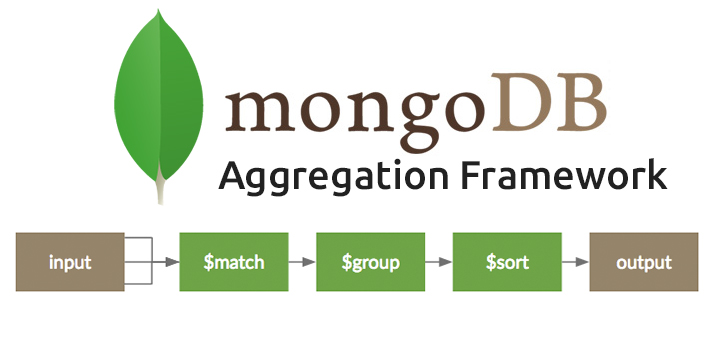
Guia prático: Como otimizar buscas no MongoDB com Aggregate
Descubra como processar documentos distintos agrupados em uma única saída para facilitar a geração de resultados e performance quando preciso efetuar buscas em banco de dados MongoDB
A seguir explicarei vários parâmetros de como utilizar esse recurso e elaborar buscas mais específicas no MongoDB.
(mais…)ยักษ์888สล็อต pgดูหนังออนไลน์ 4kเว็บดูบอลฟรีบ้านผลบอลสล็อตทดลองเล่นฟรีราคาบอลทดลองเล่นสล็อต PGผลบอลสด7m888 ราคาสล็อต
About author

Você pode gostar também

Descubra como o Zabbix automatiza o monitoramento de recursos
Descoberta de baixo nível, ou Low-level discovery (LLD), é um processo que automatiza o registro e monitoramento de recursos pelo Zabbix, ele pode fazer a identificação de métricas em sistemas

Maximize a eficiência da sua infraestrutura com o novo recurso de importação do Terraform
O Terraform pode importar recursos de infraestrutura existentes. Essa funcionalidade permite colocar recursos existentes sob o gerenciamento do Terraform. Isso é muito útil quando estamos iniciando no uso do terraform

IA para maiores – A conta chegou cara e a 4Linux pode te ajudar
Quando a IA virar agente, quanto sua empresa vai pagar por token? 107xOutput tokensFlash vs. GPT-5.5DeepSeek V4 Flash/$0,28 vs $30,00 5–30xMais tokens por tarefaem modo agenteGartner, março 2026 80,6%SWE-bench VerifiedDeepSeek





