
Melhore seus projetos de BI e DW com métodos Ágeis: descubra como!
BI, Ágil, Scrum e Waterfall…
É, acho que não faltou nenhuma buzzword aqui.
Hoje vou tentar te ajudar mostrando como seus projetos de BI (Business Intelligence) e DW (Data Warehouse) podem ser melhorados adotando-se métodos Ágeis. E, seu eu conseguir, ajudo a 4Linux a vender o curso. Quando acabar de ler, basta apertar o botão escrito Clique Aqui para Comprar e todo mundo ficará feliz. Aliás, pode clicar agora, se quiser – aqui é o cliente quem manda, hehe!
Meu nome é Fábio de Salles, autor do curso de pentaho e agora deste novo curso, ambos oferecidos pela 4Linux. Você pode conhecer um pouco mais sobre mim visitando a página Sobre do meu blog, o GeekBI.
Como sempre faço no meu blog, vou deixar clara a intenção deste post logo de saída:
Quero te convencer a comprar o novo curso da 4Linux. 🙂
E o que eu ganho? Ah, eu sou modesto: só quero ficar famoso. 😀
Em Linhas Gerais…
… todo projeto de BI lê dados de algum lugar e apresenta-os de alguma forma, por meio de alguma ferramenta, a algum usuário. Concorda?
E como implementamos isso? Intuitivamente, seguindo mais ou menos essas etapas:
- Perguntamos ao cliente o que ele quer (levantamos requisitos;)
- Desenhamos o modelo de dados, ou seja, definimos que tabelas, colunas etc. serão construídas para atender aos requisitos;
- Analisamos as origens de dados (sistemas OLTP, planilhas, arquivos texto e tudo mais que houver) e montamos o processo de carga dos dados, o ETL;
- Finalmente construímos a representação desses dados (painel, relatório, cubo…) na ferramenta que o cliente pediu (local, via web, interativa, estática, Data Discovery ou o que o cliente quiser.)
Claro que tem que haver algum trabalho para instalar os softwares, configurar contas, controles de acesso, testes, agendar os refreshes e assim por diante, mas as principais fases estão na lista acima.
Ainda concordando comigo, espero.
Tradicionalmente fazemos essas etapas uma atrás da outra, e entregamos o produto pronto ao cliente quando completamos a última etapa. O trabalho corre como água descendo várias cascatas, ou quedas-d’água – waterfall em Inglês.
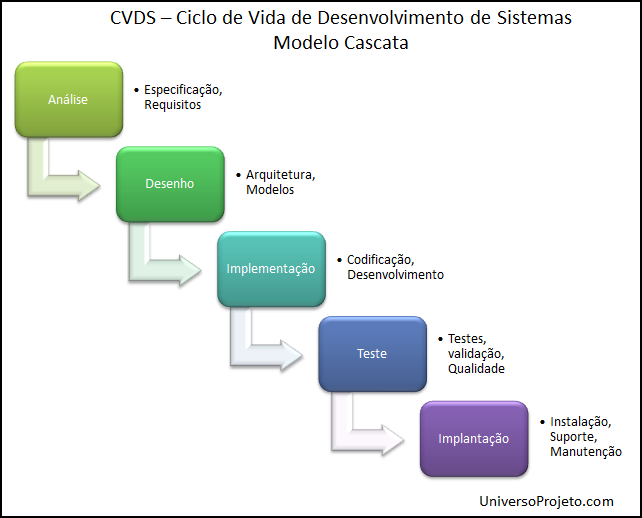
Desenvolvimento em cascata (waterfall.)
O modelo Waterfall
Esse tipo de processo de desenvolvimento imperou até meados da década de 90, quando começou a ser substituído por outro modelo, o Ágil. O modelo Waterfall sofria de muitos problemas, e quanto maior era o projeto, mais garantido era que teria problemas e que atrasaria.
Não cabe aqui analisar as causas desses problemas mas, por alto, o que acontecia era que a equipe ficava tempo demais longe do cliente, e trabalhava para entregar algo que não necessariamente era o que o cliente precisava. Essa vida desgastante de atrasos e insucessos começou a encher a paciência de todo mundo, até que, em resposta a essas dificuldades e ao baixo valor agregado desse formato, um bando de pessoas se reuniu e criou o Movimento (ou Manifesto) Ágil.
Deu tão certo que acabou se espalhando por todo tipo de atividade humana: de ensino à projetos de marketing, do planejamento de uma festa na empresa à construção de carros. Os livros Scrum: A Arte de Faze o Dobro do Trabalho na Metade do Tempo e Agile Management with Scrum, respectivamente de Jeff Sutherland e Ken Schwaber, mostram esses exemplos.
O modelo Ágil
Este modelo é mais leve e flexível que o Waterfall, com peso maior na qualidade dos resultados que na qualidade do processo em si. Assim, ao invés de gastar tempo planejando o projeto inteiro antes de começar a implementar qualquer coisa, os métodos ágeis planejam apenas a próxima entrega. Um projeto Ágil é montado pedaço por pedaço, em que cada pedaço é feito até o fim, incluindo a implantação se o cliente desejar. Ao invés de uma grande entrega, completa e final, um processo Ágil realiza entregas parciais, pequenas e completas em si mesmas e recorrente (em iterações). Entre outras vantagens, esse formato permite que o escopo do projeto seja ajustado continuamente, se beneficiando do aprendizado do cliente sobre suas necessidades. O resultado final é um crescimento contínuo do valor gerado pelo projeto e um diminuição brutal dos prazos e problemas.
Compare:
 Imagine um projeto que, aos trancos e barrancos, demora um pouco, mas dá resultado em um certo tempo. Adotar ágil permite que o projeto seja entregue em menos tempo, com mais qualidade e menos sofrimento – menos trancos e barrancos. Tenho amigos que só de pensar em ter menos sofrimento já se motivam.
Imagine um projeto que, aos trancos e barrancos, demora um pouco, mas dá resultado em um certo tempo. Adotar ágil permite que o projeto seja entregue em menos tempo, com mais qualidade e menos sofrimento – menos trancos e barrancos. Tenho amigos que só de pensar em ter menos sofrimento já se motivam.
Em modelos Ágeis mudanças no escopo são esperadas e até desejadas. Ágil estimula a colaboração e permite o ajuste constante do que é criado ao que realmente tem valor
para o cliente
Oras, se funcionou com festas, carros, mudança de casa e até evolução pessoal, com certeza vai fazer maravilhas por projetos de BI, não? Ainda mais que um projeto de BI parece-se muito com um de sofware: levantamos requisitos, modelamos, implementamos, testamos e entregamos.
Não é?
Na Prática a Teoria é Outra
Sim e não.
Estou no mercado de BI desde 2000, há mais de 17 anos. Já vi todo tipo de coisa, e quando Ágil virou febre, vi muitos tentarem, incluindo eu. Cheguei a comandar os primeiros projetos de BI com Scrum na empresa em que trabalho (minha identidade secreta é analista em uma empresa de TI de grande porte. Leia o Sobre!) e tenho um grau de confiança razoável em afirmar que juntar Scrum com BI não é uma tarefa trivial, óbvia.
Então, sim: adotar Ágil, ou Scrum mais especificamente, para projetos de DW e/ou BI funciona. Eu experimentei em primeira mão e garanto que os resultados são empolgantes: mudar a forma de trabalho de cascata para Ágil acabou com o problema de projeto atrasado, e com isso melhorou muito a satisfação dos clientes. Se você tem alguma dúvida acerca da utilidade do Ágil, vai que dá. Eu consegui tudo que eu precisei lendo os capítulos iniciais do Agile Management with Scrum – ali tem o suficiente para trabalhar.
E o “não”?
Bom, o fato é que adotar Ágil melhorou a situação, mas não a resolveu. Eu não consegui aquela produtividade fantástica, e as coisas não ficaram menos trabalhosas. Ao contrário: nosso ritmo aumentou, e a complexidade do trabalho aumentou. Começamos a ter, por exemplo, problemas com desgaste pessoal: ao invés de ficar divertido e leve, passamos por apertos. Muito melhor que antes, é verdade, mas não estava funcionando como deveria.
Eu parti atrás de descobri o que é que eu estava fazendo de errado. E eu descobri: não estava fazendo nada de errado. Simplesmente eu estava tentando fazer algo que ainda não havia sido feito, que ninguém tinha resolvido!
Eu devorei a literatura a respeito para tentar entender meus problemas. Acabei descobrindo que, na maioria dos casos, o conteúdo disponível em livros, artigos, sites e vídeos pode ser dividido em dois grandes grupos:
- DW (Data Warehouse) Ágil;
- Gestão Ágil de Projetos;

Exemplos de literatura “ágil” para BI.
Na primeira categoria estão livros que discutem como adaptar o processo de desenvolvimento de DW (e em tudo que eu vi, DW é igual à Modelo Dimensional) para técnicas ágeis. Era mais ou menos o que eu havia feito.
Na segunda categoria estão os textos, como esse e este, que incensam processos ágeis, mas dizem muito pouco sobre como torná-los realidade ou como afetar a qualidade de um projeto de BI com essas técnicas.
E mais: ambos os grupos abordam unicamente Scrum como técnica Ágil. Só para constar, ainda não achei ninguém falando de, por exemplo, Kanban ou DevOps para BI. Essas são duas técnicas que me parecem perfeitas para gestão de projetos de BI, em geral, e de Armazéns de Dados, em especial. Por exemplo: hoje, setembro de 2017, estou desenvolvendo um projeto de DW do zero totalmente baseado em Kanban e DevOps. Nada de Scrum, nada de qualquer outra coisa.
Agile Scrum em projetos BI
Essas são as coisas de Scrum que funcionaram para meus projetos de BI:
- Criar backlog de projeto: levantar os requisitos em formato de histórias;
- Iniciar a sprint: escolher as histórias mais importantes que a equipe acredita que consegue entregar em uma sprint;
- Rodar a sprint: implementar, testar, ajustar, refinar etc. etc. etc.;
- Demo: mostrar ao cliente o que foi feito;
- Reiniciar: selecionar as próximas histórias e recomeçar.
É importante lembrarmos que Ágil, tal como foi criado, não significa rápido, bagunçado ou sem documentação, mas sim com melhoria constante.

Ciclo Scrum.
Em uma sprint fazemos apenas um pedaço. Se dá certo, vamos adiante. Se o cliente inspeciona o resultado e conclui que estava pedindo coisas inadequadas, voltamos atrás e recomeçamos, agora com mais informação e com um cliente que entende melhor o que precisa. Fail fast and early, dizem os agilistas, falhe o quanto antes, para não construir um fracasso maior no futuro. Entregas pequenas, em curto espaço de tempo, melhorando a cada ciclo. Esse é o espírito do Ágil.
Uma das habilidade críticas para o sucesso de técnicas como Scrum é conseguir quebrar o trabalho em pedaços pequenos, que possam ser tratados em pouco tempo e que agreguem valor.
Veja essa história:
Como cliente de uma loja de e-commerce eu quero poder comprar qualquer coisa de seu estoque via web, em um computador, um tablet ou em um smartphone, pagar de várias formas, e acompanhar o pedido por mensagens de e-mail.
Apesar de traduzir a necessidade do cliente e agregar valor, dificilmente ela vai caber em uma iteração pequena. Ela é tão grande que muito coisa terá mudado até completarmos essa demanda. Histórias assim atrapalham ao invés de ajudar.
Uma história mais interessante seria assim:
Como cliente, quero poder pagar meu pedido com cartão de crédito.
Essa demanda é relativamente pequena, bem específica, e provavelmente pode ser trabalhada dentro de uma sprint de 3 ou 4 semanas. Pode ser testada, pode ser documentada com mais facilidade. E para tratar qualquer projeto de BI com Ágil, usando um DW ou não, precisamos saber como quebrar a demanda do cliente em histórias de um tamanho adequado, que contenha um pedaço completo do projeto, que caiba em uma sprint.
Poeira de Estrelas
Esse foi o problema que eu enfrentei: o tamanho das histórias.
Sim, funciona: trabalhar em ciclos pequenos e validar o resultado com o cliente ao final de cada sprint dá mais resultados do que ficar em um projeto que leva meses até descobrir que está tudo errado.
Não, não funciona: é difícil quebrar as necessidades do cliente em histórias de tamanho adequado. Vamos examinar esse problema de perto, e ver o que podemos fazer para resolvê-lo.
Esses são exemplos clássicos de demandas de BI escritos como histórias:
- Como gerente de vendas, eu quero ver um gráfico de valor, desconto e quantidades das vendas por cliente, data e produto;
- Como analista financeiro, eu quero poder analisar (girar um cubo OLAP) o lucro das vendas por fornecedor e data;
- Como vendedor, que tem metas a bater, eu quero poder ver todo dia um extrato (relatório) com o movimento das minhas vendas do dia anterior: quanto eu vendi por produto.
O formato aqui é sempre o mesmo: quero acesso a um certo conjunto de dados através de um certo recurso, onde recurso pode ser um painel, um relatório, um cubo OLAP e outras coisas.
Exemplo de painel de instrumentos (dashboard.)
Já o conjunto de dados tem cara de uma estrela dimensional: atributos e métricas. O que faz todo sentido: quem já trabalhou em projetos de BI sabe que, quase sempre, os dados que o cliente quer analisar ficam melhor organizados em uma estrela dimensional.

Estrela dimensional Dexter Courier.
De maneira simplificada, uma estrela dimensional, ou um modelo dimensional, é um grupo de tabelas chamadas dimensões ligadas a uma tabela chamada fato por meio de chaves primárias/estrangeiras chamadas chaves delegadas. Para evitar impacto negativo nos servidores da empresa, essas tabelas costumam residir em outro servidor. Por simplificidade, vamos chamar esse servidor de Armazém de Dados, ou Data Warehouse (DW.)
E quais são as tarefas para cada uma destas histórias? Ou seja, qual é o backlog da sprint?
Quem conhece Scrum sabe que, no primeiro dia da sprint, a equipe de desenvolvimento faz uma reunião com o Product Owner na parte da manhã para selecionar do backlog do produto quais histórias serão tratadas. Depois, na parte da tarde, a equipe se planeja: examina as histórias e rascunham as tarefas que precisam ser executadas para entregar cada uma. Essa lista de tarefas é o backlog da sprint.
Vamos pegar a primeira história, do Gerente de Vendas:
- Definir o dataset deve ser trazido do sistema de origem (quais dados a demanda pede;)
- Documentar isso de alguma forma: desenhar um diagrama ou redigir um dicionário de dados;
- Criar a tabela no DW;
- Escrever e testar o ETL;
- Construir o recurso (um relatório, por exemplo;)
- Implantar: agendar o ETL para execução periódica no servidor e disponibilizar o recurso ao usuário.
Como toda história é a mesma coisa – entregar algum dado de alguma forma – essas são as tarefas de virtualmente todas histórias de BI.

Exemplo de história e tarefas em Scrum (snapshot do IceScrum 6.)
Notou que vamos ter dois problemas sérios?
- Vamos criar uma multitude de artefatos similares, alimentando uma explosão de estrelas e recursos. É como se todas as história fossem construídas do zero;
- Vamos criar dados inconsistentes: não demora nada até dois usuários compararem seus dados e iniciare uma discussão por causa das diferenças.
A solução é simples: vamos avaliar o volume total de trabalho no início e organizar tudo em torno de conjuntos de dados comuns a várias demandas.
- O analista de requisitos dá o pontapé inicial: identificamos todos os interessados ao invés de apenas quem vai ser atendido primeiro;
- Levantamos o que todos estes clientes precisam;
- Daí trabalhamos para achar as demandas em comum;
- O analista de DW entra em cena: ele pega as demandas em comum e monta estrelas dimensionais.
Pronto! Isso vai acabar com a replicação de ETL, reduzir a quantidade de datasets e, consequentemente, reduzir o trabalho de testes e manutenção, bem como aliviar a carga do servidor de ETL e do DW e reduzir os conflitos de dados.
Um time fica encarregado do desenvolvimento dos datasets. Assim que estes ficarem prontos, entra em campo o time que desenvolve os recursos (cubos relatórios e assim por diante.)
E as histórias que capturamos antes, mudam? Não, mas agora precisamos de uma nova história: a história da estrela.
A fim de atender as necessidades dos usuários, devemos criar um dataset que reúna os dados de lucro, valor, desconto, quantidades vendido por cliente, data, produto, fornecedor.
E isso é uma estrela dimensional completa.
Quanto Mais as Coisas Mudam…
… mais elas ficam no mesmo.
Hora da porca torcer o rabo! 🙂
Nesta seção vamos, finalmente!, explicar o que o novo curso da 4linux promete.
Até agora vimos que:
- Ágil tomou o mundo de assalto por que, corretamente aplicado, gera um grande aumento de produtividade;
- Ágil funciona para muitas coisas, mas não funciona 100% para BI;
- BI/DW com Scrum melhora a produtividade, mas não muito por causa do tamanho das histórias;
- Descobrimos que além das histórias tradicionais, de usuários, precisamos de um novo tipo: precisamos de histórias de dados.
A história de dados é, no fundo, a especificação de estrelas dimensionais.
Se tentarmos desenhar as estrelas antes de saber tudo que nossos usuários querem, fatalmente vamos ter que refazer essas estrelas no futuro, caindo de volta no problema inicial. Em jargão Ágil, estaremos criando débito técnico.
Logo, para redigir as histórias dados e reduzir o retrabalho, precisamos levantar completamente, ou quase completamente, a necessidade do cliente. Enquanto não fecharmos uma lista de atributos e métricas para a maioria dos usuários, não podemos desenhar as estrelas que serão necessárias, sob (alto) risco de criar débito técnico.
Só depois de especificar as estrelas dimensionais podemos construir os recursos que os usuários pediram, e só então podemos mostrar a eles o que está sendo produzido.
Percebe para onde este raciocínio está nos levando?
- Ágil preconiza feedback do cliente o quanto antes mas…
- … precisamos concluir uma história para obter feedback;
- Só concluímos a história construindo o artefato de consumo de dados…
- … que só pode ser construído se houver dados…
- … que só vão estar disponíveis depois de construir o processo de ETL…
- … que só pode ser construído depois de desenhado o modelo de dados…
- … que só saberemos qual é se soubermos tudo que os clientes querem.
Vamos olhar de outra forma:
- Para entregar a demanda do cliente, precisamos da tabela fato, que é onde estão os dados que respondem a demanda do cliente;
- Para construir a tabela fato, precisamos das tabelas de dimensão;
- Para ter as tabelas de dimensão, precisamos do modelo pronto;
- Para ter o modelo pronto, precisamos levantar tudo que o cliente vai querer, e não apenas um pedaço.
Ou seja, de novo e de novo acabamos voltando ao modelo cascata:
- Levantar requisitos;
- Desenhar modelo de dados;
- Construir processo de ETL;
- Construir entregáveis.
E não dá para aplicar ágil nisso!…
.. a menos que você faça o curso da 4Linux, claro. 😀
Conclusão
A prática de projeto de BI atual, executada por muitos times, diz que não é possível apresentar nada sem antes ter completado uma boa parte, que é o modelo de dados. E não é uma coisa brasileira, localizada. Como exemplo, vejam o post Agile Data Warehouse: Intro. Tal como muitos fazem hoje, projetos de BI são tratados sequencialmente e não há como evitar isso.
De cara isso já ferra com a ideia de incremento: não dá para perseguir melhoria contínua se o produto precisa ser completado até quase o final, ou ao menos uma grande parte antes de poder ser testado. Uma história não representa uma pequena funcionalidade da solução, mas sim uma parte inteira do produto final (história de dados) ou uma parte que é proporcionalmente muito menor (história de usuário.)
Ainda que aplicar Ágil melhore um projeto de BI/DW, uma história grande demais como a história de dados destrói a principal vantagem do formato Ágil. Por isso é fundamental aprender como dividir a necessidade do cliente em histórias de tamanho apropriado.
O curso de Ágil para BI/DW da 4Linux ensina “como dividir a necessidade do cliente em histórias de tamanho apropriado”.
Nele você vai conhecer uma técnica enxuta (lean) para levantar e documentar os requisitos dos seus clientes e como adequá-los à aplicação de metodologias de gestão Ágil, como Scrum ou Kanban.
Aplicando o método demonstrado no curso você vai conseguir iniciar sua sprint com o resultado pré-aprovado, aumentando sua produtividade e reduzindo desperdício e problemas.
Tudo isso será apresentado em vídeo-aulas com exercícios práticos, usando a Suite Pentaho para Soluções de Inteligência de Negócios, uma poderosa ferramenta (Software Livre) de BI/DW. Você ganhará templates de histórias, exemplos prontos para estudar, um banco de dados de exemplo e uma máquina virtual pronta, para início instantâneo. Mesmo assim o curso dá informação suficiente para você repetir tudo do zero, se quiser.
Não é obrigatório ter Pentaho.
Você pode aproveitar o curso mesmo que sua empresa ou organização use outra ferramenta de BI/DW. E se sua empresa ainda não tem nenhum projeto de BI/DW, este curso é um bom primeiro passo porque vai te colocar no rumo já com Ágil. Daí, se sua organização decidir adotar BI/DW, você pode fazer o curso de BI com Pentaho e dominar uma das ferramentas de BI/DW mais poderosas e de maior relação custo-benefício da atualidade.
É isso.
Créditos: a imagem do modelo cascata no início deste artigo veio do post Introduzindo e Entendendo Projetos Ágeis (Agile), que fala justamente sobre Ágil e Cascata. Vale a pena ler aquele post.
About author

Você pode gostar também

IA para maiores – Até a matemática pode errar – e a IA pode ajudar a descobrir onde
Desvendando os algoritmos que permitem identificar falhas em sistemas complexos Sem combinarem, dois textos publicados esta semana mostram algo surpreendente: até provas matemáticas podem ter falhas escondidas. E talvez a
Introdução ao MongoDB: aprenda sobre JSON, BSON e primeiros passos
Dando continuidade na série de MongoDB, nesse post farei uma Introdução ao formato “Javascript Object Notation” (JSON), ao BSON e aos primeiros passos com o MongoDB.

Guia Prático: Como Instalar e Configurar o Apache Ambari em um Cluster Hadoop
O Apache Ambari é uma plataforma desenvolvida pela Hortonworks que permite instalar, configurar e monitorar um cluster hadoop em poucos minutos. Neste post irei ensinar como instalar o Ambari em





