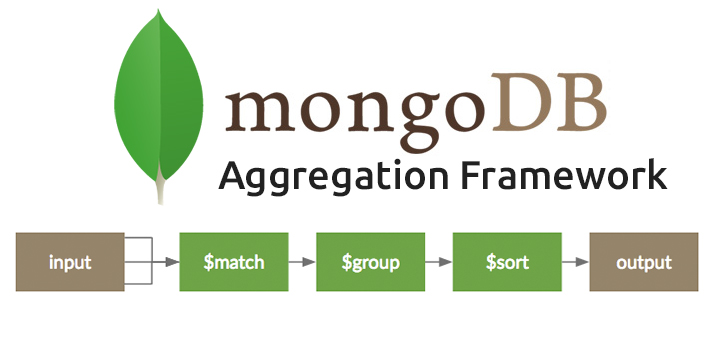
Guia prático: Como otimizar buscas no MongoDB com Aggregate
Descubra como processar documentos distintos agrupados em uma única saída para facilitar a geração de resultados e performance quando preciso efetuar buscas em banco de dados MongoDB
A seguir explicarei vários parâmetros de como utilizar esse recurso e elaborar buscas mais específicas no MongoDB.
(mais…)ยักษ์888สล็อต pgดูหนังออนไลน์ 4kเว็บดูบอลฟรีบ้านผลบอลสล็อตทดลองเล่นฟรีราคาบอลทดลองเล่นสล็อต PGผลบอลสด7m888 ราคาสล็อต
About author

Você pode gostar também

Guia completo: Como instalar e configurar o OCS Inventory
O OCS Inventory é um software de gerência para inventários de dispositivos em rede, com ele é possível registrar todas as características de um computador incluindo: Versão do sistema operacional;

Proteja seu site: aprenda a identificar vulnerabilidades com WhatWeb
Todos nós temos contato direto ou indireto a sites e aplicações web. E, como bem sabemos, essas aplicações são alvos de ataques massivos de hackers e pessoas mau intencionadas. Por

Novidades do PostgreSQL 16
Com o lançamento da nova versão 16 do PostgreSQL, teremos melhorias significativas em seu desempenho, com notáveis aprimoramentos na paralelização de consultas, carregamento em massa de dados e replicação lógica.





