" " -f1
Após isso, edite o arquivo de configuração:
$ vim /etc/graylog/server/server.conf
is_master = true
password_secret = [gerada anteriormente]
root_password_sha2 = [gerada anteriormente]
root_timezone = America/Sao_Paulo
http_bind_address = graylog1.lab:9000
http_publish_uri = http://graylog.1.lab:9000/
elasticsearch_hosts = http://elastic1.lab:9200,http://elastic2.lab:9200,http://elastic3.lab:9200
elasticsearch_shards = 3
mongodb_uri = mongodb://mongo_admin:graylog@mongodb1.lab:27017,mongodb2.lab:27017,mongodb3.lab:27017/graylog?replicaSet=rs0
Observações
- Apenas deixe is_master = true em um dos servidores
- Modifique web.graylog1 para o endereço do servidor
- Modifique a linha elasticsearch_hosts com os endereços dos servidores do Elasticsearch
- Modifique a linha mongodb_uricom os endereços dos servidores do MongoDB
Agora basta iniciar o servidor do Graylog:
# systemctl daemon-reload
# systemctl enable graylog-server
# systemctl start graylog-server
Após alguns minutos você poderá acessar o endereço do graylog em http://graylog1.lab:9000/. O login é admin e a senha é a que você inseriu no campo root_password_sha2.
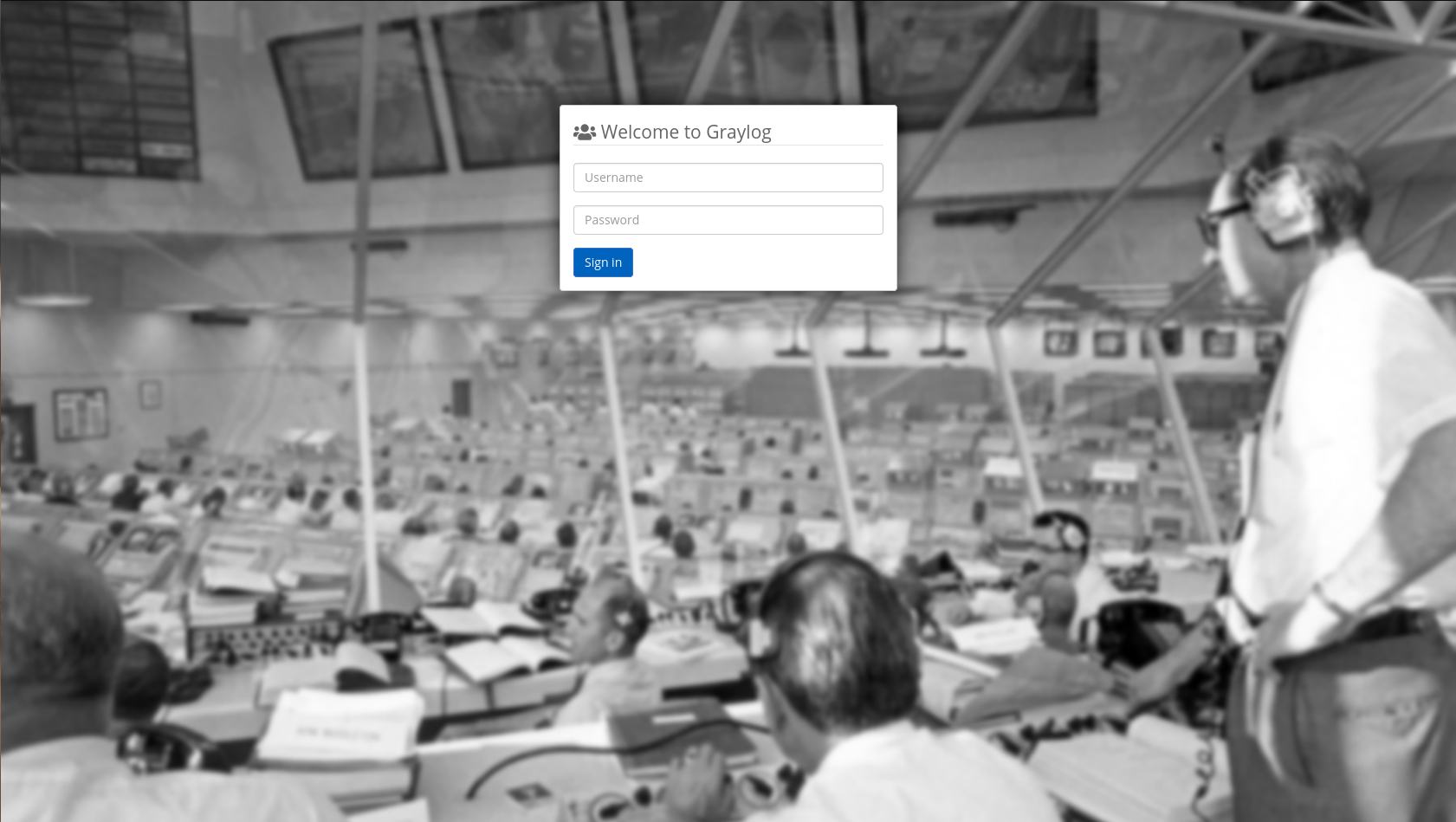
Importante: quando lidamos com clusters é muito importante que todos os servidores estejam com o mesmo horário pois a divergência pode gerar erros no Graylog.
HAProxy
O HAProxy vai servir como um balanceador de carga para a configuração das réplicas do Mongo no cluster Beats. Isso quer dizer que ao configurar o envio de logs, nós iremos mandar para o endereço do servidor onde está o HAProxy e ele é quem vai ser o responsável por enviar os dados para os servidores do Graylog.
Instalação
# yum update && yum install haproxy
Configuração
Edite o arquivo de configuração e insira os blocos:
$ vim /etc/haproxy/haproxy.cfg
listen stats
bind :32700
stats enable
stats uri /
stats hide-version
stats auth devops:devopslab
listen syslog_1514
bind *:1514
mode tcp
option tcplog
timeout client 120s
timeout server 120s
default-server inter 2s downinter 5s rise 3 fall 2 maxconn 64 maxqueue 128 weight 100
server graylog1 graylog1.lab:1514 check
server graylog2 graylog2.lab:1514 check
server graylog3 graylog3.lab:1514 check
O primeiro bloco é para a página de estatísticas que o HAProxy exibe. Ao acessá-la será possível ver o balanceamento de dados entres os servidores do graylog. Basta acessar o endereço do servidor na porta 32700:
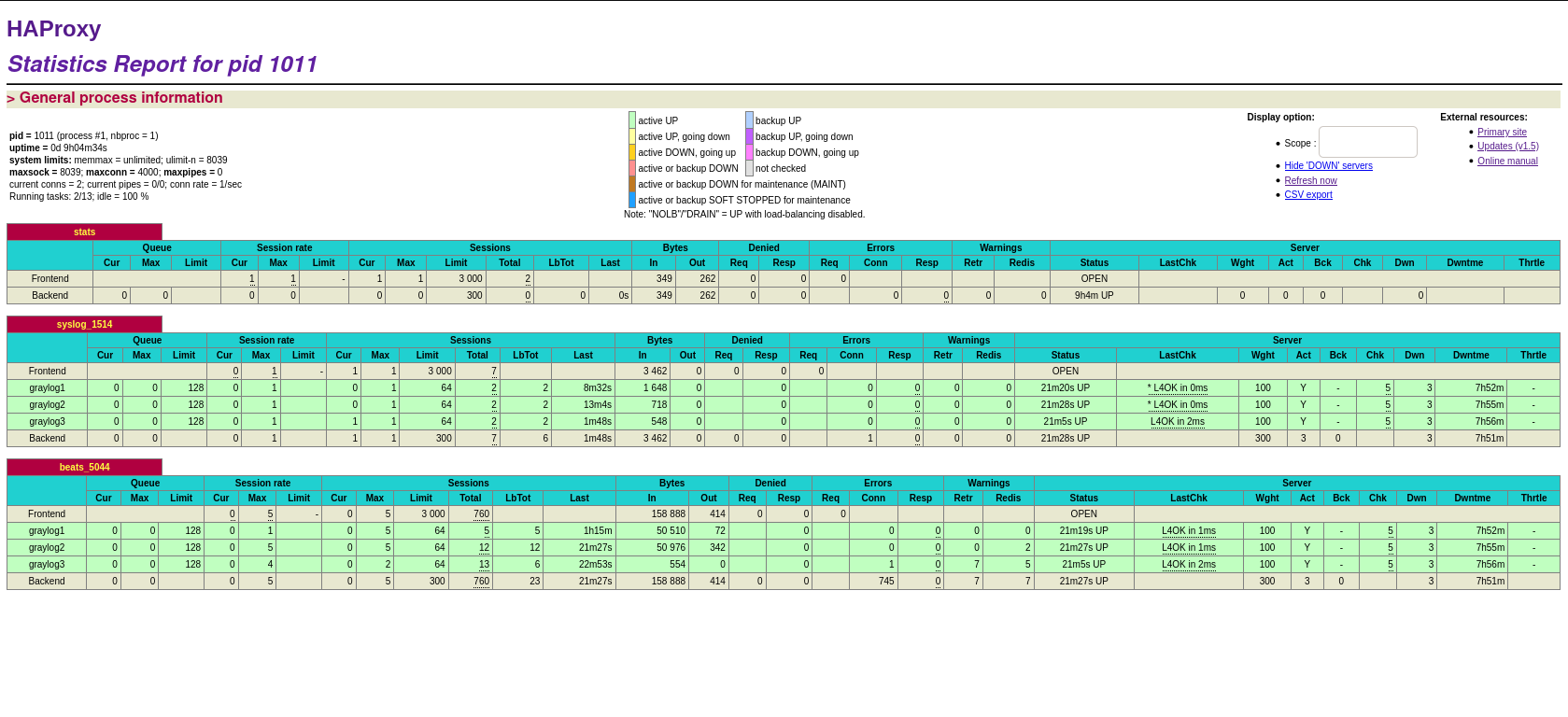
O segundo bloco é a configuração da porta onde o HAProxy irá “ouvir” e depois realizar o balanceamento entre os servidores. O “check” é para que ele verifique se o servidor está ativo antes de enviar dados.
Enviando logs para o Graylog
Syslog
Você consegue enviar praticamente qualquer log de sistema para o servidor do Graylog. Primeiro, vamos inserir logs apenas do tipo Syslog.
O primeiro passo para isso é configurar o Input (entrada de dados) na API do Graylog: ele é o responsável por criar uma porta específica para os variados tipos de log.
Acesse a API do Graylog (no meu caso em http://graylog1.lab:9000/) e siga os passos:
- Vá em System
- Depois em Inputs
- Selecione SysLog TCP
- Selecione Launch new Input
Ao seguir esses passos será aberta uma janela para que sejam preenchidos os detalhes do Input, então vamos preencher os campos:
- Marque a opção Global
- Title: “Log Syslog”
- Bind address: 0.0.0.0
- Port:1514
- Clique em Salvar.
Ao clicar em salvar, veja que o status do input passará de NOT RUNNING para RUNNING.
Agora que você já configurou o input, basta configurar o rsyslog da máquina que irá enviar os logs:
$ vim /etc/rsyslog.d/graylog.conf
*.* @@web.graylog.lab:1514;RSYSLOG_SyslogProtocol23Format
Observações: troque web.graylog.lab para o endereço do servidor do HAProxy.
Reinicie o serviço:
$systemctl restart rsyslog
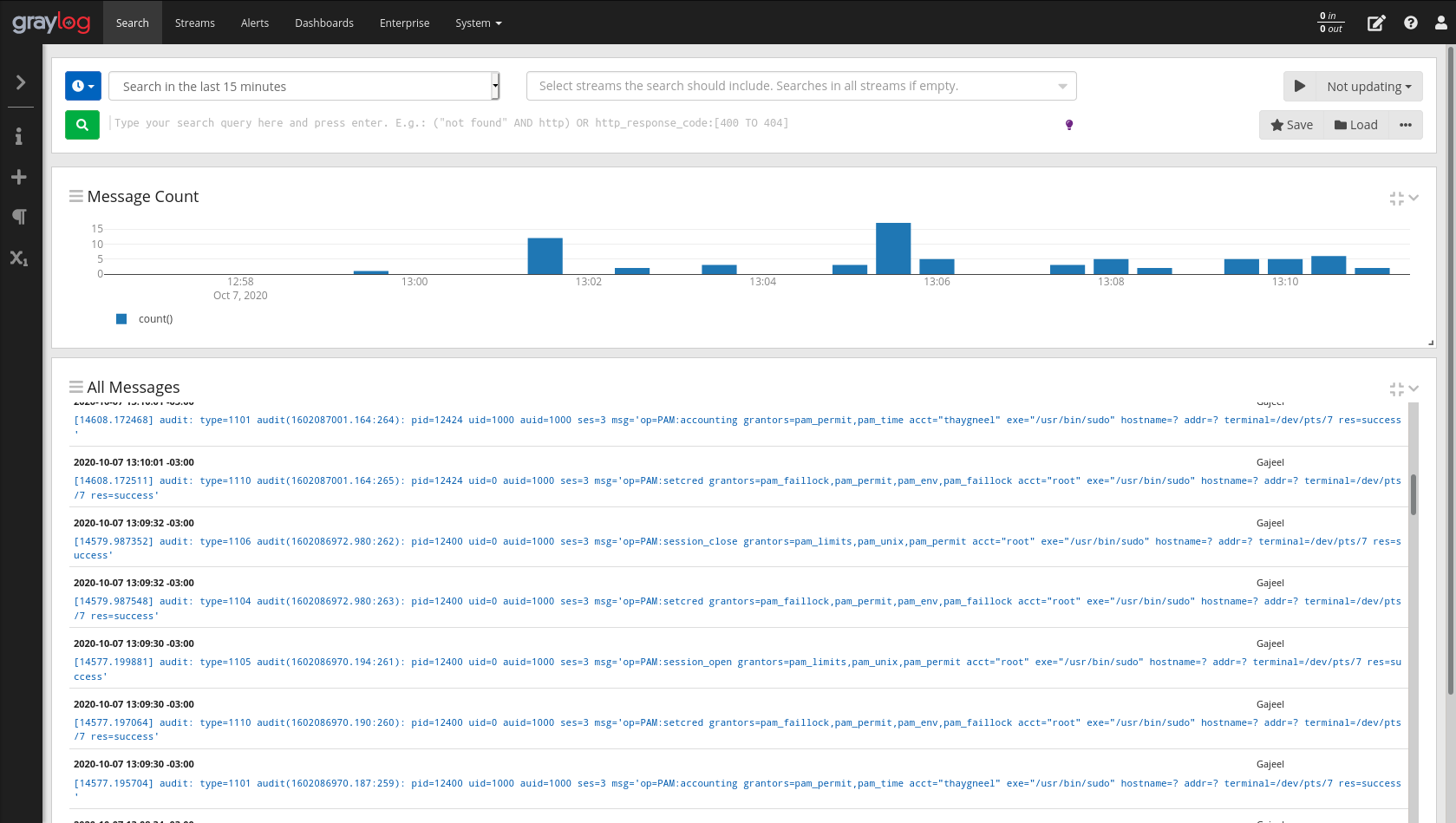
Após todos esses passos, ao acessar a API do Graylog, na aba Search você conseguirá visualizar, fazer consultas e criar dashboards (painéis de controle) personalizados 🙂
Além do rsyslog, também podemos utilizar o Graylog Sidecar para coletar logs. Uma das vantagens de usar esse recurso é o fato de que podemos coletar qualquer log. Para demonstrar esse recurso, vamos colocar logs do HAProxy que funcionam como load balancer do nosso cluster.
O Graylog Sidecar suporta vários coletores, como os mais populares Filebeat, Winlogbeat e NXLog. Nesse guia utilizaremos o Filebeat e por este motivo, começaremos com ele.
FileBeat
Instalação
Primeiro vamos fazer o download:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.9.2-x86_64.rpm
Após realizar o download, vamos instalar:
rpm -vi filebeat-7.9.2-x86_64.rpm
Configuração
Vamos ativar e inserir o caminho do log:
$ vim /etc/filebeat/filebeat.yml
- type: log
enabled: true
paths:
- /var/log/haproxy.log
Na parte de output (saída de dados), vamos comentar a linha output.elasticsearch e hosts logo abaixo dele e vamos descomentar o output.logstash inserindo no campo host o endereço da API do Graylog, vai ficar desta forma:
#================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["web.graylog.lab:5044"]
Depois de configurar vamos inicializar o serviço do Filebeat:
$ systemctl daemon-reload
$ systemctl enable filebeat
$ systemctl start filebeat
Agora vamos configurar o input do Beats na API do Graylog.
Para criar um input basta seguir os passos:
1. Vá na aba System
2. Clique em Inputs
3. Selecione a opção Beats e aclique em “Launch new Input”
Será exibida uma nova janela:
1. Insira um título
2. Port: 5044
3. Clique em Save
Ao clicar em salvar, poderá verificar que o status do input passará de NOT RUNNING para RUNNING.
Graylog Sidecar
Instalação
Para instalar basta executar os comandos:
$ rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-sidecar-repository-1-2.noarch.rpm
$ yum update && yum -y install graylog-sidecar
Configuração
Antes de começar a configurar, será necessário gerar um token na API do Graylog. Para isso, basta seguir os passos:
1. Vá na aba System
2. Clique em Authentication
3. Você verá o usuário Administrator, em “Actions” aperte em “Edit tokens”
4. Insira o nome do token e aperte em “Create Token”
5. Você verá que ele foi criado, aperte em “Copy to clipboard” para copiar
Agora vamos editar o arquivo de configuração do Sidecar:
$ vim /etc/graylog/sidecar/sidecar.yml
server_url: "http://graylog1.lab:9000/api/"
server_api_token: [gerada anteriormente]
node_id: "file:/etc/graylog/sidecar/node-id"
update_interval: 10
tls_skip_verify: false
send_status: true
cache_path: "/var/cache/graylog-sidecar"
log_path: "/var/log/graylog-sidecar"
collector_binaries_whitelist:
- "/usr/bin/filebeat"
- "/usr/share/filebeat/bin/filebeat"
Depois de configurado, vamos inicializar o serviço:
$ graylog-sidecar -service install
$ systemctl start graylog-sidecar
Agora que o Sidecar está em execução no servidor, vamos dar uma olhada no status dele na API do Graylog. Vá em System e clique em Sidecars:
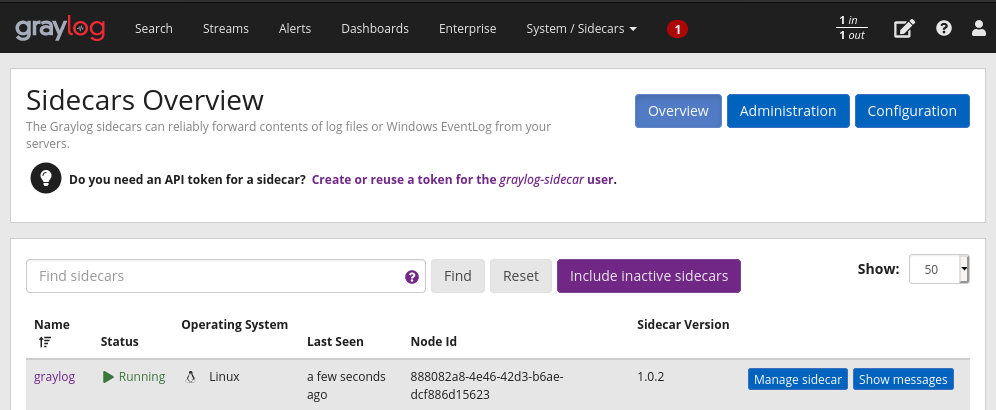
Como já executamos o serviço do Sidecar e já conectamos com a API, ele vai mostrar o nome do nosso hostname e o status do Sidecar (que vai estar como Running). Mas se clicar no nome dele, serão exibidos os detalhes do node e do coletor. Em Collectors status será mostrada a seguinte mensagem:
There are no collectors configured in this sidecar.
Esta mensagem é exibida porque ainda não configuramos o Filebeat para este Sidecar.
Volte para a página Sidecars Overview e clique em Configuration, após isso clique em “Create Configuration”.
1. Insira um nome para o coletor
2. Selecione uma cor
3. Na opção “Collector” selecione “filebeat on Linux”
O próximo campo é a configuração, nós apenas iremos alterar o path e o output.logstash, vai ficar mais ou menos desta forma:
# Needed for Graylog
fields_under_root: true
fields.collector_node_id: ${sidecar.nodeName}
fields.gl2_source_collector: ${sidecar.nodeId}
filebeat.inputs:
- input_type: log
paths:
- /var/log/haproxy.log
type: log
output.logstash:
hosts: ["web.graylog.lab:5044"]
path:
data: /var/lib/graylog-sidecar/collectors/filebeat/data
logs: /var/lib/graylog-sidecar/collectors/filebeat/log
Após isso clique em Create.
Pronto, com a configuração pronta, vamos para a página Collector Administration, basta clicar no botão “Administration” no canto superior direito.
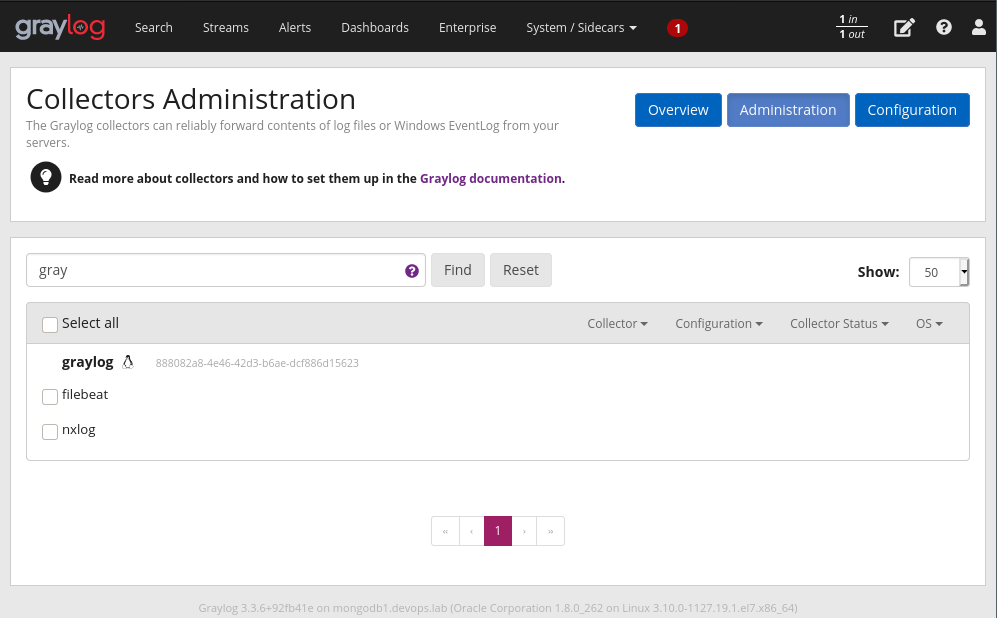
Agora vamos aplicar a configuração que criamos anteriormente. Uma vez que estamos na página Collector Administration vamos seguir esses passos:
1. Selecione o checkbox “filebeat”
2. Após ter selecionado, clique em “configure”
3. Selecione a configuração do Filebeat que a gente criou anteriormente.
Ele vai abrir essa janela de confirmação:
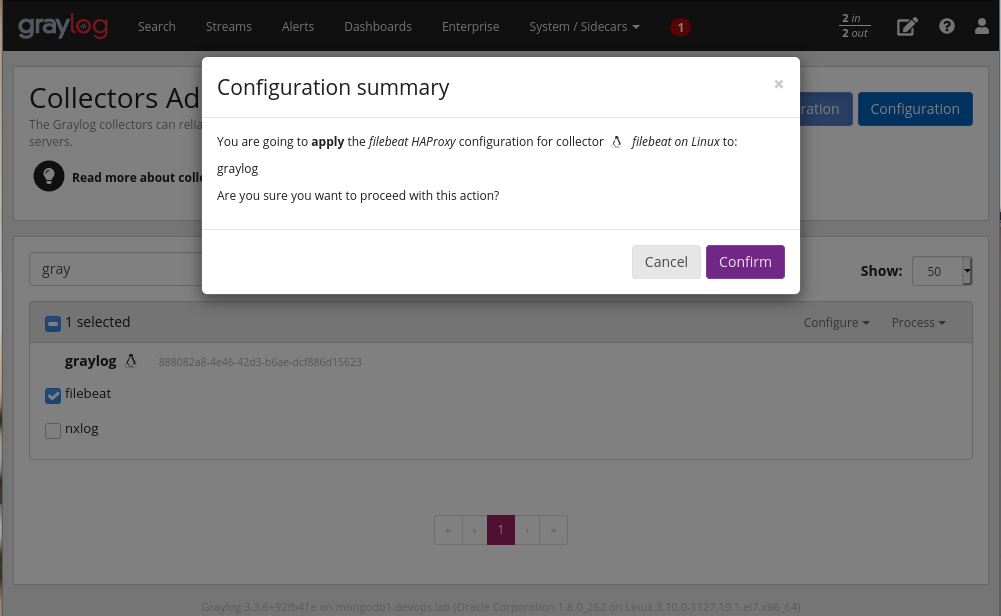
Clique em “Confirm”
As configurações foram aplicadas e nosso Filebeat já está em execução.
Para ver os logs do HAProxy basta voltar na página Sidecars overview e clicar em “Show messages”.
Dashboard
Agora que coletamos mensagens de log do syslog e do HAProxy, podemos explorar e criar tabelas e gráficos com consultas específicas. Vamos fazer isso criando um novo dashboard para os logs do HAProxy.
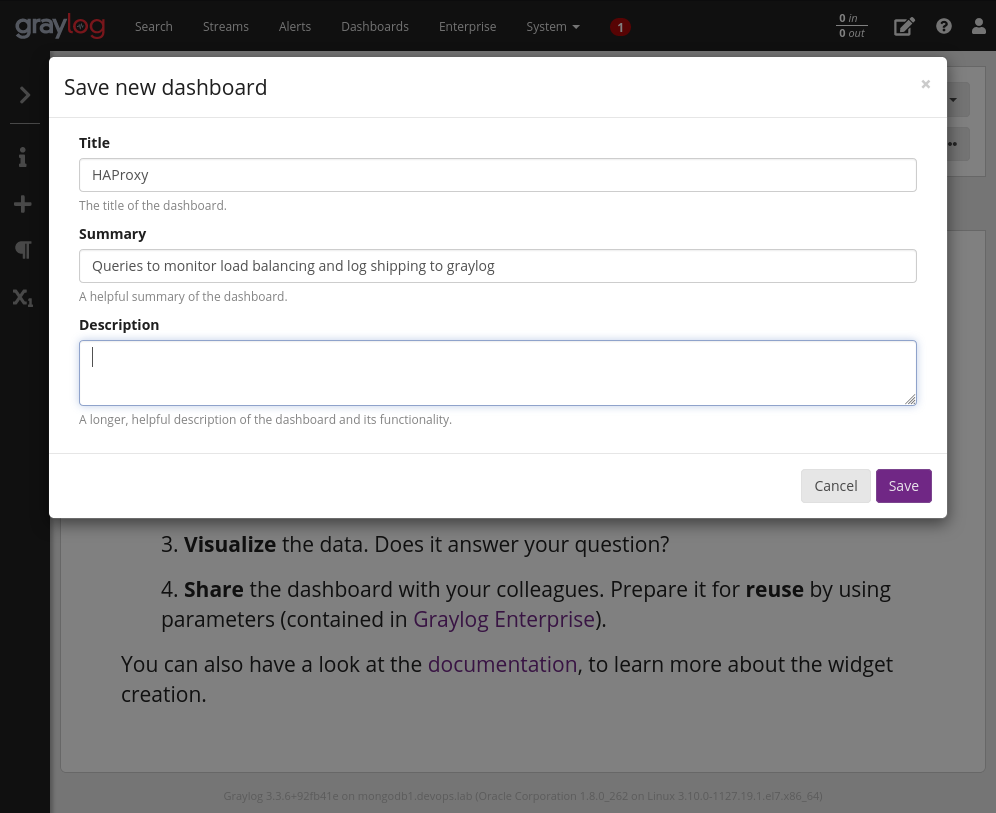
Clique na aba Dashboards e clique no botão em “Create new dashboard”. Vamos apenas salvar para inserir as consultas depois. Clique em “Save as”. Após isso será exibida uma janela para que sejam informados os detalhes do seu novo dashboard:
Exportando através da aba Search
Em nossa primeira consulta vamos pegar quantas vezes o HAProxy recebeu mensagens de log mas não conseguiu enviar para nenhum servidor do Graylog. Já sabemos que o HAProxy faz o balanceamento de envio de logs entre os servidores do Graylog, logo, se os servidores do Graylog não estavam funcionando, esse balanceamento seria impossível.
Primeiro informe o marco de tempo como 1 dia. E na consulta insira a query:
`source: graylog && message:”has no server available”`
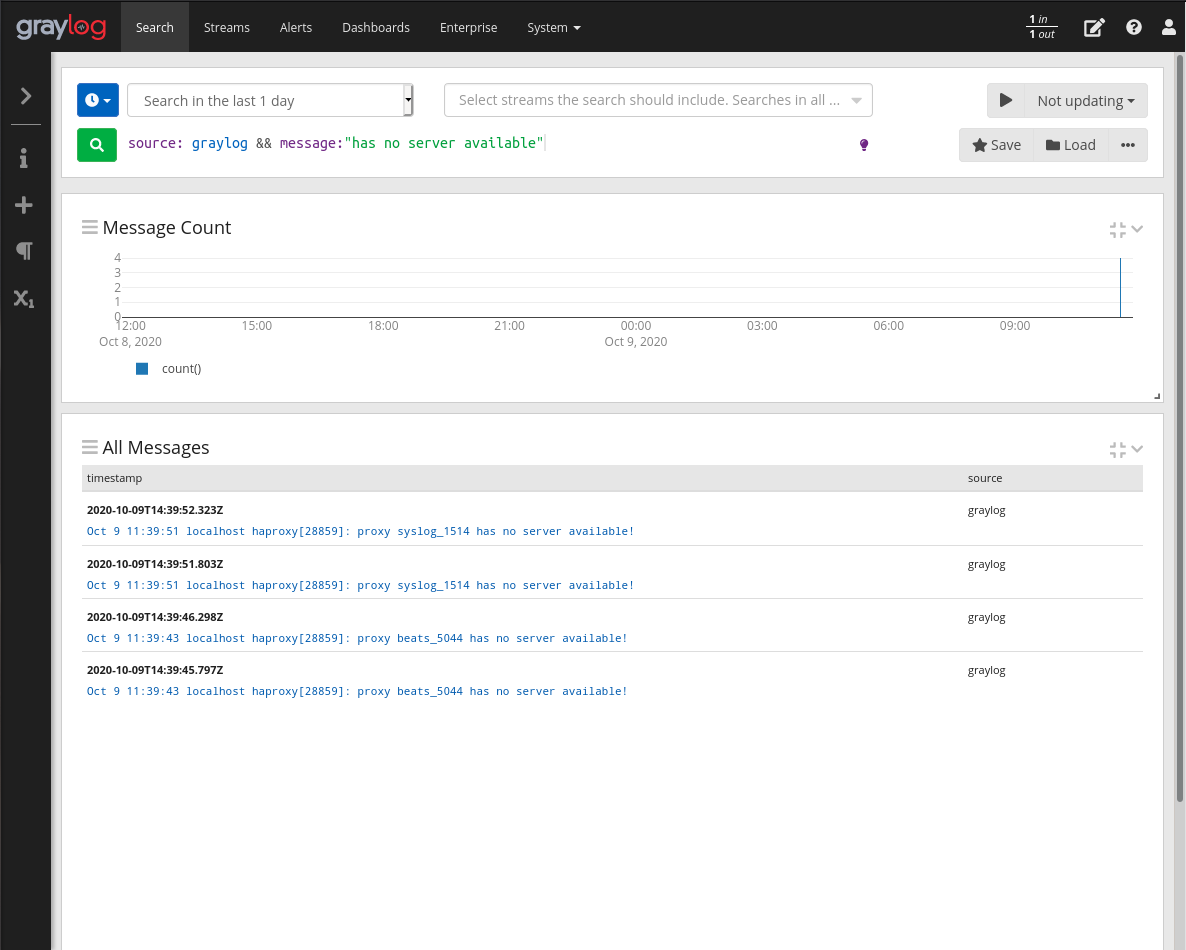
Assim de clicar no botão de pesquisar, serão exibidas todas a mensagens correspondentes à query.
Então vamos adicionar um widget com query no nosso dashboard.
Para isso vamos clicar no ícone “+” que fica no canto esquerdo da página e depois clicar em “Message Count”.
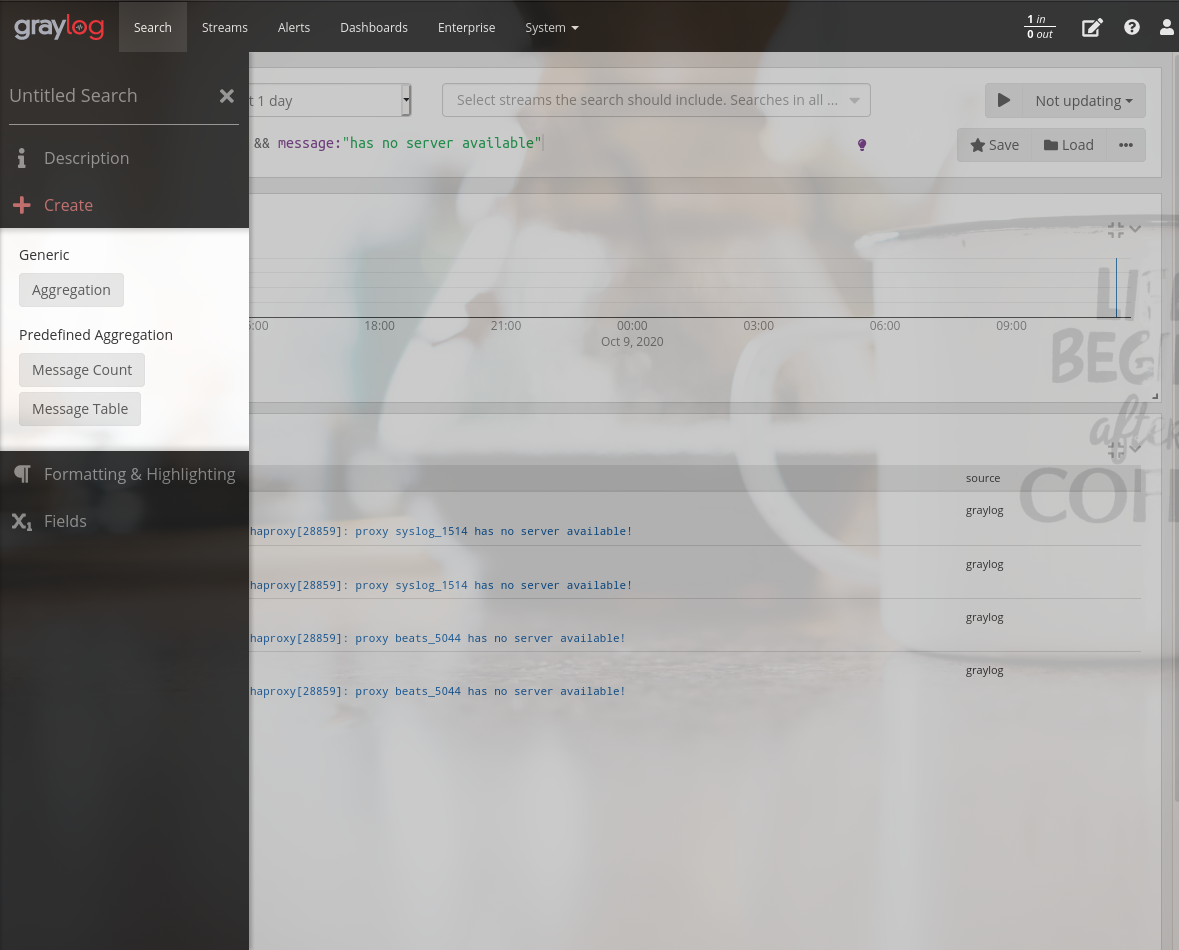
Com o widget criado, vamos copiar para o nosso dashboard. No canto direito superior do widget, você verá uma seta para baixo e ao clicar nela vai aparecer a opção “copy to a Dashboard”, ao clicar nessa opção uma janela será exibida para que você possa selecionar o dashboard.
Assim que selecionar, ele nos levará ao dashboard. Vamos renomear nosso widget e clicar em salvar.
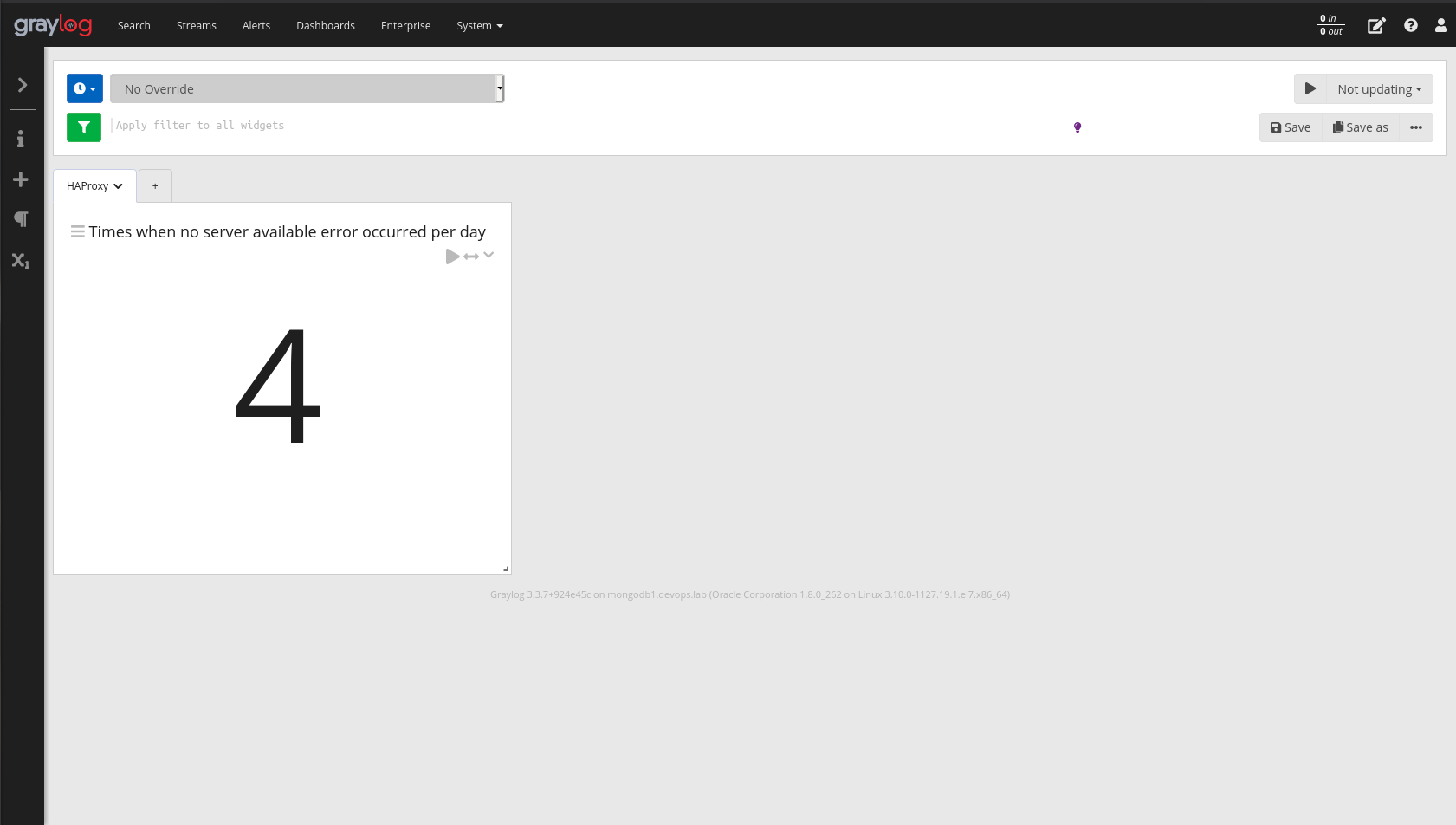
Criando direto do dashboard
Primeiro clique no botão “+” e depois em “Message Table”.
Será exibida uma tabela com todas as mensagens, mas queremos apenas mensagens do nosso server do HAProxy. Para editar a consulta basta clicar no ícone de seta para baixo e selecionar a opção “”Edit”.
Uma nova janela será mostrada contendo os detalhes da tabela.
Agora vamos adicionar a query:
source:graylog
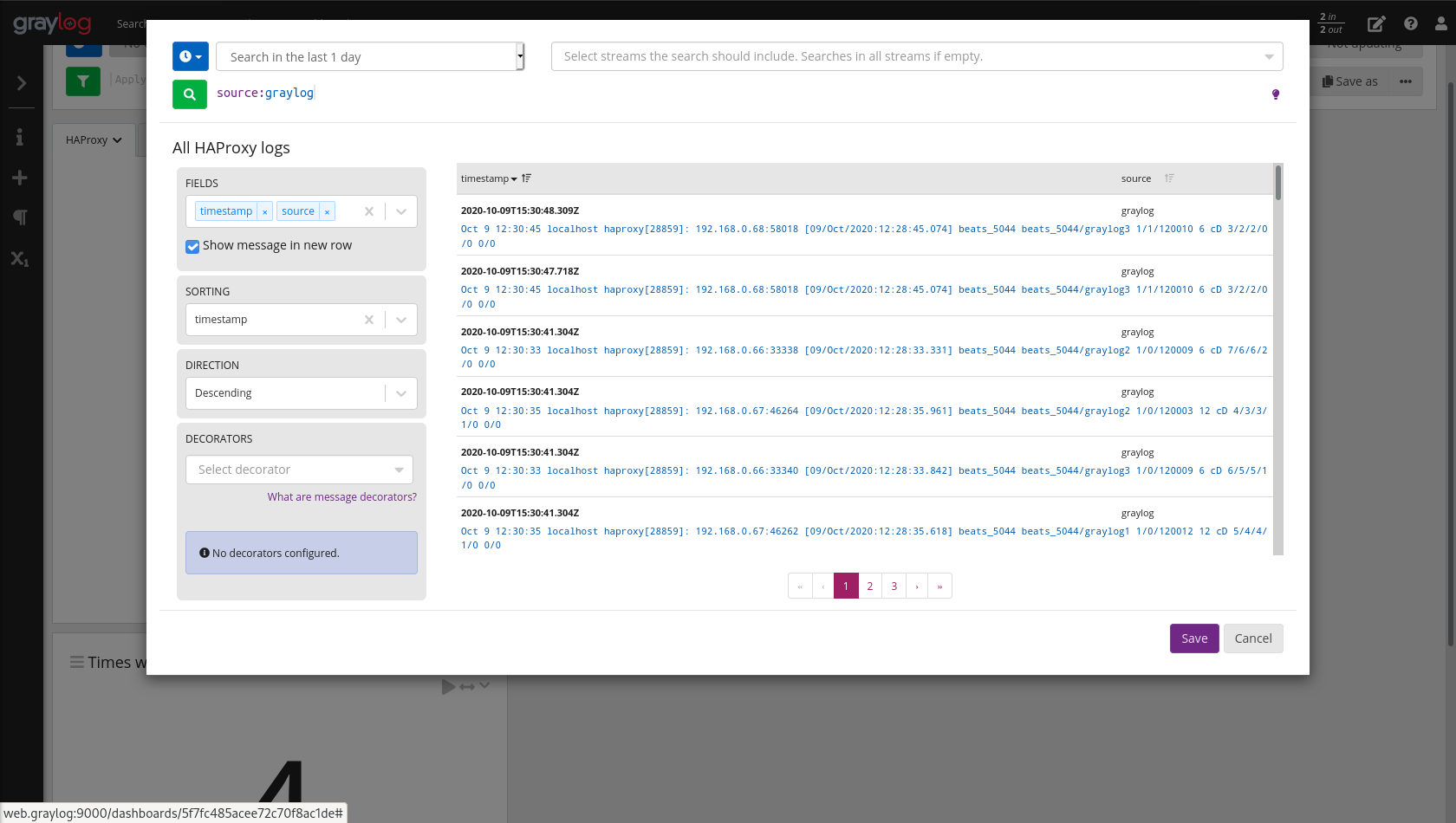
Agora temos dois widgets e vamos adicionar mais um utilizando outro método.
Clique no ícone “+” e depois em “Aggregation”. Após isso clique em “Edit” para editar a consulta do widget. Em minha consulta filtrei apenas o servidor do HAProxy.
Utilizei o gráfico “Area Chart” e consultei quantos logs foram enviados por faixa de tempo:
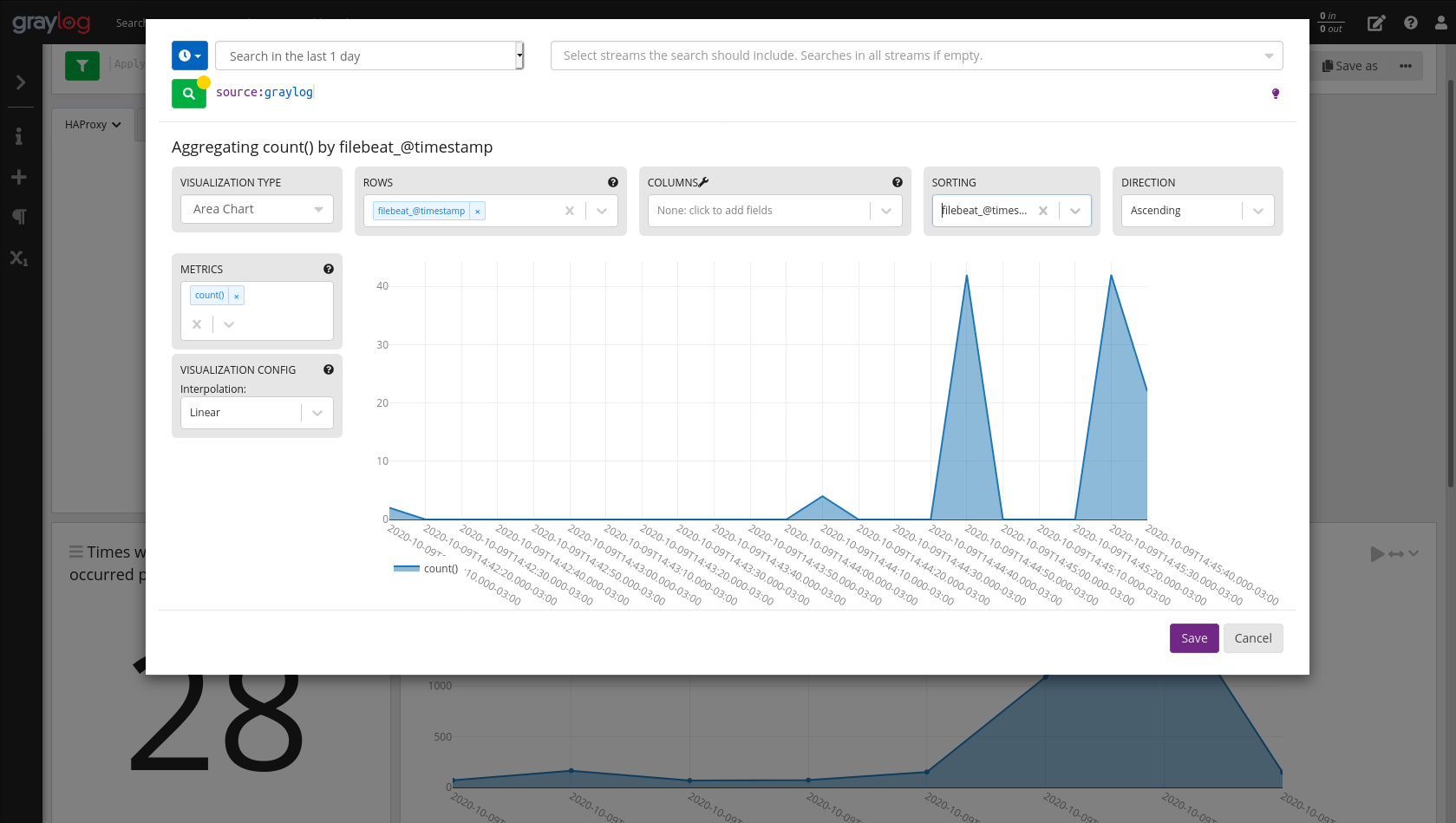
O Graylog permite que você mova, redimensione e edite seus widgets, o que facilita para que você personalize seu dashboard da forma que achar melhor. O meu ficou desta forma:
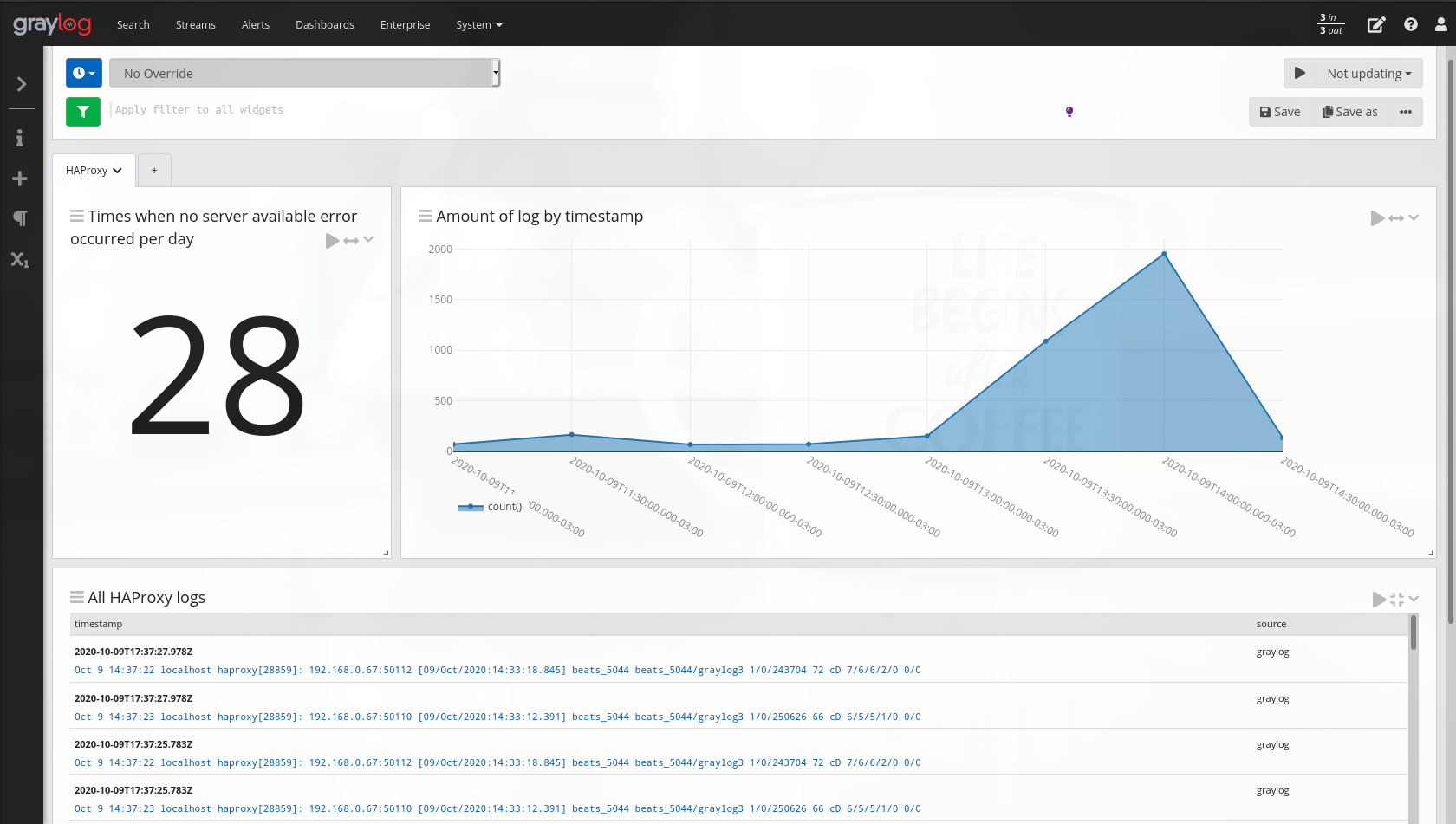
Espero que este artigo tenha tornado mais claro o funcionamento do Graylog e facilite sua vida no dia a dia.
Até a próxima!
Mais informações
[1] Centralização de dados com Graylog: https://4linux.com.br/consultoria/suporte/centralizacao-de-logs-com-graylog-monitoramento-ti/
[2] ELK: https://4linux.com.br/consultoria/suporte/observability-monitoramento-analise-elastic-stack/
[3] MongoDB: https://4linux.com.br/consultoria/suporte/banco-de-dados-nao-relacional-nosql-com-mongodb/
[4] Elasticsearch: https://4linux.com.br/consultoria/suporte/observability-monitoramento-analise-elastic-stack/
[5] Multi-node Setup: https://docs.graylog.org/en/3.3/pages/configuration/multinode_setup.html#configure-multinode
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Descubra o futuro do desenvolvimento de software com Docker e Kubernetes
Docker, Kubernetes, Openshift, enfim … escalabilidade! A tecnologia de containers está moldando o futuro do desenvolvimento de software e está causando uma mudança estrutural no mundo da computação, principalmente quando
Workshop Infraestrutura Ágil: Conheça as ferramentas DevOps da 4Linux
No dia 10/11/2016, aconteceu na sede da 4linux em São Paulo o workshop “Infraestrutura Ágil”. A procura foi grande pois o público estava muito interessado em ouvir sobre DOCKER, GIT,

Vagrant: o que é, onde vive e o que come? Aqui no blog da 4Linux!
A tecnologia nunca foi algo provisório ou estacionário, a todo momento vemos mudanças e essas são sempre acompanhadas de desafios. Estar antenado com atualizações e lançamentos é uma tarefa árdua,





