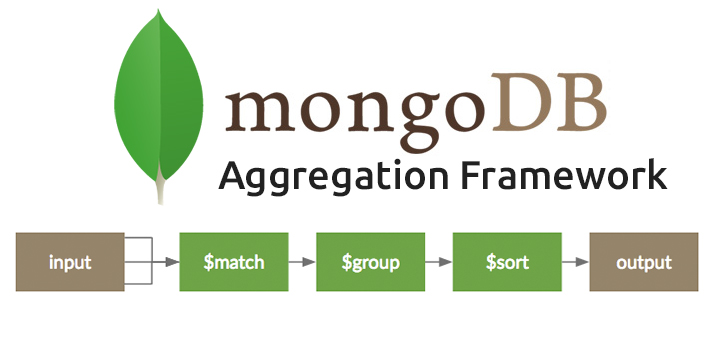
Guia prático: Como otimizar buscas no MongoDB com Aggregate
Descubra como processar documentos distintos agrupados em uma única saída para facilitar a geração de resultados e performance quando preciso efetuar buscas em banco de dados MongoDB
A seguir explicarei vários parâmetros de como utilizar esse recurso e elaborar buscas mais específicas no MongoDB.
(mais…)ยักษ์888สล็อต pgดูหนังออนไลน์ 4kเว็บดูบอลฟรีบ้านผลบอลสล็อตทดลองเล่นฟรีราคาบอลทดลองเล่นสล็อต PGผลบอลสด7m888 ราคาสล็อต
About author

Você pode gostar também

Primeiros passos com o Vault da HashiCorp
O Vault é uma ferramenta de código aberto desenvolvida pela HashiCorp e projetada para ajudar na gestão de segredos e proteção de informações sensíveis em ambientes de computação modernos. Ele

AIOps está revolucionando DevOps: o guia completo para iniciantes
A inteligência artificial está transformando radicalmente as operações de TI, e profissionais júnior de DevOps que dominarem AIOps agora terão salários 20-40% maiores e estarão na vanguarda de uma revolução
Guia Completo: Instalação e Migração do Sistema OTRS na Google Cloud
Introdução OTRS, Open-source Ticket Request System (Sistema Livre de Requisição de Chamados), é um sistema de gerenciamento de incidentes, livre e de código aberto, que qualquer organização pode usar na






