
Guia definitivo para instalação e configuração do Graylog, MongoDB e Elasticsearch
Este post tem como objetivo apresentar um guia para instalação e configuração do Graylog, MongoDB e Elasticsearch com alta disponibilidade utilizando um cluster com Docker Swarm. A solução independe de sistemas operacionais pois todas as tecnologias serão utilizadas em containers.
Introdução
Através deste seremos capazes de montar um ambiente com alta disponibilidade utilizando dois clusters com Docker Swarm que atuarão gerenciando e mantendo containers com imagens do Graylog, Elasticsearch, MongoDB e Traefik.
- Graylog é uma ferramenta de código aberto cuja função é extrair dados de log dos servidores, parsear os logs, guardar os logs no serviço Elasticsearch e exibir as informações coletadas em dashboards.
- MongoDB é o serviço de banco de dados que irá guardar as metadatas, como usuários, configuração dos dashboards e etc.
- Elasticsearch é um mecanismo de busca e análise de dados distribuído de código aberto, disponibilizando os docs em tempo real e é orientado a documentos.
- Traefik é um serviço de proxy reverso que será responsável por receber, balancear e encaminhar as requisições dos usuários e dos outros serviços para os containers.
Estrutura da Solução
Para garantir um nível alto de disponibilidade de todo ambiente, utilizaremos cinco servidores. Dois servidores serão responsáveis pelo cluster do Elasticsearch, enquanto os outros três servidores serão responsáveis pelo cluster do Graylog, essa arquitetura pode escalar com facilidade por utilizar containers.
Para essa solução funcionar devemos realizar primeiramente a instalação dos pacotes docker-ce, docker-ce-cli, containerd.io e docker-compose-plugin em todas as máquinas.
Para um melhor entendimento de como funcionará todo o ambiente, segue abaixo visualização:
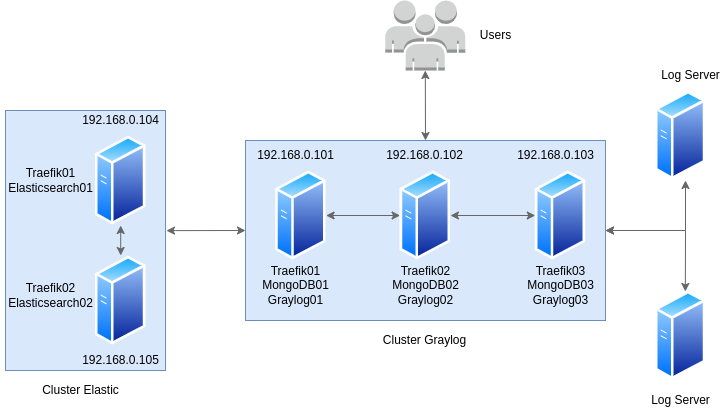
Configuração do cluster Elasticsearch
Para esse cluster serão utilizados os servidores com IP final .104 e .105. Ao acessar o servidor .104 será realizado a criação do cluster swarm:
#docker swarm init --advertise-addr 192.168.0.104
No servidor .104 será gerado o token para junção de servidores ao cluster em modo master:
#docker swarm join-token manager
Ao acessar o servidor .105 será utilizado o comando junto ao token que foi gerado no servidor .104:
#docker swarm join --token SWMTKN-1-4qaaykfchjlhlfapkvw0wptw2qn2g287lm0x3dvhct8b80ny3d-36yrtr0iz3he735gihw0c6p93 192.168.0.104:2377
Dessa forma já possuímos os dois nodes com modo master no cluster.
Para testar os se os nós do cluster estão devidamente configurados:
#docker node ls

Será também necessária a alteração da variável vm.max_map_count:
#sudo sysctl -w vm.max_map_count=262144
Caso os servidores forem reiniciados será necessário realizar o comando novamente, para alterar de forma definitiva acessar o arquivo /etc/sysctl.conf, localizar a linha da variável e realizar a edição da mesma.
Geração das stacks do Elasticsearch e configuração da rede elk
Voltaremos a acessar o servidor .104 e vamos seguir fazendo todas as configurações a partir dele.
Primeiramente será necessário gerar a rede que será compartilhada entre os containers do primeiro cluster:
#docker network create --driver=overlay elk
Para testar se a rede está devidamente configurada
#docker network ls
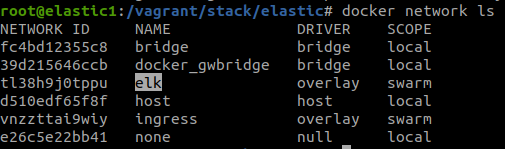
Após a criação da rede, vamos gerar as stacks que serão utilizadas para o deploy do Traefik e do Elasticsearch.
Realizar a clonagem do repositorio e acessar o diretório elastic:
#git clone https://github.com/jonathanabrantes/stacksgraylogswarm.git
#cd elastic
Deploy no Cluster Elasticsearch
- A solução do Traefik será responsável por receber as requisições nas portas 80 e 443(caso habilitado) para a interface do Traefik e na porta 9200 para o Elasticsearch, todas devidamente balanceadas.
- A solução do Elastic é formada por 2 serviços da mesma imagem, com duas réplicas cada, que terão diferentes funções sendo 2 containers master e 2 containers data com objetivo de gerar uma alta disponibilidade efetiva dessa solução.
Será feito o deploy da stack do Traefik:
#docker stack deploy -c traefik.yml traefik
Após o comando de deploy a imagem do traefik será baixada e implantada em cada nó do cluster, após o deploy ser feito com sucesso podemos acessar o Traefik pelo endereço http://192.168.0.104
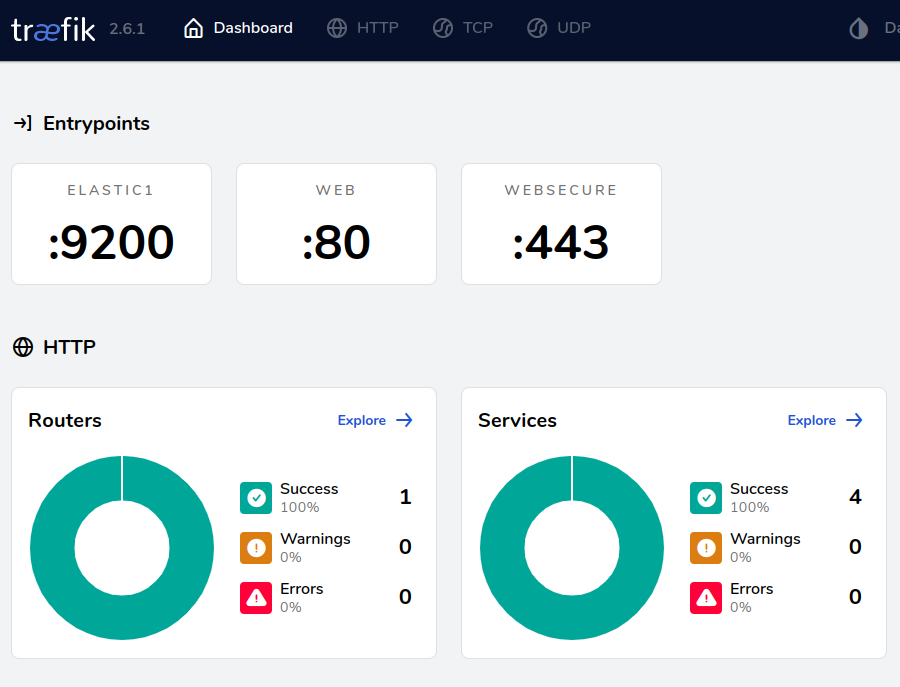
Confirmado o deploy do Traefik podemos seguir para o deploy do Elasticsearch:
#docker stack deploy -c elastic.yml elastic
Após o comando de deploy a imagem do elastic será baixada e implantada entre os nós do cluster, após o deploy ser feito com sucesso podemos acessar o Elasticsearch pelo endereço http://192.168.0.104:9200 , esse endereço e porta já estarão balanceados pelo traefik.
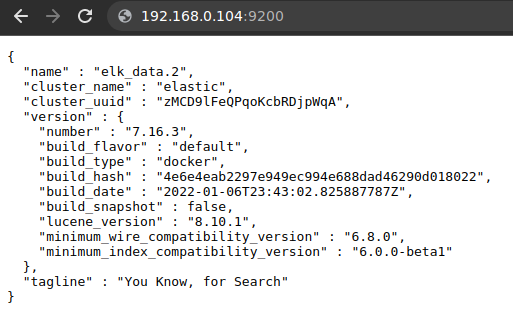
Para avaliar a saúde do cluster podemos acessar o endereço http://172.27.11.10:9200/_cluster/health?pretty que poderá informar “green” se o cluster estiver saudável ou “red” se o cluster estiver com algum problema.
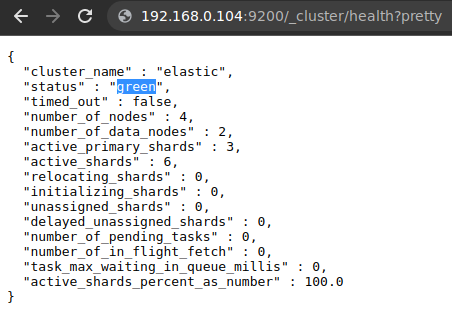
Após o deploy das stacks Traefik e Elastic, podemos avaliar a execução dos serviços:
#docker service ls

Configuração do cluster Graylog
Para esse cluster serão utilizados os servidores com IP final .101,.102 e .103. Ao acessar o servidor .101 será realizado a criação do cluster swarm:
#docker swarm init --advertise-addr 192.168.0.101
No servidor .101 será gerado o token para junção de servidores ao cluster em modo master:
#docker swarm join-token manager
Ao acessar os servidores .102 e .103 será utilizado o comando junto ao token que foi gerado no servidor .101:
#docker swarm join --token SWMTKN-1-4qaaykfchjlhlfapkvw0wptw2qn2g287lm0x3dvhct8b80ny3d-36yrtr0iz3he735gihw0c6p93 192.168.0.101:2377
Dessa forma já possuímos os três nodes com modo master no cluster.
Para testar os se os nós do cluster estão devidamente configurados:
#docker node ls

Geração das stacks do Graylog e configuração da rede graylog
Voltaremos a acessar o servidor .101 e vamos seguir fazendo todas as configurações a partir dele.
Primeiramente será necessário gerar a rede que será compartilhada entre os containers do primeiro cluster:
#docker network create --driver=overlay graylog
Para testar se a rede está devidamente configurada
#docker network ls
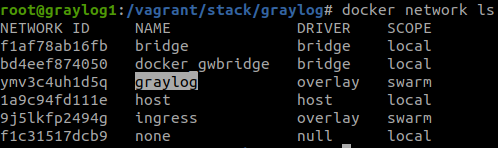
Após a criação da rede, vamos gerar as stacks que serão utilizadas para o deploy do Traefik, do MongoDB e do Graylog.
- A solução do Traefik será responsável por receber as requisições nas portas 80 e 443(caso habilitado) para a interface do Traefik e na porta 1514/tcp e udp e 12201/tcp e udp para o Graylog, todas devidamente balanceadas.
- A solução do MongoDB é formada por 3 serviços da mesma imagem, com 1 réplica cada, que terão diferentes funções sendo 1 container master e 2 containers data com objetivo de atuar utilizando ReplicaSet.
- A solução do Graylog é formada por 2 serviços da mesma imagem, com 4 réplicas no total, que terão diferentes funções sendo 1 container master com interface web e reponsável por recebimento de requisições de logs e 3 containers responsáveis exclusivamente para recebimento de requisições de logs através das portas 1514 e 12201 tcp e udp.
Realizar a clonagem do repositorio e acessar o diretório graylog:
#git clone https://github.com/jonathanabrantes/stacksgraylogswarm.git
#cd graylog
Deploy no Cluster Graylog
Será feito o deploy da stack do Traefik:
#docker stack deploy -c traefik.yml traefik
Após o comando de deploy a imagem do traefik será baixada e implantada em cada nó do cluster, após o deploy ser feito com sucesso podemos acessar o Traefik pelo endereço http://192.168.0.101
Confirmado o deploy do Traefik podemos seguir para o deploy do Graylog:
Antes do comando de execução do graylog vamos acessar o arquivo example.env, as linhas 1 e 2 deverão ser alteradas a sua necessidade, sendo:
–GRAYLOG_PASSWORD_SECRET=$SenhaDoUsuarioAdmin
–GRAYLOG_ROOT_PASSWORD_SHA2=$SenhaDoUsuarioAdminEmSha2
–Para gerar o sha2 da senha usar o comando em um terminal: “echo -n $SenhaDoUsuarioAdmin | shasum -a 256”
Após configurado as variáveis salvar e alterar o nome do arquivo de “example.env” para “.env” para que o mesmo possa ser acessado pela stack. Executar o deploy da stack:
#docker stack deploy -c graylog.yml graylog
Após o comando de deploy a imagem do MongoDB será baixada, serão implantados 3 containers do banco de dados, que atua.rão em modo ReplicaSet para maior disponibilidade dos dados. Também será baixado a imagem do Graylog
Avaliar os serviços em execução através do comando docker service ls ou pelo navegador através do link: http://192.168.0.101:9000/ . A senha do usuario admin será a que foi informada no arquivo .env
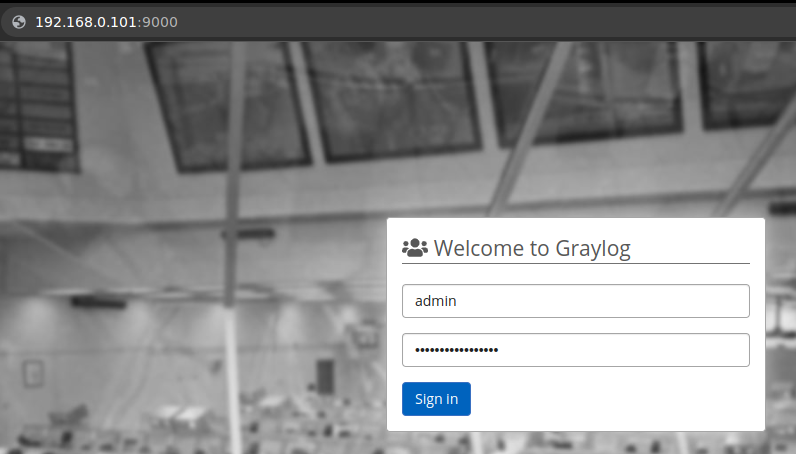
Acessando System>Nodes seremos capazes de verificar cada node no cluster, bem como consumo de cada container.
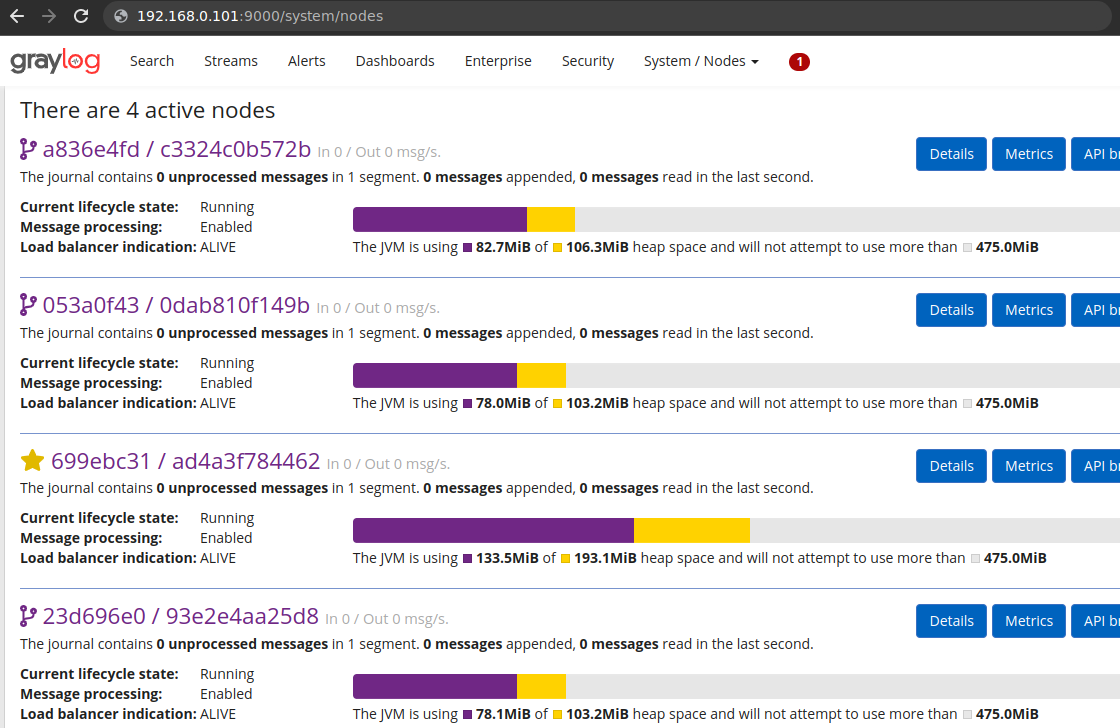
Após o deploy das stacks Traefik e Elastic, podemos avaliar a execução dos serviços:
#docker service ls

Conclusão
Após seguir todas as instruções deste guia, você já possui um cluster de Graylog em funcionamento e prontinho para ser configurado conforme a necessidade do cliente.
Como todos os softwares livres, a documentação do Graylog, como também do ElasticSearch e do MongoDB estão disponíveis gratuitamente nas páginas de seus fornecedores, e devem ser consultadas antes de qualquer alteração que impacte a infraestrutura ou quando se houver dúvidas.
Você também pode utilizar a seção de comentários do blog da 4Linux para tirar dúvidas e postar opiniões!
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Guia Completo: Como Utilizar o Ansible Galaxy para Otimizar seu Trabalho
Durante minhas aventuras como SysAdmin, eu me deparei com a fantástica ferramenta chamada Ansible. Eu me empolguei tanto com a ferramenta que acabei criando um projeto chamado warudo, agora já não

Monitoramento de protocolo SNMP com Logstash
Monitoramento de protocolo SNMP com Logstash O gerenciamento de redes e monitoramento de dispositivos em tempo real é uma tarefa crítica para administradores de TI. Com a coleta contínua de

As 5 tendências DevOps que você precisa acompanhar em 2025
O universo DevOps segue em constante transformação, impulsionado por tecnologias emergentes, novas exigências de mercado e a busca por maior agilidade e segurança no ciclo de vida do software. Em





