
Entenda a interação entre MySQL e o cache de sistema de arquivos do Linux
Neste post veremos a interação entre o MySQL e o cache de sistema de arquivos do Linux, principalmente a respeito da configuração do buffer pool do InnoDB.
Utilizamos o MySQL para exemplos de configuração e alguns conceitos desta postagem servem para qualquer tipo de aplicação e provavelmente qualquer sistema operacional, mas esta se volta especificamente ao Linux.
Em muitos casos de atendimento de MySQL e MongoDB nos deparamos com o cache do sistema de arquivos sendo ignorado por completo.
Um bom complemento a esta postagem é a série Conhecendo o Kernel do Linux Pelo /proc de William Welter.
As Engines
O MySQL possui algumas formas de “guardar” os dados no disco e tratá-los internamente, chamadas de engine (motor). A principal engine do MySQL, e a padrão, é a InnoDB. Isso se dá por uma série de motivos, mas o principal é que essa é a única engine a suportar transações.
No decorrer dessa postagem nos aprofundaremos no papel do InnoDB do MySQL em relação ao cache do sistema de arquivos e como estas coisas estão intimamente ligadas, começando com o cache de sistema de arquivos.
O Cache de Sistema de Arquivos
Quando um processo lê ou escreve algum arquivo no disco, o processo em si não acessa o disco. Quem controla e realiza o acesso ao disco é o próprio kernel, desta forma, otimizando leituras e escritas de todos os outros processos que estão requisitando acesso.
O processo faz suas operações de leitura e escrita na memória. É comumente dito que as leituras são feitas no cache e as escritas no buffer, mas esta área é praticamente uma só do ponto de vista da administração de sistemas.
Quando um processo faz uma operação de leitura, o sistema traz os blocos necessários do disco e os adiciona no cache, então o processo pode finalmente ler os dados. Essa operação parece redundante, mas uma vez que os dados tenham sido enviados do disco para a memória, as próximas leituras daquele mesmo trecho tornam-se extremamente mais rápidas. Esse comportamento é bastante útil na maioria dos bancos de dados e outros tipos de aplicação.
A escrita acontece de maneira similar: os softwares fazem alterações apenas na memória. Essas alterações marcam aquelas áreas como dirty (suja) e, em um determinado momento, o sistema operacional agrupa todas essas operações de escrita e as executa de uma única vez no disco.
Para ambos os casos, otimizações acontecem para leituras e escritas sequenciais e também para leituras e escritas aleatórias.
Os blocos de memória ocupados pelo buffer/cache são trocados por blocos mais recentes através de um algoritmo de troca de página conhecido como LRU (Least Recently Used, Usado Menos Recentemente). O sistema utiliza uma lógica para trocar blocos pouco utilizados por blocos novos ou para requisitar novos blocos quando todos estão sendo muito requisitados.
Memória RAM x Disco
Para uma melhor compreensão sobre a vantagem do cache e do buffer, é necessário antes entender a diferença de velocidade entre a memória RAM e o disco, como pode ser visto na tabela simplificada abaixo:
| Tipo | Leitura | Escrita |
|---|---|---|
| Memória DDR4 | 24000 MB/s | 24000 MB/s |
| HD 7200 RPM | 120 MB/s | 120 MB/s |
| SSD | 500 MB/s | 350 MB/s |
| NVMe | 3000 MB/s | 1000 MB/s |
É possível notar que a memória ainda é extremamente superior em velocidade em relação aos dispositivos NVMe, o que demonstra a finalidade do cache/buffer de sistema de arquivos.
Uma característica interessante do buffer/cache de sistema de arquivos é sua baixa prioridade. Quando os processos requisitam memória, inicialmente o Linux entrega a memória realmente livre, mas caso não exista mais memória livre, as porções de memória RAM utilizada por estes mecanismos podem ser requisitadas por outros processos, diminuindo o buffer/cache disponível para o sistema.
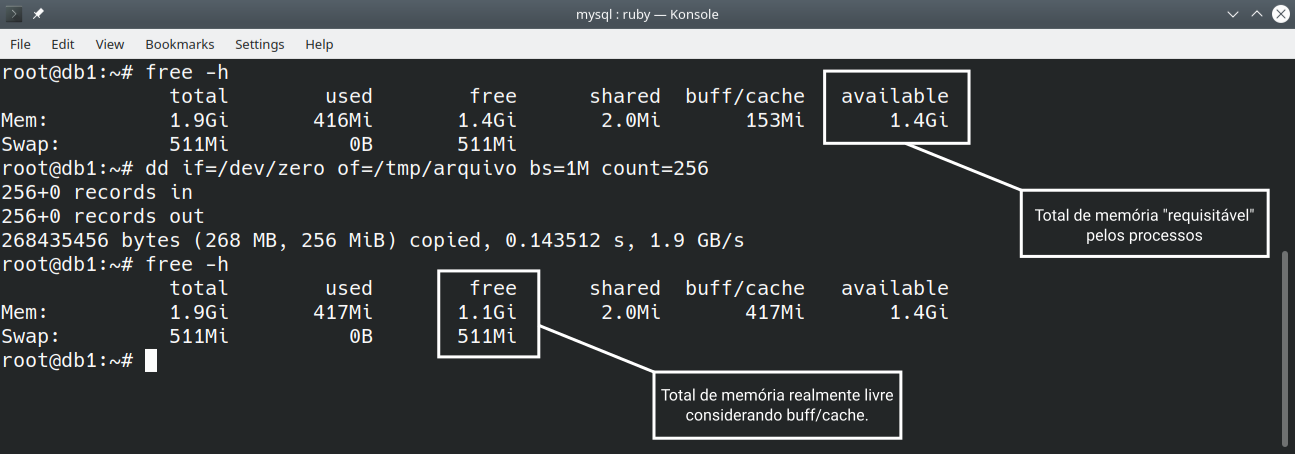
Na imagem acima é possível ver que o available (disponível) não se altera mesmo quando o buff/cache cresceu. Já o indicador free (livre) diminuiu. Isso indica que a memória que o sistema pode entregar para os processos continua 1.4GB.
Apesar desta memória de buffer/cache estar disponível para os demais processos que necessitem de memória, um buffer/cache muito pequeno geralmente trará outros problemas mais sutis, que acumulados representam um grande problema.
Para a maioria das aplicações, esta situação não é desejada:
- Um servidor web pode requisitar um arquivo HTML acessado constantemente e não encontrá-lo na memória;
- Um banco de dados poderia requisitar uma página que acabou de inserir e não encontrá-la na memória;
Porque isso é um problema? Afinal o sistema carregara o arquivo na memória e o processo então poderia ler este arquivo.
Esse pensamento está correto, mas ainda há alguns problemas quando o buffer/cache é insuficiente:
- Provavelmente a memória da máquina está se esgotando;
- Um buffer/cache pequeno implica que praticamente toda leitura de arquivo acontecerá no disco;
- As leituras de novos blocos colocarão a memória sobre pressão, pois sua área é pequena;
- A constante troca do conteúdo da memória degradará todo o sistema.
Descarregando Arquivos da Memória
Quando isso acontecer em nossos computadores (com Linux, por favor), a solução é simples, basta seguir os seguintes passos:
- Esvaziar o cache de sistema de arquivos;
- Verificar a memória;
- Criar um arquivo grande;
- Verificar a memória;
- Acompanhar o flush (descarregamento) do buffer.
Os comandos são os seguintes:
echo 1 > /proc/sys/vm/drop_caches free -h dd if=/dev/zero of=/tmp/arquivo bs=1M count=100 free -h while sleep 1; do grep -i dirty /proc/meminfo; done
O último dos comandos é um pequeno loop em shell para acompanhar a limpeza do buffer sem limpar a tela toda, para pará-lo será necessário utilizar a sequência CTRL + C.
Veja o resultado na imagem abaixo:
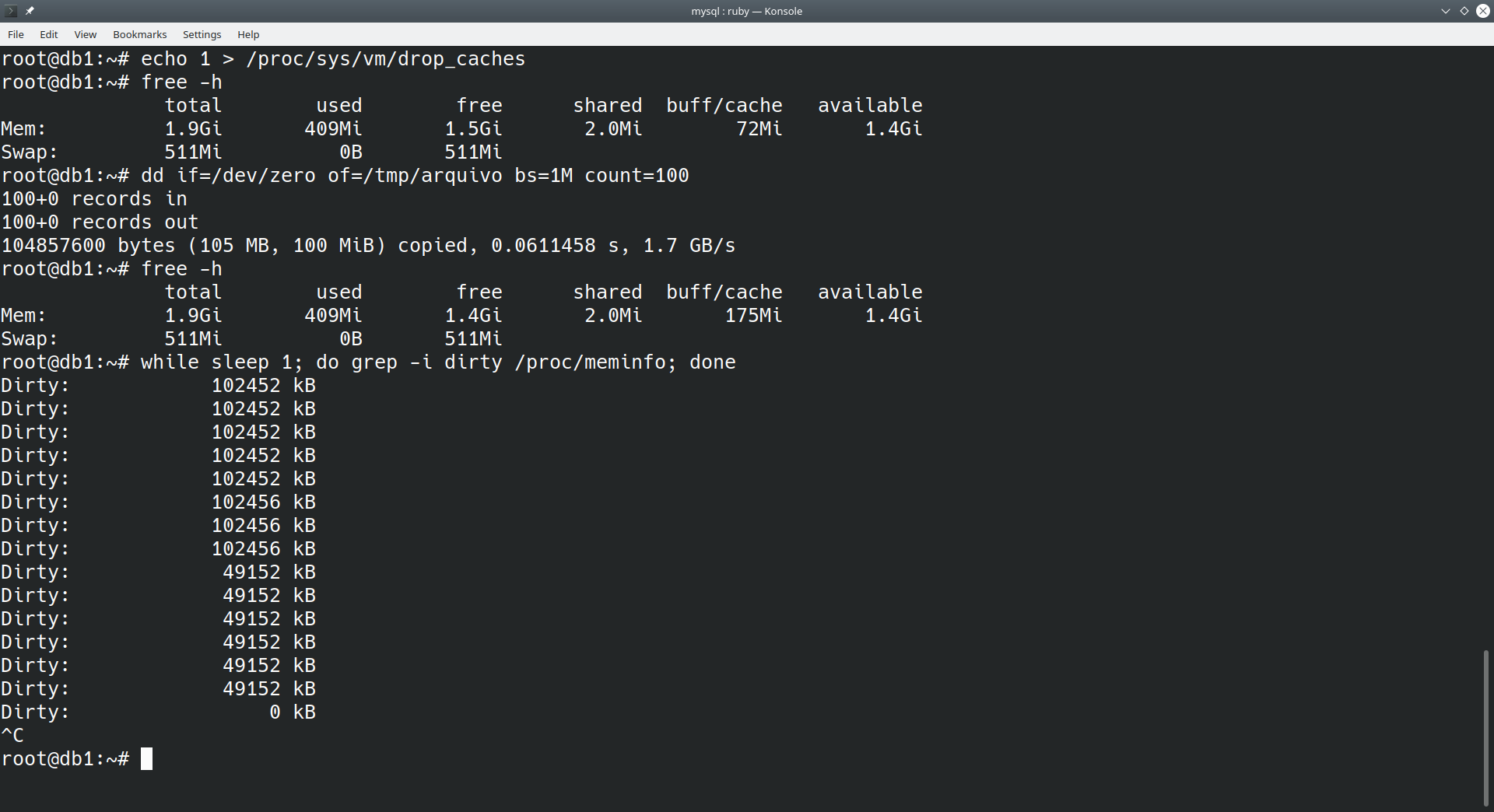
É possível perceber o aumento de quase que exatamente 100MB de memória RAM alí em buff/cache após a criação do arquivo de exatos 100MB. Então é possível observar a descarga dos dados dirty na memória para o disco com o passar dos segundos.
Carregando Arquivos na Memória
Podemos até utilizar o arquivo anterior como exemplo, e observar alguns pontos interessantes, os passos serão os seguintes:
- Esvaziar o cache de sistema de arquivos;
- Verificar a memória;
- Ler todo o arquivo anterior;
- Verificar a memória;
Veja o resultado na imagem abaixo:
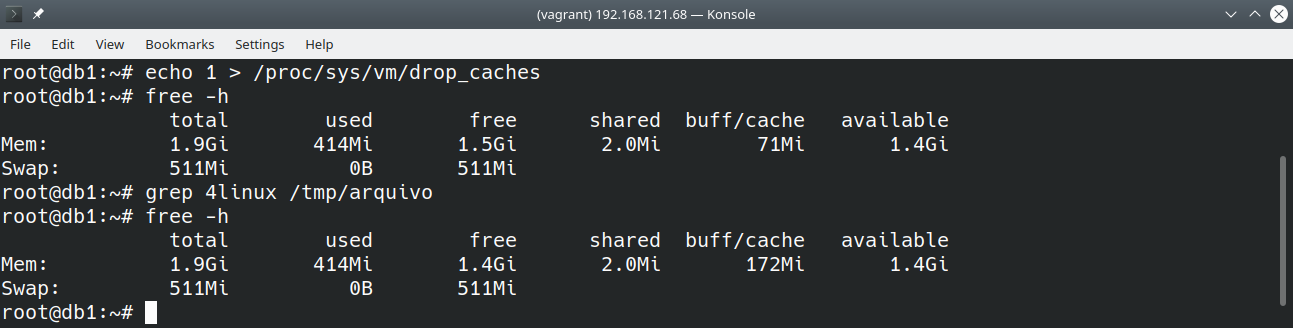
Ao ler o arquivo por completo, mesmo através de um grep qualquer, este foi totalmente carregado na memória.
Uma vez que o arquivo esteja na memória, as operações de leitura acontecem com velocidades superiores. A imagem abaixo mostra a criação um arquivo maior cujo cache é esvaziado e duas operações de leitura são realizadas:
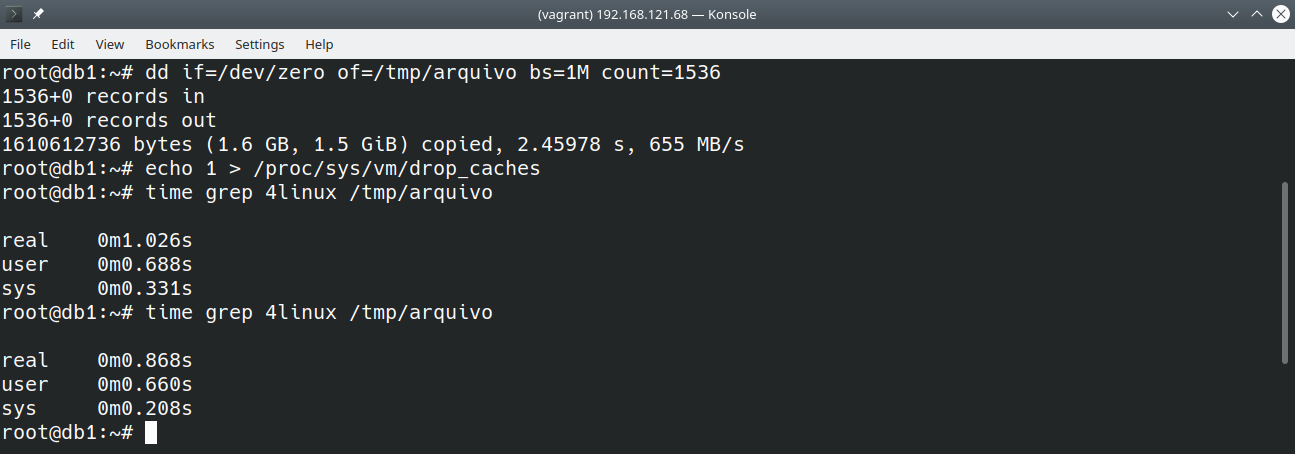
Apesar da diferença de tempo ser pequena, ela exemplifica a ideia acima.
Mas o meu banco tem gigas e gigas…
É esperado que os bancos de dados não trabalhem dessa forma, apenas os arquivos requisitados durante a leitura são carregados na memória. Isso significa que, por exemplo, em um arquivo de dados de 1TB, apenas uma pequena fração mais recente deste está sendo utilizada. Centenas de arquivos podem ser requisitados, ou mesmo uma grande parte de um único arquivo, totalizando uma quantia enorme de espaço.
Os arquivos que representam os índices também precisam estar na memória, particularmente no MongoDB, Postgres e outras engines do MySQL. Em um cenário de pouco buffer/cache, quando o índice não está na memória, o disco precisa ser lido para sua consulta e então novamente o disco será lido para a busca dos dados.
Quando tudo está na memória, índice e dados, até mesmo as buscas menos otimizadas podem retornar em tempo hábil, mesmo sem índices, pois ler uma quantia enorme de dados da memória é relativamente rápido. Quando não há espaço suficiente, todas as características ruins de arquitetura e aplicação tornam-se assustadoramente evidentes. Isso explica muitas situações em que o banco funcionava bem até determinado dia, mas depois passou a se arrastar, nada é por acaso.
O que fazer?
Não há muito o que fazer, os bancos devem ser dimensionados para respeitar uma margem considerável de memória para o buffer/cache. Para se ter uma ideia, o MongoDB recomenda que 50% da memória RAM seja dedicada ao buffer/cache e outras coisas do sistema operacional. O Postgres pode trabalhar com uma margem menor, afinal existem outros buffers internos que também lidam com “uma cópia” das páginas dos dados, mas tudo depende do cenário, não há uma regra absoluta.
O InnoDB utiliza o mesmo arquivo para índices e dados, a situação seria similar, mas o InnoDB trabalha de uma forma um pouco diferente…
O InnoDB
Pois bem, com a introdução ao cache de sistema de arquivos realizada anteriormente, será possível focar exclusivamente no InnoDB a partir de agora.
A principal configuração do InnoDB é conhecida como buffer pool, uma área da memória utilizada para guardar páginas de dados recentes, que estão sendo consultadas, alteradas ou mesmo inseridas. Neste buffer pool também ficam os índices secundários (aqueles que não são a chave primária) e páginas alteradas destes mesmos índices. Em suma, quanto maior o buffer pool, melhor.
Assim como o buffer/cache de sistema de arquivos, o InnoDB utiliza LRU para rotacionar o conteúdo do buffer pool.
Isso significa que o buffer/cache de sistema de arquivos e o buffer pool são a mesma coisa? Pois é, não é?
Pode ser encontrado na internet, em fóruns, e em configurações aplicadas por aí uma afirmação bastante perturbadora:
– O tamanho do innodb_buffer_pool_size deve ser 80% da memória RAM.
Apesar desta informação ser bastante imprecisa, ainda é possível extrair uma certa verdade, mas com muitas ressalvas:
- O banco está sozinho na máquina?
- Uma máquina pequena que hospeda o MySQL e o servidor web provavelmente vão competir entre sí pelos recursos.
- Existem outras tabelas da aplicação de engines diferentes de InnoDB?
- Outras tabelas necessitam de seus próprios buffers internos e do cache de sistema de arquivos.
- Qual o total de memória RAM?
- 80% de 256 GB de memória RAM deixam 51 GB livres, faz sentido?
- Sobrou espaço no buffer/cache para os arquivos de log transacionais, binários e de aplicação?
- Sem espaço suficiente para estes arquivos, teremos a mesma pressão de memória explicada anteriormente.
- Foi considerado buffers internos e conexões médias?
- Normalmente aplicamos 1MB por conexão.
Estas perguntas acima ainda não consideram que o InnoDB ainda passará pelo cache do sistema de arquivos, basicamente, isso significa que algumas partes dos dados do buffer pool estarão duplicados no cache de sistema de arquivos.
É possível evitar isso, ou minimizar os efeitos dessa duplicação, mas antes o funcionamento do InnoDB deve ser analisado.
Estrutura do InnoDB
Abaixo temos uma imagem bastante simplificada da estrutura interna do InnoDB:
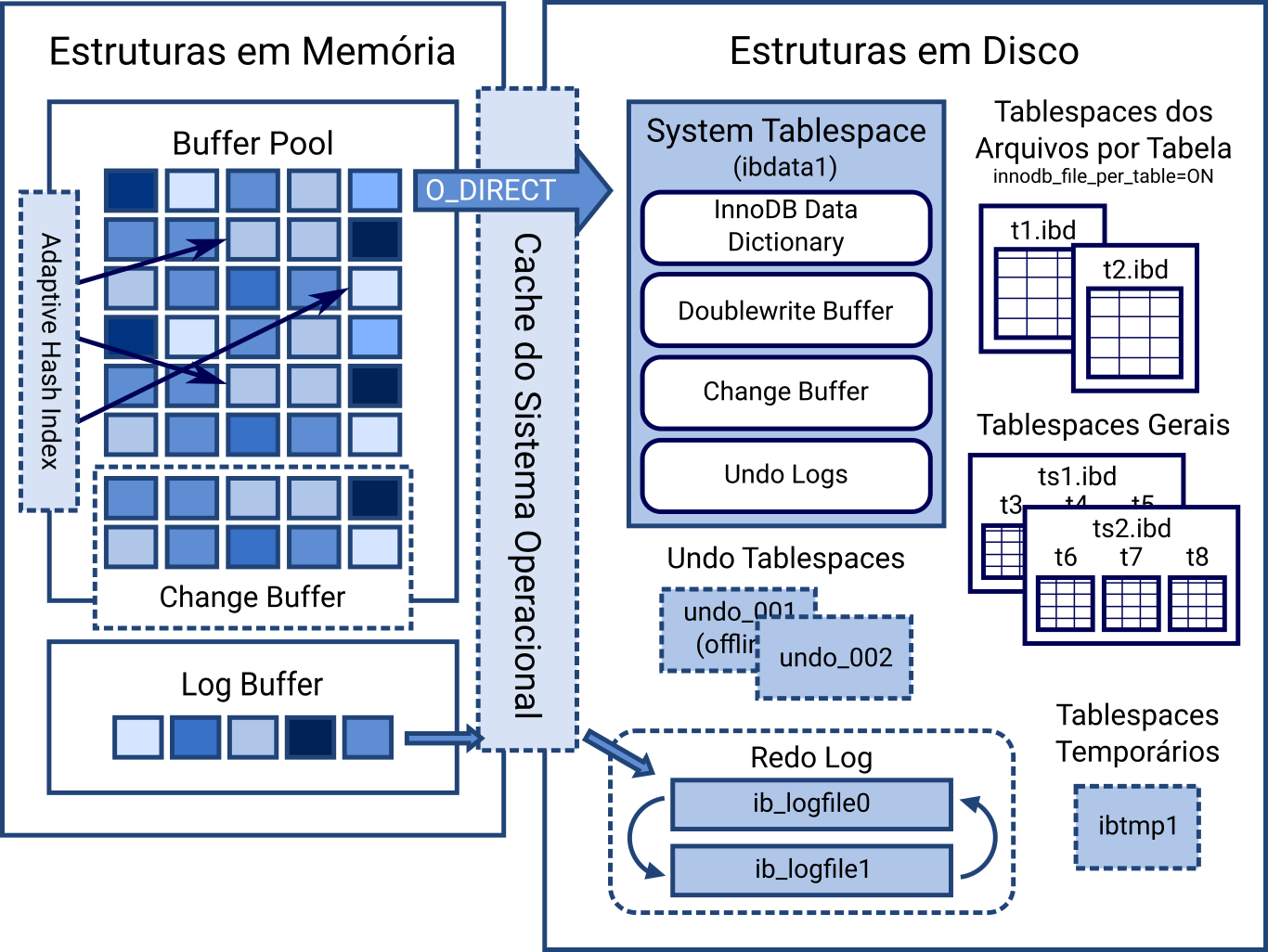
O foco é a parte da esquerda, justamente o buffer pool, onde há um grande retângulo com o título Cache do Sistema Operacional. Por padrão, o MySQL não ignora o buffer/cache que abordado nessa postagem. Todo bloco de disco lido é carregado do disco para o buffer/cache e então copiado para o buffer pool.
Sendo assim, para evitar pressão na memória, é recomendado que o innodb_buffer_pool_size seja menor ou igual a 50% da memória RAM. Mas ele pode ser aumentado, caso o MySQL seja configurado para evitar o buffer/cache. Essa possibilidade é ilustrada pela seta azul O_DIRECT.
O manual do linux a respeito do método open indica a seguinte definição a respeito de O_DIRECT:
Tenta minimizar os efeitos de cache da E/S de/para este arquivo. No geral isso degradará a performance, mas é útil em situações especiais, como quando as aplicações fazem o seu próprio cache. A E/S dos arquivos é feita diretamente de/para o buffer do “user-space”.
A sigla E/S significa entrada e saída, já o “user-space” é a área da memória que os processos utilizam, ou seja, qualquer coisa não relacionada ao kernel.
O InnoDB do MySQL é exatamente a aplicação que controla o próprio cache citado na documentação. Se a forma como o InnoDB acessa os arquivos de dados for modificada, é possível ignorar o buffer/cache e evitar uma pressão desnecessária na memória RAM. Essa modificação é feita através da diretiva:
innodb_flush_method = O_DIRECTPara demonstrar os efeitos, consideraremos como exemplo uma máquina com 2GB de memória RAM e 1 GB de innodb_buffer_pool_size. Algumas consultas serão feitas em bases de exemplo para popular o buffer pool com dados.
Primeiro serão feitas as consultas com innodb_flush_method em seu valor padrão, fsync:
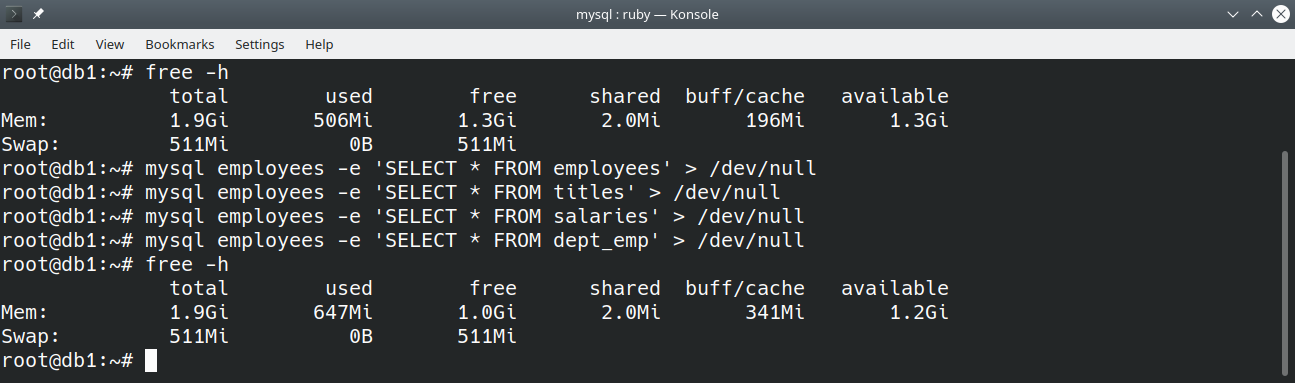
Agora as mesmas consultas mas com innodb_flush_method utilizando O_DIRECT:

Existe mais memória livre para a segunda forma. Mesmo com o buffer/cache de valores iniciais diferentes, é possível notar que com sync seu tamanho cresceu 145MB, já com O_DIRECT apenas 3MB!
Conclusão
O cache de sistema de arquivos precisa ter um tamanho considerável para os bancos de dados, pois todas as operações dependem deste buffer/cache para acontecerem da melhor forma possível.
Pouco buffer/cache resulta em uma grande pressão na memória RAM, atrapalhando todas as operações restantes. Normalmente isso se traduz no aparecimento de queries mal otimizadas capturadas por um valor configurado previamente, lentidão repentina e acúmulo de conexões concorrentes. Geralmente, as pessoas observam o uso de CPU para encontrar problemas nas aplicações, e também nos bancos de dados, mas essa métrica não é confiável uma vez que a thread fornece conexão para o processamento quando espera algo do disco.
O InnoDB do MySQL pode ter um buffer pool muito maior que 80% da memória RAM, desde que se observe a quantidade total de memória, os buffers internos, quantidade de conexões e tamanho dos mais variados arquivos de log. Valores de buffer pool mais altos precisam obrigatoriamente da utilização de O_DIRECT para evitar pressão sobre a memória RAM.
Provavelmente meu próximo post será a respeito de concorrência, outro assunto de difícil negociação!
Se gostou deste conteúdo, que tal fazer o curso de MySQL conosco?
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também
Entrevista com Flavio Gurgel: Especialista discute sobre PostgreSQL
A 4Linux conversou sobre o PostgreSQL com Flavio Gurgel, entusiasta do software livre e especialista em banco de dados há quase 20 anos. Gurgel, atualmente, presta consultoria, suporte e treinamento

Desbravando o OpenTofu: Parte 02 – Provisionando uma VM na GCP
Olá pessoal, hoje no blog, vamos realizar um deploy na GCP com uma ferramenta em potencial de Infra as Code chamada OpenTofu, um fork do Terraform. Bora lá! Antes de

Desvendando o Mundo da Computação: Processos, Programas e Comunicação
No mundo da computação, cada programa e processo desempenha um papel único na criação e execução de tarefas. No entanto, a diferença entre esses dois termos pode não ser tão





