
Gerenciando custos e projetos com Kubernetes, Terraform e AWS
Olá!
Às vezes algumas empresas não têm muito conhecimento em Kubernetes e acabam criando um cluster para cada projeto, o que consequentemente aumenta os custos de forma exponencial e dificulta o gerenciamento do ambiente.
Quando nos deparamos com esse cenário, o melhor caso é criar apenas um cluster, separar os projetos por namespaces e fazer a governança desses namespaces através de grupos.
Nesse post vamos aprender a:
– Criar um cluster de Kubernetes na Amazon utilizando o Terraform
– Criar os namespaces dentro do Cluster utilizando o Terraform
– Gerenciar os acessos aos namespaces também utilizando o Terraform
Para este post, já estou assumindo que você tem o conhecimento básico de AWS, Kubernetes e Terraform.
Todos os códigos utilizados podem ser encontrados nesse repositório:
https://github.com/AlissonMMenezes/eks-terraform
Toda documentação utilizada neste post pode ser encontrada neste link:
https://registry.terraform.io/providers/hashicorp/aws/latest/docs
Então, vamos lá!
O primeiro passo é criar as credenciais que serão utilizadas pelo terraform.
Para isso acesse no console da AWS, Services > IAM > Users > Add User.
No exemplo abaixo estou criando um usuário chamado devops, com permissão programática, ou seja, esse usuário só terá acesso a API da AWS, se alguém pegar as credenciais não poderá acessar o painel.
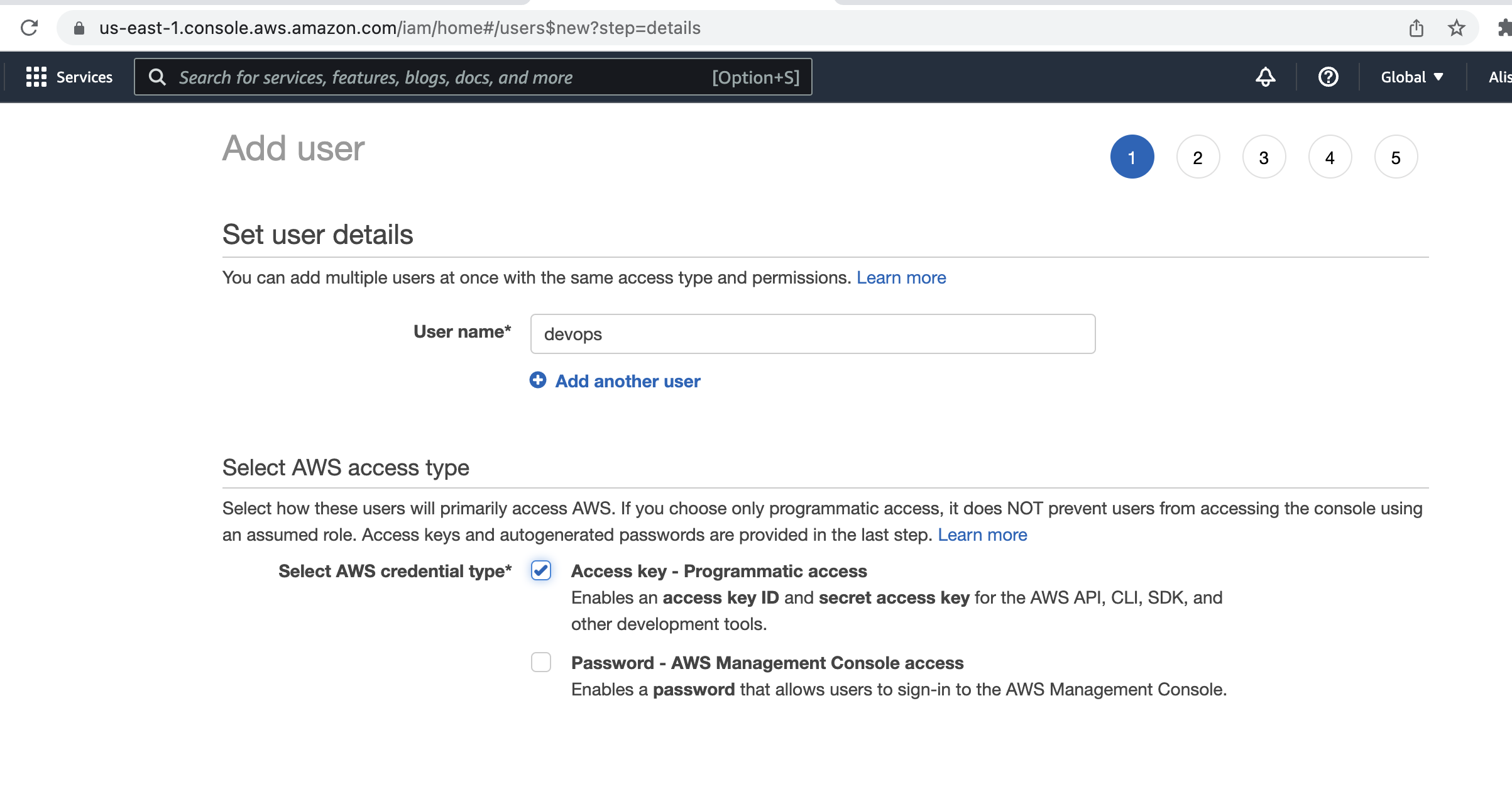
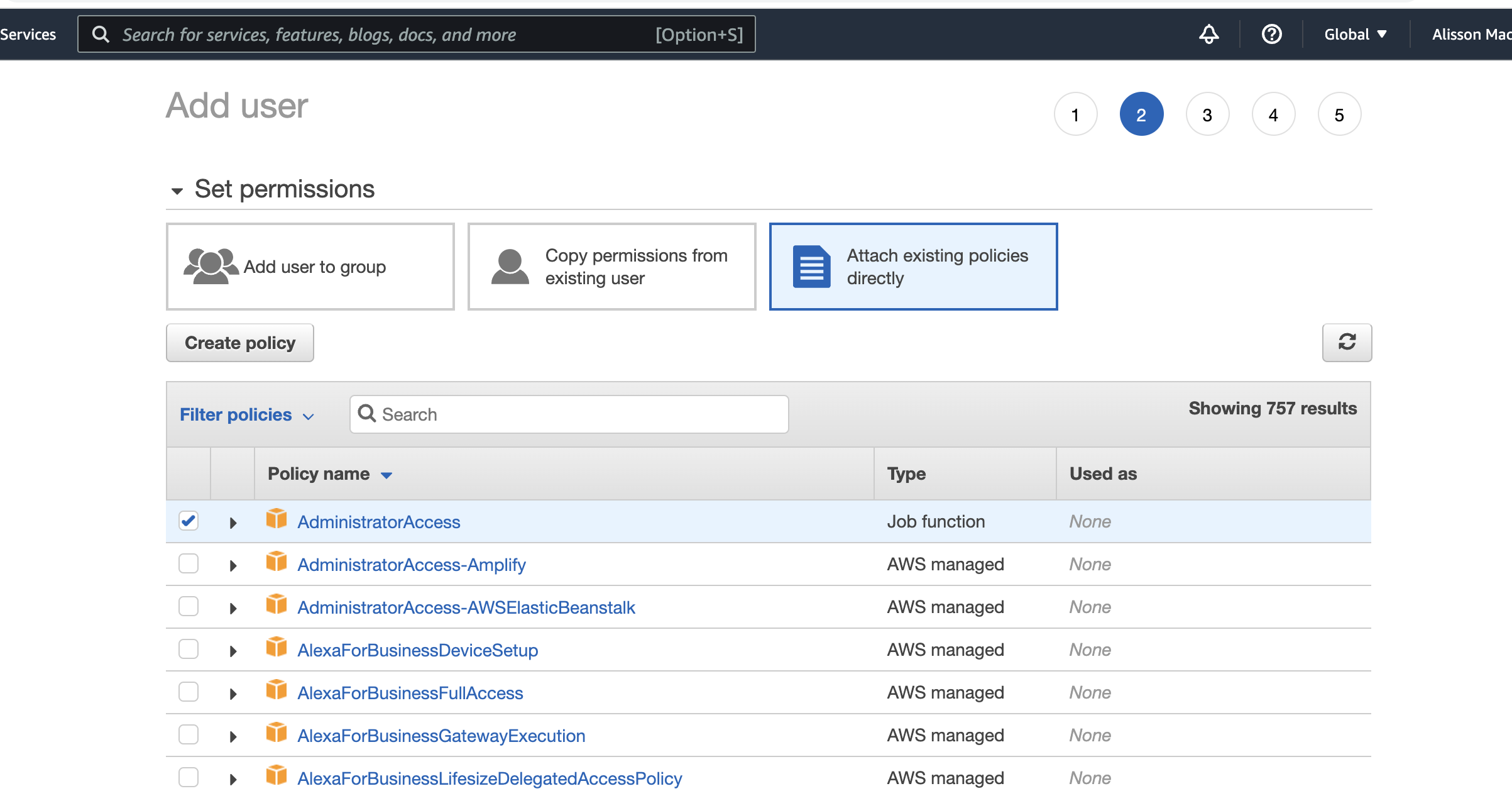
Vou aplicar permissão de administrador para esse usuário, pois após o post vou deletá-lo, então não preciso entrar em detalhes, mas é sempre uma boa prática definir permissões bem específicas e restritas para usuários técnicos.
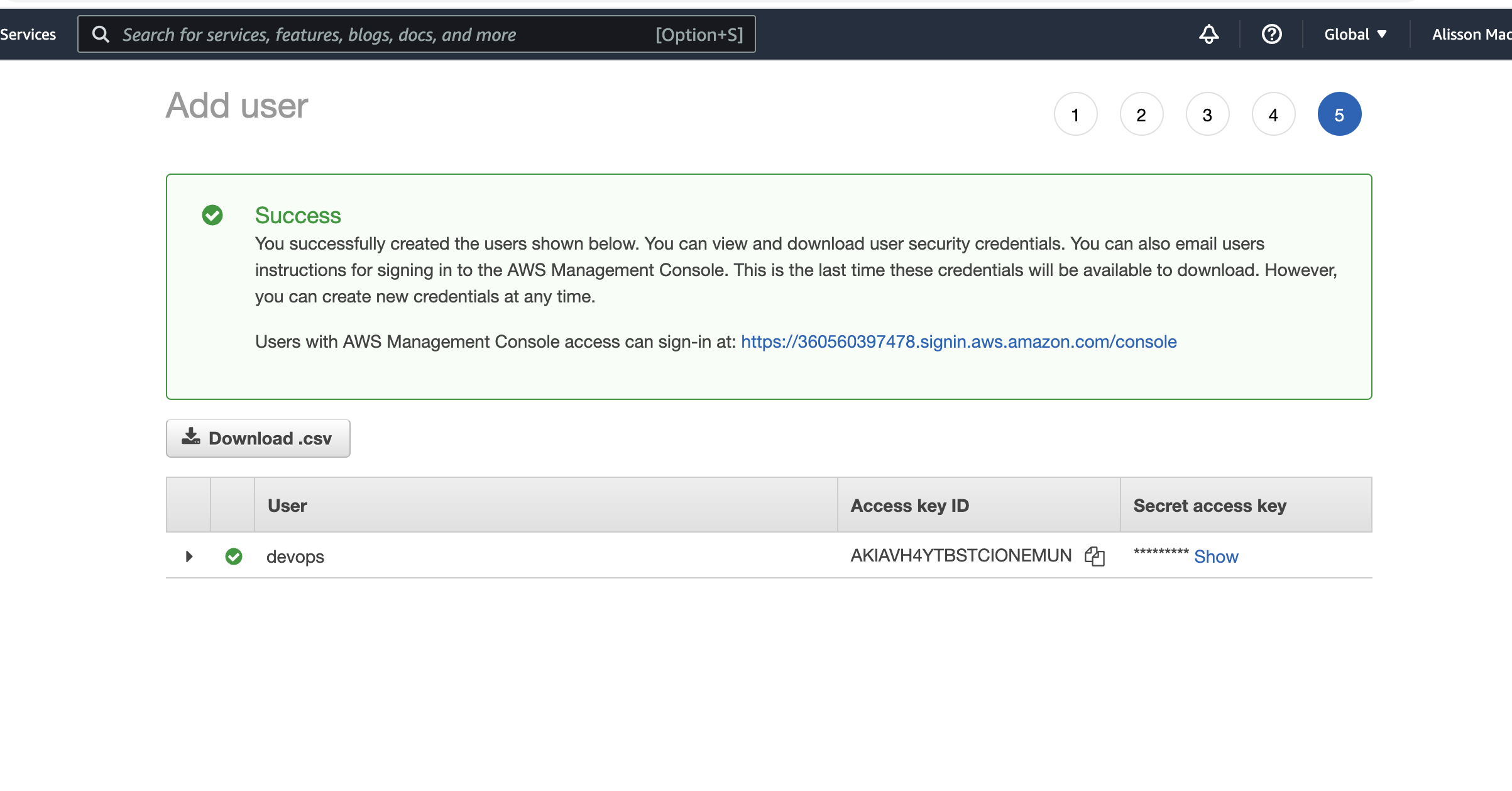
No final você terá o usuário e a senha de acesso, salve isso em seu computador pois vamos precisar.
Crie um arquivo em ~/.aws/credentials .
[default]
aws_access_key_id = SUA_ACCESS_KEY
aws_secret_access_key = SUA_SECRET_GERADA
aws_region = us-east-1
Agora vamos criar um arquivo chamado provider.tf com o seguinte conteúdo:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "4.25.0"
}
}
}
# Configure the AWS Provider
provider “aws” {
shared_credentials_files = [“~/.aws/credentials”]
}
Crie um arquivo chamado main.tf com o seguinte conteúdo:
resource "aws_s3_bucket" "devopss3" {
bucket = "devopsautomations"
}
Primeiro vamos provisionar esse object storage, pois nele vamos guardar os states do terraform.
Execute o terraform init para criar o state localmente e fazer o download dos módulos.
terraform init
Agora aplique as configurações.
$ terraform apply
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only ‘yes’ will be accepted to approve.
Enter a value: yes
aws_s3_bucket.devopss3: Creating…
aws_s3_bucket.devopss3: Creation complete after 9s [id=devopsautomations]
Lembre-se que o nome do s3 bucket tem que ser único, caso contrário, um erro será retornado. O provider da AWS não tem mensagens de erro muito amigáveis, então às vezes pode ser um pouco complicado de encontrar os problemas.
A região em que o s3 bucket será criado é definido automaticamente pela aws, então vamos criar um arquivo chamado output.tf com o seguinte conteúdo.
output "s3_name" {
value = aws_s3_bucket.devopss3.id
}
output “s3_region” {
value = aws_s3_bucket.devopss3.region
}
Agora com o comando terraform refresh, vamos ver as informações.
(base) alissonmachado@Alissons-Air eks-terraform % terraform refresh
aws_s3_bucket.devopss3: Refreshing state... [id=devopsautomations]
Outputs:
s3_name = “devopsautomations”
s3_region = “us-east-1”
Já temos o nome e a região de onde esse bucket foi criado, vamos definir agora dentro do provider.tf a configuração para usar esse s3 como remote backend.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "4.25.0"
}
}
backend “s3” {
bucket = “devopsautomations”
key = “states/tutorial.tfstate”
region = “us-east-1”
}
}
# Configure the AWS Provider
provider “aws” {
shared_credentials_files = [“~/.aws/credentials”]
}
Após mudar a configuração, precisamos rodar o terraform init novamente, para criar o tfstate dentro do s3 bucket.
(base) alissonmachado@Alissons-Air eks-terraform % terraform init
Initializing the backend…
Do you want to copy existing state to the new backend?
Pre-existing state was found while migrating the previous “local” backend to the
newly configured “s3” backend. No existing state was found in the newly
configured “s3” backend. Do you want to copy this state to the new “s3”
backend? Enter “yes” to copy and “no” to start with an empty state.
Enter a value: yes
Successfully configured the backend “s3”! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins…
– Reusing previous version of hashicorp/aws from the dependency lock file
– Using previously-installed hashicorp/aws v4.25.0
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running “terraform plan” to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Ter um arquivo de state remoto é muito importante, pois assim ficamos independentes de configurações locais e as mesmas configurações serão compartilhadas por qualquer máquina que execute o terraform e tenha acesso a esse s3 bucket.
Vamos provisionar um EKS agora.
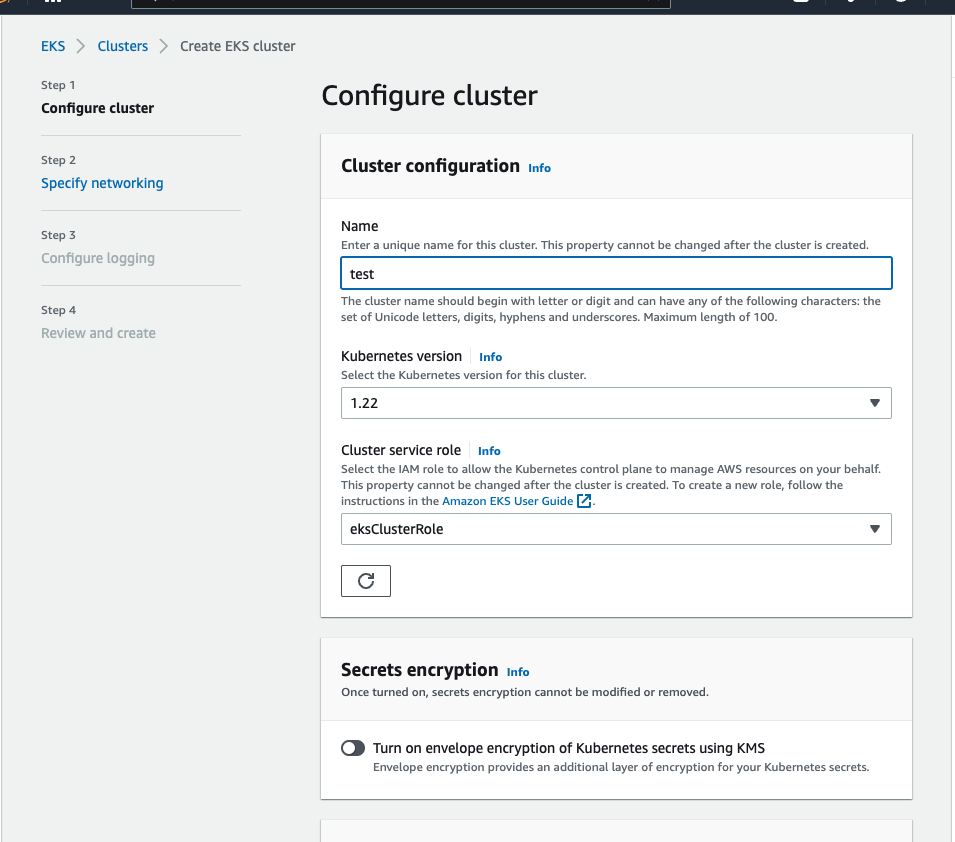
Caso você queira ver o código completo, está aqui neste link:
https://github.com/AlissonMMenezes/eks-terraform
Eu acho importante que você tenha provisionado pelo menos uma vez utilizando o web console da AWS, pois assim você saberá quais são os pré-requisitos para que o cluster seja criado.
– Redes
– Políticas de Acesso
A topologia do nosso cluster será pública + privada, com relação as subnets, essa é a melhor prática de acordo com a documentação da própria AWS.
https://aws.amazon.com/blogs/containers/de-mystifying-cluster-networking-for-amazon-eks-worker-nodes/
Sendo assim, precisamos criar uma VPC, com 2 subnets, uma privada, onde os nodes serão provisionados e uma pública que terá um Nat Gateway e irá permitir com que os nodes acessem a internet.
Vamos criar então um arquivo chamado network.tf com o seguinte conteúdo:
resource "aws_vpc" "eksvpc" {
cidr_block = "10.0.0.0/16"
}
resource “aws_internet_gateway” “gw” {
vpc_id = aws_vpc.eksvpc.id
}
resource “aws_eip” “nat1” {
vpc = true
}
resource “aws_nat_gateway” “natgw1” {
allocation_id = aws_eip.nat1.id
subnet_id = aws_subnet.eks-public-subnet.id
depends_on = [aws_internet_gateway.gw]
}
resource “aws_subnet” “eks-public-subnet” {
# map_public_ip_on_launch = true
availability_zone = “us-east-1a”
cidr_block = “10.0.0.0/24”
vpc_id = aws_vpc.eksvpc.id
tags = tomap({
“kubernetes.io/cluster/4LinuxCluster” = “shared”
“kubernetes.io/role/elb” = 1
})
}
resource “aws_subnet” “eks-private-subnet-1” {
availability_zone = “us-east-1b”
cidr_block = “10.0.1.0/24”
vpc_id = aws_vpc.eksvpc.id
tags = tomap({
“kubernetes.io/cluster/4LinuxCluster” = “shared”
“kubernetes.io/role/internal-elb” = 1
})
}
resource “aws_route_table” “private-route-table” {
vpc_id = aws_vpc.eksvpc.id
route {
cidr_block = “0.0.0.0/0”
nat_gateway_id = aws_nat_gateway.natgw1.id
}
}
resource “aws_route_table” “public-route-table” {
vpc_id = aws_vpc.eksvpc.id
route {
cidr_block = “0.0.0.0/0”
gateway_id = aws_internet_gateway.gw.id
}
}
resource “aws_route_table_association” “route-public” {
subnet_id = aws_subnet.eks-public-subnet.id
route_table_id = aws_route_table.public-route-table.id
}
resource “aws_route_table_association” “route-private” {
subnet_id = aws_subnet.eks-private-subnet-1.id
route_table_id = aws_route_table.private-route-table.id
}
Nele a vpc, as subnets e as tabelas de roteamento foram definidas.
Agora vamos criar as políticas de acesso. Crie um arquivo policies.tf com o seguinte conteúdo:
resource "aws_iam_role" "eksiam" {
name = "eks-devops-role"
assume_role_policy = <<POLICY
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Principal”: {
“Service”: “eks.amazonaws.com”
},
“Action”: “sts:AssumeRole”
}
]
}
POLICY
}
resource “aws_iam_role_policy_attachment” “devopseks-AmazonEKSClusterPolicy” {
policy_arn = “arn:aws:iam::aws:policy/AmazonEKSClusterPolicy”
role = aws_iam_role.eksiam.name
}
resource “aws_iam_role” “eksnodeiam” {
name = “eks-node-role”
assume_role_policy = jsonencode({
Statement = [{
Action = “sts:AssumeRole”
Effect = “Allow”
Principal = {
Service = “ec2.amazonaws.com”
}
}]
Version = “2012-10-17”
})
}
resource “aws_iam_role_policy_attachment” “devopseks-AmazonEKSWorkerNodePolicy” {
policy_arn = “arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy”
role = aws_iam_role.eksnodeiam.name
}
resource “aws_iam_role_policy_attachment” “devopseks-AmazonEKS_CNI_Policy” {
policy_arn = “arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy”
role = aws_iam_role.eksnodeiam.name
}
resource “aws_iam_role_policy_attachment” “devopseks-AmazonEC2ContainerRegistryReadOnly” {
policy_arn = “arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly”
role = aws_iam_role.eksnodeiam.name
}
Os detalhes sobre essas roles podem ser encontrados nessa documentação:
https://docs.aws.amazon.com/eks/latest/userguide/service_IAM_role.html#create-service-role, fica aí de lição de casa para você dar uma lida.
Agora dentro do main.tf adicione o seguinte código:
resource "aws_eks_cluster" "devopseks" {
name = "4LinuxCluster"
role_arn = aws_iam_role.eksiam.arn
vpc_config {
endpoint_private_access = true
endpoint_public_access = true
subnet_ids = [aws_subnet.eks-public-subnet.id, aws_subnet.eks-private-subnet-1.id]
}
depends_on = [
aws_iam_role_policy_attachment.devopseks-AmazonEKSClusterPolicy,
]
}
Esse o código responsável pela criação do cluster.
Crie um arquivo chamado nodes.tf
resource “aws_eks_node_group” “devopseks-nodes” {
cluster_name = aws_eks_cluster.devopseks.name
node_group_name = “Nodes”
node_role_arn = aws_iam_role.eksnodeiam.arn
subnet_ids = [aws_subnet.eks-private-subnet-1.id]
instance_types = [“t3.small”]
scaling_config {
desired_size = 1
max_size = 2
min_size = 1
}
depends_on = [
aws_iam_role_policy_attachment.devopseks-AmazonEKSWorkerNodePolicy,
aws_iam_role_policy_attachment.devopseks-AmazonEKS_CNI_Policy,
aws_iam_role_policy_attachment.devopseks-AmazonEC2ContainerRegistryReadOnly,
]
}
Crie também um arquivo chamado output.tf, que irá nos mostrar alguns detalhes após o provisionamento do cluster.
output "s3_name" {
value = aws_s3_bucket.devopss3.id
}
output “s3_region” {
value = aws_s3_bucket.devopss3.region
}
output “endpoint” {
value = aws_eks_cluster.devopseks.endpoint
}
output “cluster_name” {
value = aws_eks_cluster.devopseks.name
}
E rode o comando terraform apply para provisionar o nosso cluster.
(base) alissonmachado@Alissons-Air eks-terraform % terraform apply -auto-approve=true
aws_eip.nat1: Refreshing state... [id=eipalloc-00d944ccc37cdb78b]
aws_iam_role.eksiam: Refreshing state... [id=eks-devops-role]
aws_iam_role.eksnodeiam: Refreshing state... [id=eks-node-role]
aws_vpc.eksvpc: Refreshing state... [id=vpc-0cc6234bcbd6e7a32]
aws_s3_bucket.devopss3: Refreshing state... [id=devopsautomations]
aws_iam_role_policy_attachment.devopseks-AmazonEC2ContainerRegistryReadOnly: Refreshing state... [id=eks-node-role-20220827131854248300000002]
aws_iam_role_policy_attachment.devopseks-AmazonEKS_CNI_Policy: Refreshing state... [id=eks-node-role-20220827131854453800000003]
aws_iam_role_policy_attachment.devopseks-AmazonEKSWorkerNodePolicy: Refreshing state... [id=eks-node-role-20220827131854023700000001]
aws_iam_role_policy_attachment.devopseks-AmazonEKSClusterPolicy: Refreshing state... [id=eks-devops-role-20220827125328765300000001]
aws_internet_gateway.gw: Refreshing state... [id=igw-0fe9d06f015241079]
aws_subnet.eks-private-subnet-1: Refreshing state... [id=subnet-04b862f3e7a498484]
aws_subnet.eks-public-subnet: Refreshing state... [id=subnet-066be0a668f83f0fe]
aws_route_table.public-route-table: Refreshing state... [id=rtb-0577567364488fc1e]
aws_nat_gateway.natgw1: Refreshing state... [id=nat-0bd8dfd188ec56ca1]
aws_eks_cluster.devopseks: Refreshing state... [id=4LinuxCluster]
aws_route_table_association.route-public: Refreshing state... [id=rtbassoc-0e9602f48325cae3e]
aws_route_table.private-route-table: Refreshing state... [id=rtb-0db2d3958acde2a09]
aws_route_table_association.route-private: Refreshing state... [id=rtbassoc-0f48c6c5b52d59f9b]
aws_eks_node_group.devopseks-nodes: Refreshing state... [id=4LinuxCluster:Nodes]
Assim que o cluster é provisionado, o usuário que criou já é adicionado como admin, então execute o seguinte comando para logar no seu k8s.
aws eks --region us-east-1 update-kubeconfig --name 4LinuxCluster
E veja se você consegue listar os pods.
(base) alissonmachado@Alissons-Air eks-terraform % kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system aws-node-bswct 1/1 Running 0 44m
kube-system coredns-7f5998f4c-f7l5k 1/1 Running 0 50m
kube-system coredns-7f5998f4c-t5xsb 1/1 Running 0 50m
kube-system kube-proxy-27bnk 1/1 Running 0 44m
Pronto! o nosso cluster está no ar e rodando, vamos agora gerenciar a governança.
Primeiro passo será criar os namespaces por projeto.
Dentro do arquivo main.tf adicionei o seguinte código:
resource "kubernetes_namespace" "projects-namespaces" {
for_each = toset(["poc", "mvp", "crm"])
metadata {
name = each.value
}
}
Esse código irá criar 3 namespaces, poc, mvp e crm. Que são equivalentes aos nomes dos projetos na empresa.
Criei um segundo arquivo chamado governance.tf com o seguinte código.
resource "kubernetes_role" "crm-developers-role" {
metadata {
name = "crm-developers"
namespace = "crm"
}
rule {
api_groups = [“”]
resources = [“*”]
verbs = [“*”]
}
}
resource “kubernetes_role_binding” “crm-role-bind-users” {
metadata {
name = “crm-developers-role-binding”
namespace = “crm”
}
subject {
kind = “Group”
name = “crm-developers-group”
api_group = “rbac.authorization.k8s.io”
}
role_ref {
api_group = “rbac.authorization.k8s.io”
kind = “Role”
name = “crm-developers”
}
}
resource “kubernetes_config_map” “aws-config-map” {
metadata {
name = “aws-auth”
namespace = “kube-system”
}
data = {
mapRoles = <<EOF
null
EOF
mapUsers = <<EOF
– groups:
– crm-developers-group
userarn: arn:aws:iam::360560397478:user/alisson-machado
username: alisson-machado
EOF
}
}
Nesse código estou criando uma Role dentro do Kubernetes chamado crm-developers, assim, todos os usuários que forem adicionados a essa role podem fazer tudo dentro do namespace crm.
Após isso, temos o role_binding, que irá criar um grupo chamado crm-developers-group, esse grupo será associado a role, assim todos os usuários que forem adicionados nesse grupo, terão as mesmas permissões.
No final temos o configmap aws-auth, esse configmap é exclusivo da AWS, ele é criado durante a criação do cluster e precisamos editá-lo para adicionar os usuários que forem criados dentro do IAM da AWS.
No meu caso, criei um usuário chamado alisson-machado e o adicionei dentro desse configmap, pertencendo ao grupo crm-developers-group, que foi criado no bloco anterior.
O meu provider.tf ficou da seguinte forma:
terraform {
required_providers {
kubernetes = {
source = "hashicorp/kubernetes"
version = "2.13.0"
}
}
backend "s3" {
bucket = "devopsautomations"
key = "states/k8s.tfstate"
region = "us-east-1"
}
}
provider “kubernetes” {
config_path = “~/.kube/config”
}
Assim o terraform utilizará das minhas configurações locais para conectar ao kubernetes.
Execute.
terraform init
Para baixar os módulos.
Como o configmap da aws já está criado dentro do cluster, precisamos fazer um import antes de executar as nossas alterações.
terraform import kubernetes_config_map.aws-config-map kube-system/aws-auth
kubernetes_config_map.aws-config-map: Importing from ID "kube-system/aws-auth"...
kubernetes_config_map.aws-config-map: Import prepared!
Prepared kubernetes_config_map for import
kubernetes_config_map.aws-config-map: Refreshing state... [id=kube-system/aws-auth]
Import successful!
The resources that were imported are shown above. These resources are now in
your Terraform state and will henceforth be managed by Terraform.
Agora voce pode executar.
terraform apply
O usuário alisson-machado que foi criado, só precisa ter a seguinte policy dentro do IAM para acessar o cluster.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "eks:DescribeCluster",
"Resource": "*"
}
]
}
Fora isso, tudo será gerenciado dentro do próprio Kubernetes.
Agora, vamos testar os acessos.
Validando o usuário logado:
root@debian:~# aws sts get-caller-identity
{
“UserId”: “AIDAVH4YTBSTHF3Q64CW5”,
“Account”: “360560397478”,
“Arn”: “arn:aws:iam::360560397478:user/alisson-machado”
}
Adicionando o cluster ao meu kubeconfig.
aws eks --region us-east-1 update-kubeconfig --name 4LinuxCluster
Added new context arn:aws:eks:us-east-1:360560397478:cluster/4LinuxCluster to /root/.kube/config
Testando ver os pods do namespace default.
root@debian:~# kubectl get pods
Error from server (Forbidden): pods is forbidden: User "alisson-machado" cannot list resource "pods" in API group "" in the namespace "default"
Legal, não temos permissão.
Testando do namespace crm.
root@debian:~# kubectl get pods -n crm
No resources found in crm namespace.
Perfeito, podemos listar, mas como não fizemos nenhum deploy, o namespace está vazio.
Vamos testar agora no namespace poc.
root@debian:~# kubectl get pods -n poc
Error from server (Forbidden): pods is forbidden: User "alisson-machado" cannot list resource "pods" in API group "" in the namespace "poc"
Não temos permissão para ver nada no namespace poc.
Então tudo foi configurado corretamente.
Agora você já sabe como criar o cluster, os usuários e aplicar as permissões.
Sinta-se à vontade para executar novos testes e fazer a governança do seu cluster =)
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Entenda o que é um Framework e como ele pode facilitar seus projetos digitais
Se você tem um projeto web ou aplicativo a desenvolver, saber o que é um framework é um conhecimento indispensável. Afinal, estamos falando sobre um elemento chave para o resultado

Por que aprender Python? Descubra os motivos e vantagens
Dizem que se alguém quer trabalhar no Google, o caminho mais simples é aprender Python. Será este o único motivo? De fato, a linguagem Python é intensivamente usada pelo Google.

Testando e validando suas Roles do Ansible com o Molecule
Hoje, no blog da 4Linux, vamos falar sobre como podemos testar as nossas Roles antes de serem aplicadas no ambiente de produção. O Molecule é um projeto que permite que





