
Guia completo: Implantação de MongoDB resiliente no Google Kubernetes Engine
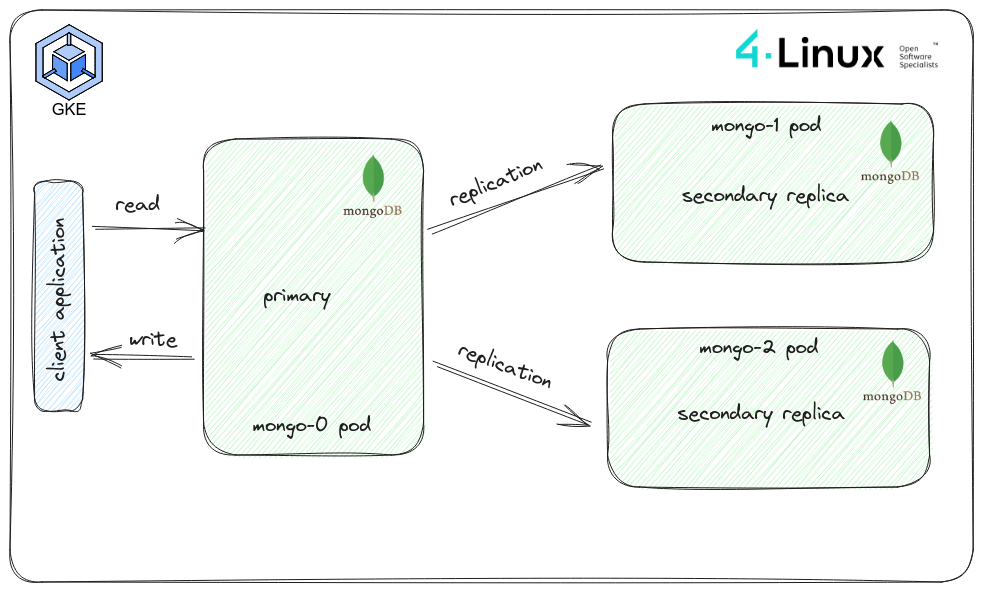
Este guia aborda a implantação de um MongoDB resiliente no GKE, incluindo etapas para configurar um StatefulSet, serviço headless e inicializar o conjunto réplica. Aprenda a utilizar recursos do GKE para garantir a disponibilidade e desempenho do banco de dados.
Por que escolher o GKE?
O GKE é um excelente serviço gerenciado de Kubernetes que facilita a implantação, o gerenciamento e o escalonamento de aplicações em contêineres. Sua infraestrutura flexível e resistente o torna ideal para bancos de dados como o MongoDB.
Configurando um conjunto réplica MongoDB no GKE
Objetivo
Estabelecer um conjunto stateful tolerante a falhas do MongoDB com três réplicas: O objetivo é criar e configurar um conjunto stateful do MongoDB, que inclua um nó primário e dois nós secundários, garantindo assim maior disponibilidade e resiliência às falhas no sistema de banco de dados.
Pré-requisitos:
- Conta do Google Cloud Platform (GCP): Você precisa de uma conta GCP ativa para criar e gerenciar recursos do GKE;
- Projeto GCP configurado: Um projeto GCP configurado é necessário para usar os recursos do Google Kubernetes Engine;
- Instalação do SDK do Google Cloud: Instale o SDK do Google Cloud em sua máquina local para executar comandos gcloud e interagir com o GCP;
- Conhecimento básico de Kubernetes: Familiarize-se com os conceitos básicos do Kubernetes, como Pods, ReplicaSets, StatefulSets e Services;
- Conhecimento básico de MongoDB: Entenda os conceitos básicos do MongoDB, como conjuntos de réplicas e operações de leitura/escrita;
- Ferramentas kubectl e mongosh: Instale a ferramenta de linha de comando kubectl para gerenciar clusters e recursos do Kubernetes, e a ferramenta mongosh para interagir com o MongoDB.
StatefulSet: O que é e por que usá-lo?
O StatefulSet é um controlador de gerenciamento de cargas de trabalho no Kubernetes que é usado para gerenciar aplicações stateful. Ao contrário de aplicações sem estado, onde cada instância é idêntica e pode ser substituída sem impacto, as aplicações stateful têm dados ou estados que precisam ser preservados entre as reinicializações, atualizações ou falhas.
- Identidade Estável dos Pods:
Cada pod em um StatefulSet tem um nome e identidade estáveis, como mongodb-0, mongodb-1 etc.
Isso significa que mesmo se um pod for reiniciado, ele manterá o mesmo nome e identidade.
Essa identidade estável é crucial para o MongoDB, pois permite que os membros do conjunto réplica se reconheçam e se comuniquem de maneira consistente. - Armazenamento Persistente:
StatefulSets permitem a criação de volumes persistentes que são vinculados a cada pod.
Isso garante que os dados armazenados no MongoDB sejam mantidos mesmo quando o pod é reiniciado ou movido para outro nó no cluster.
A persistência dos dados é essencial para um banco de dados como o MongoDB, onde a integridade e disponibilidade dos dados são fundamentais. - Manutenção do Estado:
StatefulSets garantem que os pods mantenham seu estado mesmo após falhas ou atualizações.
Isso é particularmente útil para o MongoDB, que depende da manutenção do estado para funcionar corretamente.
Em caso de falha, o Kubernetes pode reiniciar automaticamente os pods com falha e manter a continuidade do estado e dos dados entre os reinícios. - Ordem de Implantação e Atualização:
StatefulSets garantem uma ordem específica para a implantação e atualização dos pods.
Isso é vital para o MongoDB, onde a ordem de inicialização e atualização dos membros do conjunto réplica pode ser crítica para a consistência e disponibilidade dos dados. - Gerenciamento de Configuração:
StatefulSets permitem a configuração e gerenciamento centralizados dos pods.
Isso facilita a configuração e manutenção do MongoDB em um ambiente de cluster, permitindo alterações consistentes e controladas.
Entendendo o comportamento das Réplicas.
Suponha o seguinte cenário:
Quando mongodb-0 ficar indisponível, o conjunto réplica detectará essa falha e iniciará um processo de eleição para escolher um novo primário entre as réplicas secundárias disponíveis, neste caso, mongodb-1 e mongodb-2.
Ambas as réplicas mongodb-1 e mongodb-2 têm prioridade igual (1), então ambas têm a mesma probabilidade de serem eleitas como primárias. Uma delas será escolhida como a nova réplica primária, e a outra permanecerá como secundária.
Durante a indisponibilidade de mongodb-0, a nova réplica primária (seja mongodb-1 ou mongodb-2) será responsável por todas as operações de leitura e gravação, enquanto a outra réplica secundária continuará a lidar com operações de leitura.
Quando mongodb-0 ficar disponível novamente, ele se juntará ao conjunto réplica como uma réplica secundária e começará a sincronizar-se com a réplica primária atual, copiando todos os dados e operações que ocorreram durante sua indisponibilidade.
Como a prioridade de mongodb-0 é maior que as das outras réplicas, quando ocorrer uma nova eleição de primário (por exemplo, devido a uma reinicialização do nó primário atual, falha ou manutenção programada), mongodb-0 tem maior probabilidade de ser eleito como primário novamente, assumindo as operações de leitura e gravação. Enquanto isso, as outras duas réplicas voltarão a atuar como réplicas secundárias, lidando com operações de leitura.
É importante notar que, embora mongodb-0 tenha maior prioridade, a eleição do primário depende de vários fatores, como o tempo de resposta e o estado de sincronização dos nós. Portanto, é possível que mongodb-0 não seja eleito imediatamente como primário, mesmo que tenha a maior prioridade, especialmente se não estiver totalmente sincronizado com o primário atual.
Entendo Persistência de dados usando PVC
A utilização do PersistentVolumeClaim (PVC) é crucial para garantir que os dados do MongoDB sejam armazenados de maneira segura e persistente. Sem um PVC, os dados do MongoDB seriam armazenados no contêiner e seriam perdidos caso o contêiner fosse excluído ou realocado.
A storageclass standard com o provisioner kubernetes.io/gce-pd indica que os volumes persistentes serão provisionados usando o Google Compute Engine Persistent Disk (GCE-PD). O GCE-PD é um serviço de armazenamento em disco persistente, escalonável e de alta performance, adequado para armazenar os dados do MongoDB.
– volumeMounts:
– name: mongodb-data
mountPath: /data/db
Aqui, o volume mongodb-data é montado nos respectivos caminhos especificados. O volume mongodb-data será usado para armazenar os dados do MongoDB.
– volumeClaimTemplates:
– metadata:
name: mongodb-data
spec:
accessModes: [“ReadWriteOnce”]
storageClassName: standard
resources:
requests:
storage: 10Gi
Esse trecho define o PersistentVolumeClaim (PVC) que será utilizado para armazenar os dados do MongoDB. O PVC tem o nome mongodb-data e solicita um volume de 10Gi com acesso no modo ReadWriteOnce. O PVC utiliza a storageclass standard mencionada anteriormente, que está configurada para provisionar volumes utilizando o GCE-PD.
Ao configurar um PVC, você garante que os dados do MongoDB sejam armazenados em um disco persistente, mesmo se o contêiner ou pod forem recriados ou movidos. Isso é fundamental para garantir a integridade e disponibilidade dos dados em um ambiente de produção.
Entendendo command no MongoDB
Os comandos fornecidos ao MongoDB através do argumento command são usados para configurar e controlar o comportamento do servidor do MongoDB quando ele é iniciado. Utilizar comandos no MongoDB permite ajustar o funcionamento do servidor de acordo com as necessidades específicas do seu aplicativo ou ambiente. Esses comandos também ajudam a garantir que o MongoDB esteja devidamente configurado para operar em um ambiente de produção.
– command:
– mongod
– “–replSet=rs0”
– “–bind_ip_all”
– “–wiredTigerCacheSizeGB=1”
– “–oplogSize=128”
- mongod: É o processo principal do MongoDB que atua como servidor de banco de dados. Ele precisa ser especificado como o primeiro comando para iniciar o processo do MongoDB.
- –replSet=rs0: Este comando configura o nome do conjunto de réplicas como rs0. Os conjuntos de réplicas permitem que o MongoDB forneça alta disponibilidade e recuperação de dados. Definir um conjunto de réplicas é especialmente importante ao implantar um cluster do MongoDB em um ambiente de produção.
- –bind_ip_all: Este comando permite que o servidor do MongoDB aceite conexões de qualquer endereço IP. Isso é útil para garantir que outros contêineres ou serviços no cluster do Kubernetes possam se comunicar com o servidor do MongoDB,
- –wiredTigerCacheSizeGB=1: Este comando ajusta o tamanho do cache do WiredTiger para 1 GB. O WiredTiger é o mecanismo de armazenamento padrão do MongoDB e controla como os dados são armazenados em disco. Ajustar o tamanho do cache do WiredTiger pode afetar o desempenho do servidor, então essa configuração deve ser ajustada de acordo com as necessidades específicas do seu aplicativo.
- –oplogSize=128: Este comando define o tamanho do oplog (registro de operações) para 128 MB. O oplog é usado pelos membros do conjunto de réplicas para se manterem sincronizados uns com os outros. Ajustar o tamanho do oplog pode afetar a quantidade de espaço necessário para armazenar os dados e a quantidade de tempo necessário para recuperar dados no caso de uma falha.
Utilizar comandos no MongoDB permite ajustar e otimizar o servidor para as necessidades específicas do seu aplicativo ou ambiente. É uma prática recomendada configurar o MongoDB com base nas melhores práticas e nas necessidades específicas do seu projeto para garantir o melhor desempenho e confiabilidade.
Entendendo Secrets
env:
– name: MONGODB_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: mongodb-admin-secret
key: username
– name: MONGODB_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mongodb-admin-secret
key: password
MONGODB_INITDB_ROOT_USERNAME e MONGODB_INITDB_ROOT_PASSWORD para o MongoDB. são variáveis utilizadas durante a inicialização do MongoDB para criar um usuário administrativo (root) com as credenciais fornecidas. Em vez de fornecer os valores diretamente no arquivo de configuração, as credenciais são armazenadas em um objeto Secret do Kubernetes, que permite uma gestão mais SEGURA e centralizada das informações sensíveis.
Criando a Secret
Primeiro vamos criar uma Secret que será associada ao StatefulSet. Para criar uma Secret chamada mongodb-admin-secret, siga as etapas abaixo:
Primeiro, crie um arquivo YAML chamado mongodb-admin-secret.yaml com o seguinte conteúdo:
apiVersion: v1
kind: Secret
metadata:
name: mongodb-admin-secret
type: Opaque
data:
username: <base64_encoded_username>
password: <base64_encoded_password>
Substitua <base64_encoded_username> e <base64_encoded_password> pelos valores codificados em base64 do nome de usuário e senha desejados para o usuário administrativo do MongoDB. Por exemplo, se o nome de usuário for admin e a senha for mypassword, codifique-os em base64 e substitua no arquivo YAML.
Você pode usar uma ferramenta online ou a linha de comando para codificar os valores em base64. Aqui está um exemplo usando a linha de comando:
echo -n ‘admin’ | base64
echo -n ‘mypassword’ | base64
Depois de atualizar o arquivo YAML com os valores codificados em base64, crie o objeto Secret no cluster Kubernetes executando o seguinte comando:
kubectl apply -f mongodb-admin-secret.yaml
Com o Secret criado, as credenciais estarão disponíveis para serem utilizadas pelo StatefulSet do MongoDB. As variáveis de ambiente são definidas no arquivo de configuração do StatefulSet usando o valueFrom com o secretKeyRef. Isso permite que o contêiner acesse as credenciais armazenadas no objeto Secret sem expô-las diretamente no arquivo de configuração, melhorando a segurança das informações sensíveis.
Dessa forma, o contêiner do MongoDB pode ler as credenciais a partir do Secret e utilizá-las para configurar o usuário administrativo durante a inicialização.
Criando StatefulSet para pods do MongoDB
O uso de um StatefulSet para implantar o MongoDB no Kubernetes oferece várias vantagens em comparação a outras abordagens, como Deployments. As principais razões para usar um StatefulSet para o MongoDB incluem a garantia de identidade estável dos pods, armazenamento persistente e manutenção do estado em caso de falha ou reinicialização.
- Identidade estável dos pods: Os StatefulSets garantem que os pods tenham identificadores únicos e estáveis. Por exemplo, se você tiver três réplicas, elas serão chamadas mongodb-0, mongodb-1 e mongodb-2. Esses identificadores permitem que os pods do MongoDB sejam facilmente reconhecidos e localizados no cluster, facilitando a comunicação entre os membros do conjunto de réplicas e a configuração das réplicas secundárias.
- Armazenamento persistente: O StatefulSet garante a criação de volumes persistentes associados a cada pod, garantindo que os dados armazenados neles sejam mantidos mesmo quando o pod é reiniciado ou movido para outro nó no cluster. Isso é especialmente importante para um banco de dados como o MongoDB, onde a persistência dos dados é essencial para garantir a disponibilidade e a confiabilidade dos dados.
- Manutenção do estado: Ao utilizar StatefulSets, os pods do MongoDB mantêm seu estado mesmo após falhas ou atualizações. Isso significa que, em caso de falha, o Kubernetes pode reiniciar automaticamente os pods com falha e manter a continuidade do estado e dos dados entre os reinícios. Isso é particularmente útil para aplicativos de banco de dados, como o MongoDB, que dependem de manter o estado para funcionar corretamente.
Em resumo, o uso de um StatefulSet para implantar o MongoDB no Kubernetes oferece uma série de vantagens que melhoram a confiabilidade, a disponibilidade e a escalabilidade do banco de dados. Essas características são especialmente importantes para garantir o desempenho ideal e a operação contínua de aplicativos de banco de dados em ambientes de produção.
Crie um arquivo YAML chamado mongo-statefulset.yaml com o seguinte conteúdo:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongodb
spec:
serviceName: mongodb
replicas: 3
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
– name: mongodb
env:
– name: MONGODB_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: mongodb-admin-secret
key: username
– name: MONGODB_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mongodb-admin-secret
key: password
image: mongo:5.0
command:
– mongod
– “–replSet=rs0”
– “–bind_ip_all”
– “–wiredTigerCacheSizeGB=1”
– “–oplogSize=128”
ports:
– containerPort: 27017
volumeMounts:
– name: mongodb-data
mountPath: /data/db
– name: my-data
mountPath: /etc
resources:
limits:
memory: 2Gi
volumeClaimTemplates:
– metadata:
name: mongodb-data
spec:
accessModes: [“ReadWriteOnce”]
storageClassName: standard
resources:
requests:
storage: 10Gi
Para criar o StatefulSet, execute o seguinte comando:
kubectl apply -f mongo-statefulset.yaml
Isso criará um StatefulSet para os pods do MongoDB usando a configuração especificada no arquivo YAML. Você pode verificar se o StatefulSet foi criado com sucesso executando o comando:
kubectl get statefulsets
O comando exibirá o StatefulSet que acabou de criar
Criando um serviço para os pods MongoDB
Criar um serviço headless para os pods MongoDB no Kubernetes é útil quando você deseja acessar diretamente os pods individuais usando seus nomes de host. Para criar um serviço headless, crie um arquivo YAML chamado mongo-service.yaml e inclua o seguinte conteúdo:
apiVersion: v1
kind: Service
metadata:
name: mongodb
labels:
app: mongodb
spec:
ports:
– port: 27017
targetPort: 27017
clusterIP: None
selector:
app: mongodb
Neste arquivo YAML, a seção de metadados especifica o nome do serviço como mongodb-headless. A seção de seleção especifica que o serviço deve ser direcionado para os pods com o rótulo app: mongodb.
A seção de portas especifica que o serviço deve escutar na porta 27017, que é a porta padrão para o MongoDB, e encaminhar o tráfego para a mesma porta nos pods. O campo clusterIP definido como None indica que este é um serviço headless.
Finalmente, o campo type é definido como ClusterIP para especificar que o serviço deve ser exposto dentro do cluster.
Depois de criar o arquivo YAML, você pode criar o serviço headless executando o seguinte comando:
kubectl apply -f mongo-service.yaml
Inicializar o conjunto réplica MongoDB
Para acessar o shell MongoDB, use o comando exec para se conectar a um pod específico. Por exemplo, para entrar no shell do MongoDB no pod mongodb-0, execute o seguinte comando:
kubectl exec -it mongodb-0 — mongosh
Depois de entrar com sucesso no shell do MongoDB do pod mongodb-0 usando o comando exec, inicie o conjunto réplica usando os seguintes comandos. Certifique-se de inserir cada linha, uma por uma, e substitua os valores reservados pelo nome do conjunto réplica criado no arquivo mongo-statefulset.yaml, bem como os nomes de host dos réplicas primário e secundário (todos os pods criados pelo arquivo mongo-statefulset.yaml):
Execute o seguinte comando no shell do mongo:
rs.initiate({
“_id”:”rs0″,
“members”:[
{
“_id”:0,
“host”:”<pod-name>.<replica-set-name>.<namespace>.svc.cluster.local:27017″
},
{
“_id”:1,
“host”:”<pod-name>.<replica-set-name>.<namespace>.svc.cluster.local:27017″
},
{
“_id”:2,
“host”:”<pod-name>.<replica-set-name>.<namespace>.svc.cluster.local:27017″
}
]
})
O comando rs.initiate() inicializa o conjunto réplica com o objeto de configuração fornecido. O campo _id deve corresponder ao nome do conjunto réplica fornecido no arquivo mongo-statefulset.yaml. O campo members deve ser um array de objetos representando cada réplica no conjunto. O campo host deve estar no formato <pod-name>.<replica-set-name>.<namespace>.svc.cluster.local:<port>. Neste caso, a porta é 27017, que é a porta padrão para o MongoDB. Depois que o comando rs.initiate() for executado com sucesso, você verá a saída ok: 1 confirmando que o conjunto réplica foi iniciado.
Configurando PRIORITY
Já explicamos a prioridade como funciona em Entendendo o comportamento das Réplicas. Vamos apenas entender os comandos executados aqui:
- cfg = rs.conf(): Este comando obtém a configuração atual do conjunto réplica e armazena-a na variável cfg.
- cfg.members[0].priority = 2: Define a prioridade do primeiro membro (índice 0) do conjunto réplica para 2. Um valor mais alto indica maior prioridade na eleição de primário.
- cfg.members[1].priority = 1: Define a prioridade do segundo membro (índice 1) do conjunto réplica para 1. Um valor mais baixo indica menor prioridade na eleição de primário.
- cfg.members[2].priority = 1: Define a prioridade do segundo membro (índice 2) do conjunto réplica para 1. Um valor mais baixo indica menor prioridade na eleição de primário.
- rs.reconfig(cfg): Aplica a nova configuração armazenada na variável cfg ao conjunto réplica.
Execute o comando abaixo para configurar o chaveamento entre primário e secundário:
cfg = rs.conf()
cfg.members[0].priority = 2
cfg.members[1].priority = 1
cfg.members[2].priority = 1
rs.reconfig(cfg)
Criando um Banco de Dados e Collection
Para criar um novo banco e collection basta executar:
use db-test
db.createCollection(“MyCollection”)
Isso resultará na criação de um banco de dados chamado db-test e uma coleção chamada MyCollection no pod primário.
Assim que o banco de dados e a coleção forem criados, a replicação iniciará automaticamente. Para verificar isso, saia do shell do MongoDB e utilize o comando kubectl exec para acessar um dos pods secundários. Por exemplo, execute o seguinte comando para entrar no shell do MongoDB no pod mongodb-1:
kubectl exec -it mongodb-1 — mongosh
rs0 [direct: secondary] test >use db-test
switched to db db-test
rs0 [direct: secondary] db-test>show collections
MyCollection
Criar um usuário com a função UserAdminAnyDatabase.
Isso permite que você gerencie qualquer banco de dados no servidor.
db.createUser({
“user”:”USUARIO”,
“pwd”:”PASSWORD”,
“roles”:[
{
“role”:”userAdminAnyDatabase”,
“db”:”admin”
}
]
})
Criar usuário para um Banco de Dados.
db.createUser({
user: “app”,
pwd: “PASSWORD”,
roles: [
{ role: “readWrite”, db: “app” }
]
})
Conclusão
Este artigo apresenta um guia completo para implantar e configurar um conjunto replicado do MongoDB no Google Kubernetes Engine (GKE) usando um StatefulSet. Ao utilizar o GKE, os desenvolvedores podem tirar proveito de sua escalabilidade, gerenciamento e recursos avançados para garantir o desempenho e a confiabilidade do banco de dados MongoDB.
A criação de um conjunto replicado com um pod primário e dois pods secundários fornece tolerância a falhas e balanceamento de carga, melhorando a disponibilidade do banco de dados. Além disso, o uso de StatefulSets e PersistentVolumeClaims assegura a persistência dos dados e a capacidade de gerenciar eficientemente aplicações stateful como o MongoDB no ambiente Kubernetes.
Seguindo as etapas detalhadas neste artigo, você poderá configurar, implantar e gerenciar seu banco de dados MongoDB no GKE de maneira eficiente e segura, garantindo alta disponibilidade e desempenho ideal para suas aplicações.


About author

Você pode gostar também

Guia Rápido: Como Fazer Deploy de uma API Python na Cloud Usando Containers
Está aprendendo a programar e gostaria e publicar sua primeira aplicação? Neste post faremos o deploy de uma API python em cloud de maneira simples e rápida utilizando containers!
Desvendando os Anti-Padrões DevOps: Como otimizar a entrega de software
Introdução Um dos maiores problemas que (acredito eu!) deve afeta grande parte das equipe de desenvolvedores de software, não é “como transformar uma ideia em um bom sistema”, mas sim
Guia prático: Como configurar o OpenLDAP para aumentar a disponibilidade do seu ambiente
O que é OpenLDAP? LDAP é uma sigla para Lightweight Directory Access Protocol. Este serviço é usado essencialmente para armazenar informações de usuários, grupos, sistemas etc. O que não é





