
Entenda o Processo de Consulta SQL no Sistema Gerenciador de Banco de Dados Postgres
Sempre que utilizamos o Sistema Gerenciador de Banco de Dados (SGBD) Postgres ou PostgreSQL, o foco principal de sua
utilização é a realização de consultas (Querys), afinal de nada adiantaria salvar os dados de forma permanente e não conseguir
acessá-los.
Esta busca pelos dados é realizada através do comando SELECT, com todas as suas variações existentes. Para o usuário ou
aplicação, que consultam a base de dados, isto é feito de forma transparente, mas do lado do Postgres, isto é realizado por um
componente interno de sua arquitetura conhecido como Parser. O Parser ou Otimizador de Consultas – otimizador porque ele sempre busca realizar a consulta da forma mais rápida possível -realiza a busca através de 04 etapas principais, que são:
- Análise;
- Transformação;
- Planejamento;
- Execução.
Estas etapas são alusivas ao que é chamado de Protocolo de Consulta Simples, e é sobre ele que iremos tratar neste post.
Análise
Nesta etapa o texto da consulta é analisado de forma que o servidor entenda o que precisa ser realizado. Aqui temos dois
componentes internos atuando.
No primeiro o Analisador Léxico verifica se os símbolos léxicos, ou seja, se as palavras passadas no comando são conhecidas pelo
interpretador. Ele verifica por exemplos as palavras chaves da linguagem SQL utilizadas na consulta.
Depois o Analisador Gramatical realiza a verificação dos outros símbolos léxicos para garantir que eles sejam gramaticalmente
corretos, por exemplo, nomes de variáveis seguindo as regras do Postgres.
Imaginemos o seguinte exemplo de consulta:
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = ‘postgres’
ORDER BY tablename;
Uma árvore é montada em memória com a separação dos principais elementos da consulta, conforme a figura abaixo:
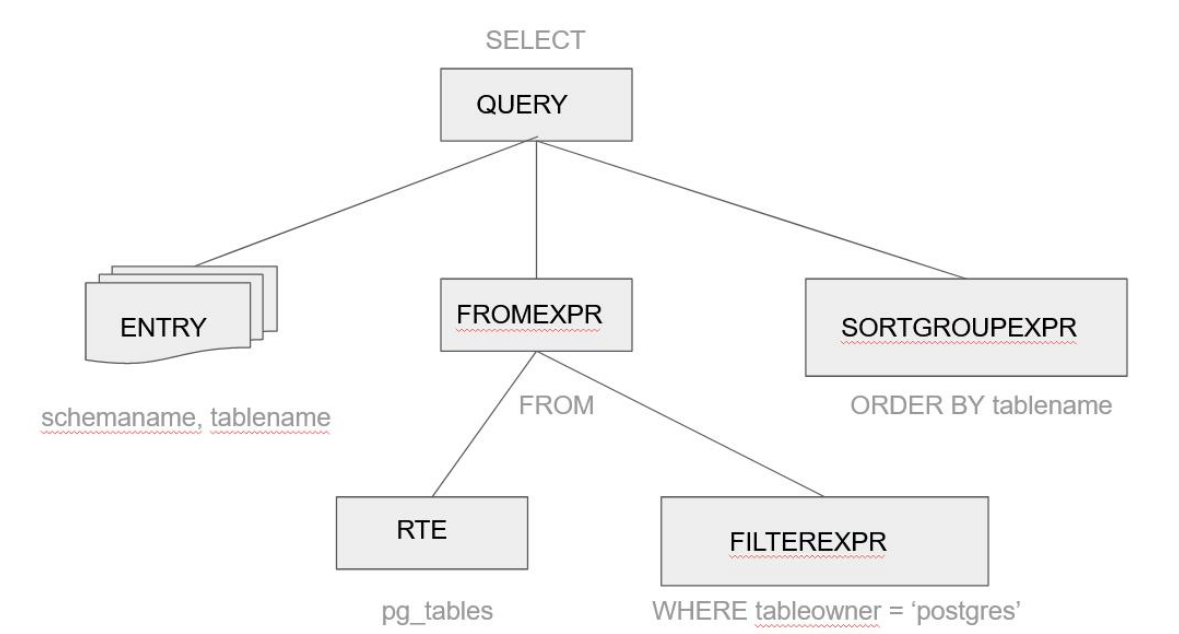
Após a construção desta árvore, o Analisador Semântico verifica quais objetos irão ser acessados e se o usuário tem permissões
necessárias para acesso a estes objetos.
Transformação
Nesta etapa a consulta será transformada ou reescrita. Isto ocorre porque alguns objetos são referências a outros, como no caso
de uma view. Na consulta de exemplo o objeto pg_tables trata-se de uma view, logo a consulta deverá ser modificada para
referenciar os objetos existentes de fatos, no caso as tabelas do banco de dados.
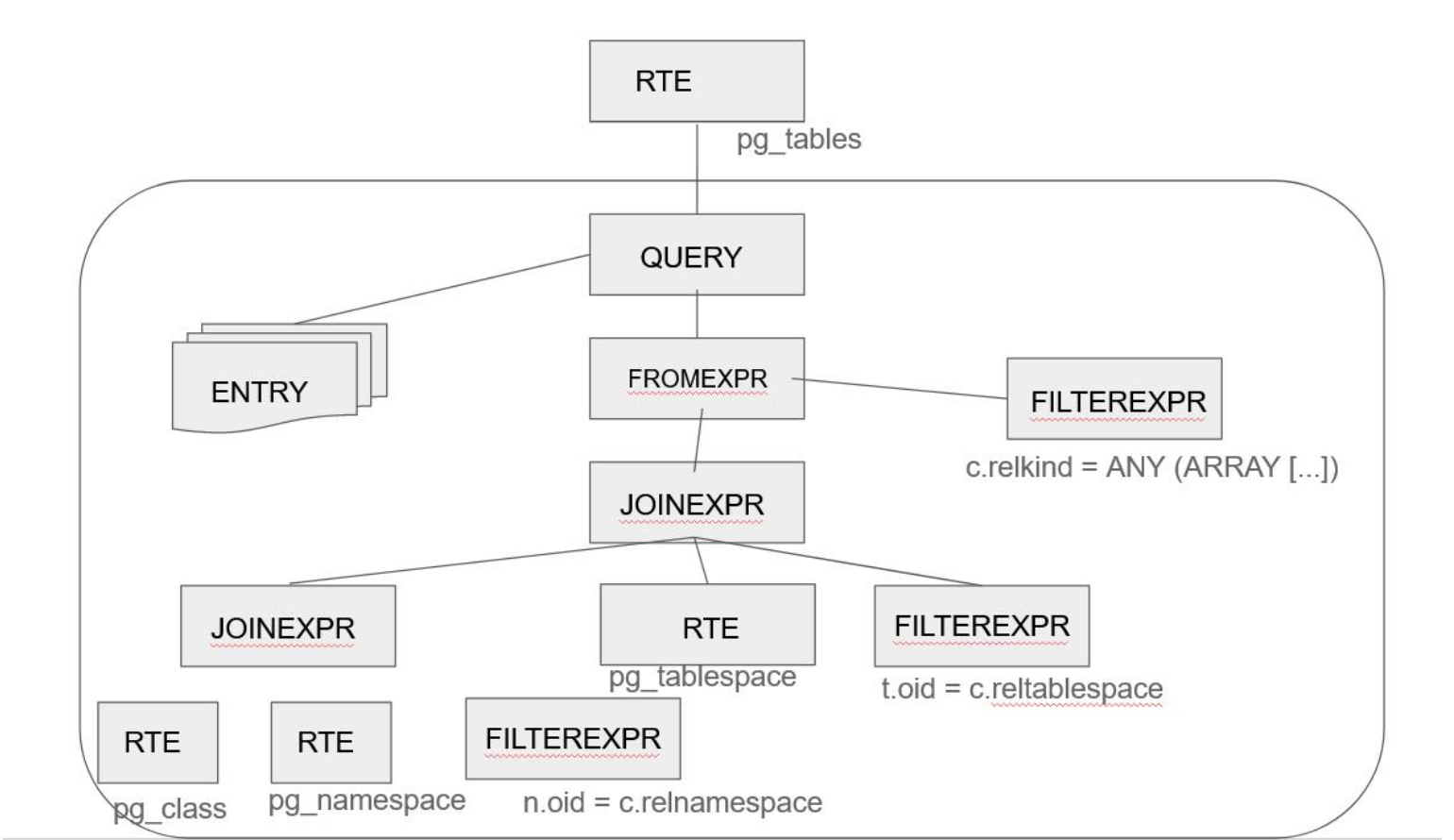
A consulta inicial é então rescrita de acordo com a imagem acima. Esta reescrita ocorre apenas na árvore de objetos montada
em memória, e não acontece na consulta inicial submetida para o Postgres.
SELECT schemaname, tablename
FROM (
-- pg_tables
SELECT n.nspname AS schemaname,
c.relname AS tablename,
pg_get_userbyid(c.relowner) AS tableowner,
...
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_tablespace t ON t.oid = c.reltablespace
WHERE c.relkind = ANY (ARRAY['r'::char, 'p'::char])
)
WHERE tableowner = 'postgres'
ORDER BY tablename;
A árvore de análise, demonstrada nas figuras anteriores, refletem a estrutura sintática da consulta, porém não mostram a
ordem em que as operações serão executadas. Nesta etapa também é implementada a segurança em nível de linha. O Postgres
ainda oferece suporte a transformações personalizadas, que o usuário pode implementar usando o sistema de regra de reescrita.
Este sistema de regras é um dos principais recursos do Postgres e foi concebido desde o início do projeto do SGBD.
Planejamento
A linguagem de consulta SQL é uma linguagem declarativa, ou seja, ela informa apenas o que você quer buscar na base de dados,
mas não informa como esta operação deve ser realizada. Isto fica a cargo do próprio SGBD, em um componente interno
conhecido como planner ou optimizer.
O otimizador é responsável por escolher qual a melhor forma de retornar aqueles dados para o cliente que os solicitou. O
mesmo conjunto de dados podem ser entregues de várias formas. O otimizador então busca a forma mais performática,
baseada nas estatísticas dos objetos utilizados na busca (principalmente tabelas e índices).
O comando EXPLAIN pode ser utilizado para verificar qual o plano de execução que o otimizador está escolhendo para uma
determinada consulta. A sintaxe do comando é a seguinte.
EXPLAIN
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
E sua saída é da seguinte forma:
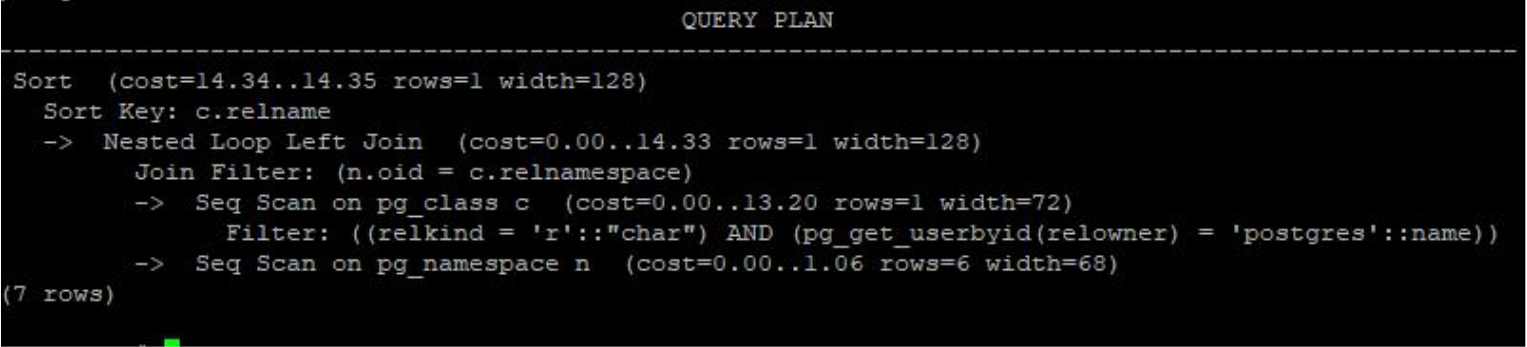
Perceba que este comando mostra a ordem em que as operações são realizadas e também o custo computacional associado a
cada operação, bem como o custo total do comando.
É importante para que a saída realmente reflita o melhor plano de execução que a estatística de tabela esteja atualizadas
através do comando ANALYZE.
Execução
Após a etapa de planejamento selecionar qual o melhor plano de execução para a consulta passada, ela será executada baseada
neste plano. Para tanto é criado um objeto na memória chamado de portal que irá conter os resultados momentâneos, à medida
que a consulta seja executada. Cada nó da árvore é opera como uma fase de uma linha de montagem em uma fábrica, e ao final
os dados solicitados pela consulta inicial são devolvidos.
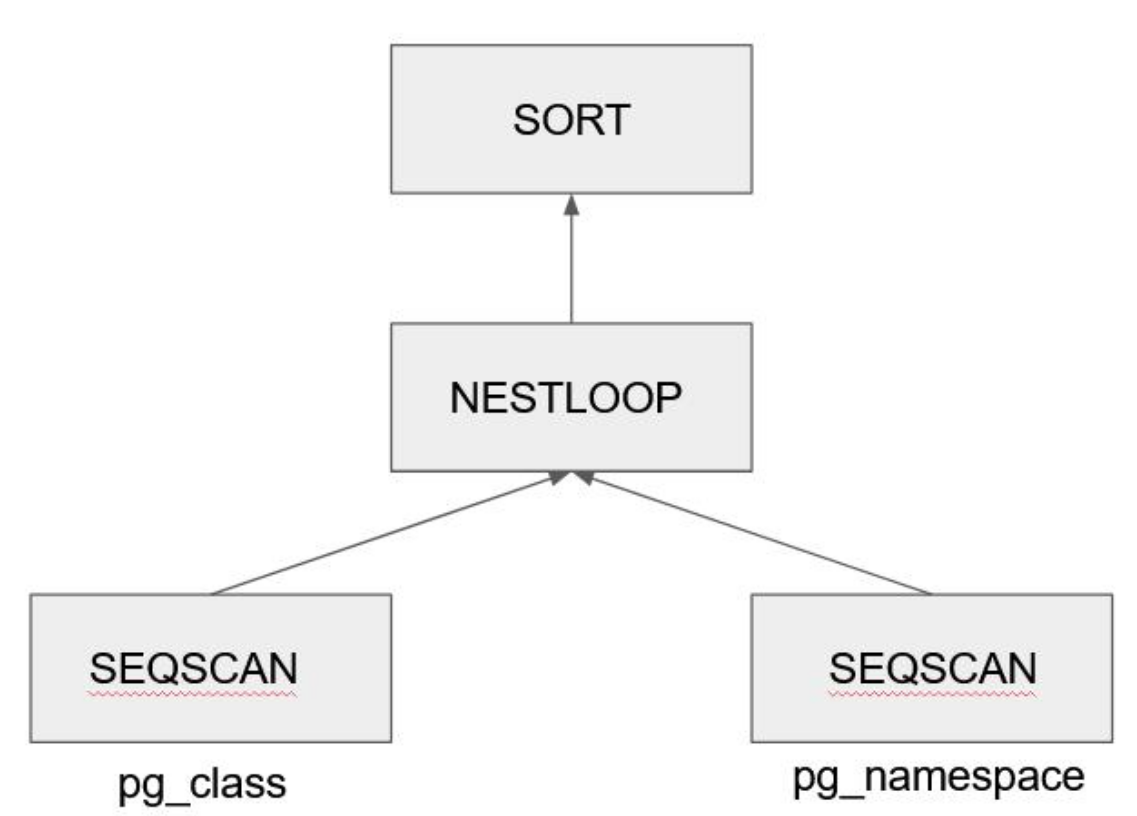
Considerando o exemplo da figura acima, a execução começa pelo nó raiz (no exemplo o nó SORT ). Este solicita dados do nó
filho e entrega para quem solicitou (seu nó pai). Alguns tipos de nó, como o NESTLOOP, recebem dados de fontes diferentes
( mais de uma fonte ). Ao encontrar duas linhas, cada uma vinda de uma das fontes, que casem através de uma junção, ele
entrega esta linha para seu nó pai. Já o SORT precisa receber todos, classificar e depois entregar o conjunto ordenado.
Cada nó tem uma forma de trabalhar específica do seu tipo de operação.
Ambos os nós SEQSCANs são as varreduras completas nas tabelas. Eles apenas repassam as linhas lidas, sem armazenar nenhum
dos registros. Alguns nós comem o SORT precisam agrupar alguns registros a fim de realizar sua operação (neste caso, a
classificação dos dados ). Esta classificação irá utilizar de uma área de memória chamada work_mem, que é alocada para cada
nó existente no plano de execução da sessão (conexão) aberta com o servidor Postgres.
Conclusão
Trouxemos uma visão geral das etapas que o Postgres realiza internamente para atender uma consulta SQL. Estes passos são
realizados para outros comandos, como operações de DML ( Data Manipulation Language).
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Guia completo: Como instalar e configurar o OCS Inventory
O OCS Inventory é um software de gerência para inventários de dispositivos em rede, com ele é possível registrar todas as características de um computador incluindo: Versão do sistema operacional;

Entrevista exclusiva com Nicolas Grekas sobre o Symfony Framework
Em Maio o Nicolas Grekas – um dos desenvolvedores do Symfony Framework – esteve no Brasil pela primeira vez para o SymfonyLive e tivemos a oportunidade de recebê-lo aqui na

Backups no MySQL com MyDumper
No MySQL, existem algumas ferramentas de backup lógico (dump) que podem ser utilizadas para realizar backups diários, seja como uma cópia secundária, em conjunto com um backup físico, ou ainda





