
Gerenciamento eficiente de discos em Linux com LVM: Guia passo a passo
O gerenciamento de discos em ambientes linux utilizando o LVM fornece uma visão de alto nível à estrutura de discos presentes em um sistema. Isso dá muito mais flexibilidade na alocação do armazenamento para aplicativos e usuários. Volumes criados usando LVM podem ser redimensionados e movidos quase que à vontade.
Neste post vamos ver como mover um volume group (VG) completo (incluindo seus volumes lógicos) para um outro servidor. Essa é uma técnica que é util em ambientes físicos, virtuais ou até mesmo em ambientes de cloud quando temos um volume muito grande grande que precisa ser movido entre instâncias, por exexmplo um ponto de montagem usado para realização de backups que devem ser movidos e restaurados em outra máquina para se criar um ambiente de dev.
Visão geral do ambiente
Vamos usar a GCP nesse post mas o passo a passo pra mover um VG de um servidor pra outro são os mesmos para qualquer ambiente (físico, virtual, cloud) os passos de “desapresentar” os discos “físicamente” de um servidor e apresentá-los a outro servidor é que vão ser específicos a depender da plataforma que estiver sendo utilizada.
No nosso ambiente de laboratório vamos utilizar duas instâncias CE (Compute Engine): server1 e server2, são duas VMs ubuntu:
gcloud compute instances list

No server1 foram adicionados 3 discos de 30GB:
root@server1:~# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdb 8:16 0 10G 0 disk sdc 8:32 0 10G 0 disk sdd 8:48 0 10G 0 disk root@server1:~#
Esses discos fazem parte do VG (dados) e do LV (backups):
root@server1:~# pvs PV VG Fmt Attr PSize PFree /dev/sdb dados lvm2 a-- <10.00g 0 /dev/sdc dados lvm2 a-- <10.00g 0 /dev/sdd dados lvm2 a-- <10.00g 0 root@server1:~#
root@server1:~# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert backups dados -wi-a----- <29.99g root@server1:~#
O volume está utilizando um sistemas de arquivo xfs e esta montado em /mnt. O xfs é uma boa opção para sitemas de arquivos que tendem a crescer pois permite arquivos de até 500TB e sistemas de arquivos de até 8 EB:
root@server1:~# df -h Filesystem Size Used Avail Use% Mounted on udev 282M 0 282M 0% /dev tmpfs 59M 4.0M 55M 7% /run /dev/sda1 9.7G 1.5G 7.8G 16% / tmpfs 291M 0 291M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 291M 0 291M 0% /sys/fs/cgroup /dev/sda15 124M 5.7M 119M 5% /boot/efi tmpfs 59M 0 59M 0% /run/user/1000 /dev/mapper/dados-backups 30G 63M 30G 1% /mnt root@server1:~#
Vamos criar um pequeno arquivo contendo o backup do nosso diretório /etc, que será movido para o server2, juntamente com o VG:
root@server1:~# tar czf /mnt/backup-etc-server1.tar.gz /etc/ tar: Removing leading `/' from member names root@server1:~# ls -lh /mnt/ total 396K -rw-r--r-- 1 root root 396K Dec 23 12:49 backup-etc-server1.tar.gz root@server1:~#
Novamente, estamos usando discos pequenos apenas a título de exemplo, mas os passos utilizados aqui são os mesmos que podem ser utilizados quando estamos trabalhando com discos de grandes, inclusive é justamente esse o caso de uso mais comum para esse processo, mover grandes quantidades de dados entre servidores rapidamente e com segurança.
Exportando e importando os discos em outro servidor
1. Desmontar o sistema e arquivos:
root@server1:~# umount /mnt/
2. Marcar o volume como inativo:
root@server1:~# vgchange -an dados 0 logical volume(s) in volume group "dados" now active root@server1:~#
3. Exportar o VG:
root@server1:~# vgexport dados Volume group "dados" successfully exported root@server1:~#
4. Via console da GCP “desatachar” os discos do server1:
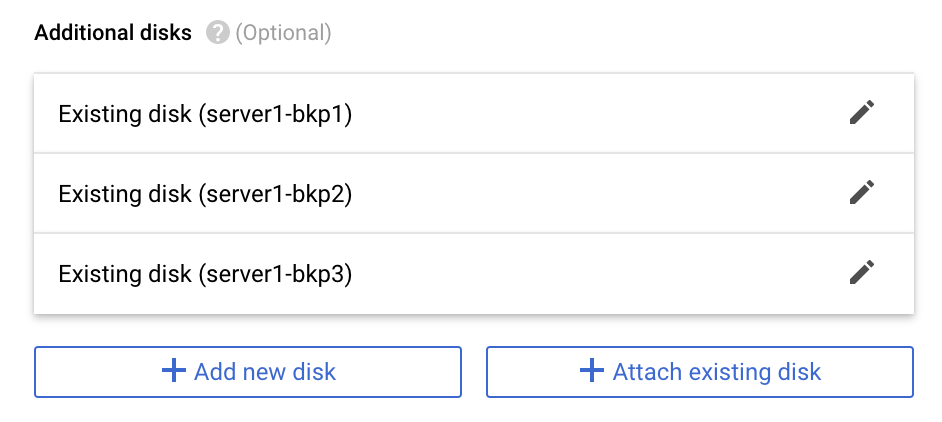
5. Validar que os discos não estão mais apresentados ao server1:
root@server1:~# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 10G 0 disk |-sda1 8:1 0 9.9G 0 part / |-sda14 8:14 0 3M 0 part `-sda15 8:15 0 124M 0 part /boot/efi root@server1:~#
6. Apresentar os discos no server2:
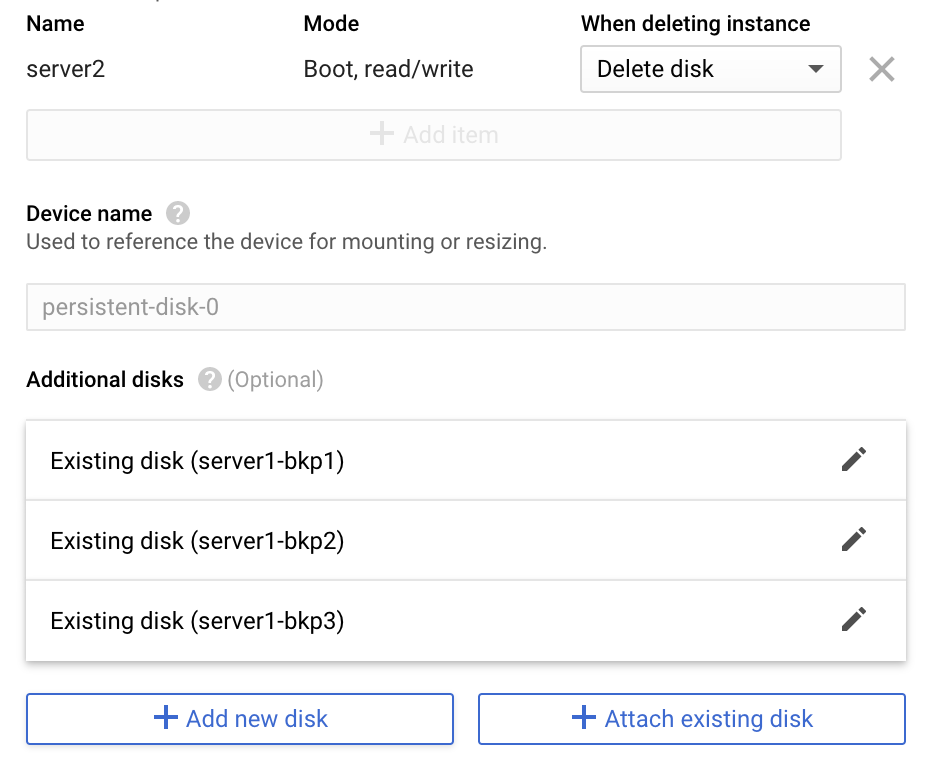
7. Escanear o servidor para validar o volume importado:
root@server2:~# pvscan PV /dev/sdb is in exported VG dados [<10.00 GiB / 0 free] PV /dev/sdd is in exported VG dados [<10.00 GiB / 0 free] PV /dev/sdc is in exported VG dados [<10.00 GiB / 0 free] Total: 3 [<29.99 GiB] / in use: 3 [<29.99 GiB] / in no VG: 0 [0 ] root@server2:~#
8. Importar o volume:
root@server2:~# vgimport dados Volume group "dados" successfully imported root@server2:~#
9. Ativar o volume:
root@server2:~# vgchange -ay dados 1 logical volume(s) in volume group "dados" now active root@server2:~#
10. Montar o sistema de arquivos:
root@server2:~# mount /dev/dados/backups /mnt/ root@server2:~# df -h Filesystem Size Used Avail Use% Mounted on udev 282M 0 282M 0% /dev tmpfs 59M 4.0M 55M 7% /run /dev/sda1 9.7G 1.5G 7.8G 16% / tmpfs 291M 0 291M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 291M 0 291M 0% /sys/fs/cgroup /dev/sda15 124M 5.7M 119M 5% /boot/efi tmpfs 59M 0 59M 0% /run/user/1000 /dev/mapper/dados-backups 30G 64M 30G 1% /mnt root@server2:~#
11. Validar e desempacotar o arquivo de backup:
root@server2:/mnt# tar xzf backup-etc-server1.tar.gz root@server2:/mnt# ls backup-etc-server1.tar.gz etc root@server2:/mnt#
Conclusão
Diferente de quando trabalhamos com volumes pequenos e podemos utilizar, sem grandes preocupações, diversos LVs (Volumes Lógicos) em um mesmo VG, quando estivermos projetando volumes para grandes quantidades de dados é importante pensarmos com cautela a respeito do design dos VGs e LGs, para que possamos utilizar facilidades do LVM como a que tratamos aqui.
Referências
https://tldp.org/HOWTO/LVM-HOWTO/recipemovevgtonewsys.html
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Domine o Linux: Torne-se um Administrador de Sistemas Linux
Linux System Administration Saber como se comportar como um Administrador de Sistemas Linux tornou-se primordial, mas o comportamento não se resume apenas em saber ligar ou desligar, ou até mesmo

Docker BuildX: Otimizando sua Pipeline de Infraestrutura como Código
Transforme seu processo de criação de imagens Docker e eleve sua infraestrutura ao próximo nível com esta extensão poderosa do Docker CLI. Por que ainda usar apenas Docker Build em

Entenda a interação entre MySQL e o cache de sistema de arquivos do Linux
Neste post veremos a interação entre o MySQL e o cache de sistema de arquivos do Linux, principalmente a respeito da configuração do buffer pool do InnoDB. Utilizamos o MySQL






