
Kubernetes – Configurando um Cluster Multi-Master
Neste post vamos configurar um cluster Kuberentes Multi-Master apenas com a sua máquina. Mas antes de falarmos sobre um cluster em Kubernetes trabalhando em modo Multi-Master…
Uma palavra sobre containers…
Hoje em dia fica difícil imaginar o desenvolvimento sem containers, mais precisamente sem Docker. Daqui a algum tempo desenvolver sem essa tecnologia será como hoje é desenvolver sem um versionador como o git do nosso lado, no mínimo duvidoso.
Existe alguns casos em que isso não é necessariamente verdadeiro, mas na maioria dos casos podemos assumir que sim.
Quando a arquitetura de nossas aplicações começam a crescer e as dependências entre serviços, alta disponibilidade e balanceamento passam a ser uma necessidade, precisamos de uma ferramenta capaz de gerenciar todos esses serviços, precisamos de um orquestrador. E não há hoje no mercado um orquestrador de containers tão conhecido e estável como o Kubernetes – mas se você nunca mexeu com orquestradores de containers eu aconselho fortemente a utilizar o Docker Swarm para começar, a Rankdone possuí uma infraestrutura sólida e bastante confiável baseada em microserviços dentro do Swarm.
Mas vamos voltar ao assunto deste post, o Kubernetes.
Kubernetes
Kubernetes – ou K8S – é um orquestrador de containers que facilita todo o trabalho de balanceamento de carga, descoberta de serviço, gerenciamento de estado e etc. Resumindo, o Kubernetes é uma das ferramentas que devemos procurar quando falamos de microserviços, multi-cloud ou mesmo vendor lock-in – porque não?
Se você nunca mexeu com o Kubernetes, você pode começar utilizando o minikube ou o k3s, eles são suficientes para fornecer uma base sólida para que você entenda seu funcionamento.
Mas este post é para aqueles que já conhecem e desejam criar uma infraestrutura em Kubernetes tolerante à falhas, a esta estrutura damos o nome de multi-master, pois existirão três máquinas responsáveis pela orquestração, cada uma com uma cópia do banco de dados, caso uma das máquinas caia, o funcionamento do cluster continua o mesmo.
Preciso de cloud?!
Esqueça a cloud, esqueça AWS, Azure, Google… você não precisa disso! é possível subir um cluster de Kubernetes na sua máquina ou mesmo na sua empresa. O Kubernetes não precisa funcionar exclusivamente dentro de uma nuvem.
Essa é uma vantagem do software livre e open source, com exclusão da sua própria máquina, você não precisa de mais nada a não ser vontade de aprender, mas lembre-se de contribuir com a comunidade, tudo bem?
Para nosso laboratório precisaremos de 3 coisas – uma delas é opcional:
- 4GB de memória RAM livres para as 4 máquinas
- Virtualbox
- Vagrant
Virtualbox
Precisamos de um hypervisor para criar as máquinas virtuais em nosso computador. O VirtualBox é mais do que o suficiente e funciona sem problemas nos mais variados sistemas operacionais.
Vagrant
Se você acompanha a 4Linux, já sabe que utilizamos o Vagrant para criar a infraestrutura que utilizamos para fazer os nossos testes e os nossos estudos.
Você não precisa necessariamente do Vagrant, pode-se baixar as imagens do Debian no próprio site https://www.debian.org/ e instalar as máquinas uma a uma, o resultado será similar, mas para acelerar o processo para os mais apressados vamos utilizar o Vagrant para criar a nossa infraestrutura dentro do Virtualbox.
Três Máquinas?
Um cluster multi-master pode ser provisionado de duas formas, mas o ponto mais importante é que precisarão existir três instâncias do etcd – o banco de dados “chave/valor” que guarda todo o estado do Kubernetes.
Escrevi duas formas porque podemos provisionar o etcd como um container dentro de cada master – a forma mais simples e justamente a que iremos utilizar, ou provisionar o etcd separado dos masters, e neste caso, poderemos utilizar apenas dois masters, pois as instâncias do etcd estarão em outro lugar.
Arquitetura Multi-Master
Existem várias formas de instalar o Kubernetes:
- Manualmente – semelhante ao https://github.com/kelseyhightower/kubernetes-the-hard-way
- Kubespray – utiliza playbooks do ansible baseadas no kubeadm
- Kubeadm – forma principal de instalação, e facilita a criação dos certificados e serviços necessários para o funcionamento do cluster.
Precisaremos de um balanceador – HAProxy – para centralizar o acesso aos masters:
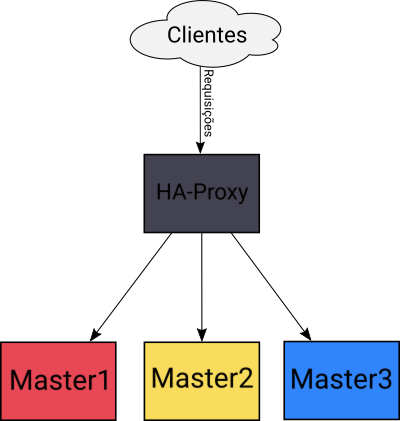
É importante dizer que logo no início da configuração, diremos aos masters que o endereço “geral” do cluster é o próprio endereço do load balancer. Isso significa que as requisições tanto de clientes, como do cluster ou mesmo dos próprios componentes de inicialização deverão passar pelo HA-Proxy.
Outro ponto importante é que começaremos a instalação pelo Master1. Somente o Master1 iniciará o cluster, os demais masters utilizarão as configurações existentes.
Vamos começar!
Instalação
Os próximos passos abordam a instalação do cluster.
1 – Criando o ambiente
Crie uma pasta em qualquer lugar do seu computador, dentro desta pasta colocaremos o arquivo do Vagrant responsável por configurar a infraestrutura necessária.
Como aqui na 4Linux sempre utilizamos Linux, os exemplos de comandos básicos de terminal serão baseados no Linux, tudo bem?
A pasta se chamará k8s-ha:
cd ~/ mkdir k8s-ha
Dentro desta pasta vamos criar um arquivo chamado Vagrantfile com a definição das nossas 4 máquinas:
cd k8s-ha
cat > Vagrantfile <<'EOF'
# -*- mode: ruby -*-
# vi: set ft=ruby :
vms = {
'balancer' => {'memory' => '256', 'cpus' => 1, 'ip' => '200'},
'master3' => {'memory' => '2048', 'cpus' => 2, 'ip' => '30'},
'master2' => {'memory' => '2048', 'cpus' => 2, 'ip' => '20'},
'master1' => {'memory' => '2048', 'cpus' => 2, 'ip' => '10'}
}
Vagrant.configure('2') do |config|
config.vm.box = 'debian/buster64'
config.vm.box_check_update = false
vms.each do |name, conf|
config.vm.define "#{name}" do |k|
k.vm.hostname = "#{name}.example.com"
k.vm.network 'private_network', ip: "172.27.11.#{conf['ip']}"
k.vm.provider 'virtualbox' do |vb|
vb.memory = conf['memory']
vb.cpus = conf['cpus']
end
end
end
end
EOFPronto! Vamos levantar nossas máquinas virtuais:
vagrant up
É muito importante ressaltar que todas as máquinas do cluster deverão possuir hostnames diferentes.
2 – Acessando o Ambiente
Uma vez que as máquinas estejam funcionando, poderemos acessá-las executando um simples comando do Vagrant dentro do diretório k8s-ha:
vagrant ssh master1
Os nomes das máquinas estão descritos no arquivo Vagrantfile mas também é possível verificá-los com o comando:
vagrant status
3 – Docker, binários do Kubernetes e ajustes
Os passos a seguir precisarão ser executados em todos os masters.
Como o Debian 10 modificou o comportamento do iptables que agora utiliza por padrão o nftables através de uma camada de compatibilidade. O kube-proxy – responsável pelo roteamento – não suporta esse tipo de configuração e acaba duplicando as rotas causando problemas.
Dessa forma, antes de tudo precisaremos modificar o iptables para se comportar do modo “legacy”:
update-alternatives --set iptables /usr/sbin/iptables-legacy update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy update-alternatives --set arptables /usr/sbin/arptables-legacy update-alternatives --set ebtables /usr/sbin/ebtables-legacy
Como o foco da instalação é a configuração do ambiente, executaremos um pequeno script que faz a instalação toda de uma vez.
Este script instalará o docker juntamente com os componentes do kubernetes kubelet, kubeadm e kubectl.
sudo su bash <<EOF # Lembre-se de executar nos outros masters! apt-get update apt-get install -y apt-transport-https ca-certificates curl gnupg2 software-properties-common vim curl -fsSL https://download.docker.com/linux/debian/gpg | apt-key add - add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/debian $(lsb_release -cs) stable" curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - echo 'deb https://apt.kubernetes.io/ kubernetes-xenial main' > /etc/apt/sources.list.d/kubernetes.list apt-get update apt-get install -y docker-ce docker-ce-cli containerd.io kubelet kubeadm kubectl apt-mark hold kubelet kubeadm kubectl EOF
Além da instalação dos componentes, precisaremos desabilitar o swap – existe uma issue a respeito do swap já faz um bom tempo, mas ainda não foi corrigido. Vou lhe ensinar um comando para desabilitar o swap de uma só vez e que persista durante as reinicializações:
sed -Ei 's/(.*swap.*)/#\1/g' /etc/fstab swapoff -a
O Docker instalado vem por padrão configurado com o cgroupdriver como cgroupfs e o Kubernetes recomanda o systemd, vamos alterá-lo:
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "journald"
}
EOF
systemctl restart dockerFeito isso, precisaremos fazer mais um pequeno ajuste no serviço do kubelet – responsável por levantar os containers base do cluster – pois estamos utilizando o Vagrant e existe mais de uma interface de rede em nossa máquina. Vamos configurar o kubelet para utilizar um endereço IP específico:
echo "KUBELET_EXTRA_ARGS='--node-ip=172.27.11.10'" > /etc/default/kubelet
Obs: Você precisará executar estes comandos em todos os masters, e lembre-se de trocar o final do IP para 20 e 30 ao executar este último comando.
Pronto! Vamos para o load balancer!
4 – Configurando o Load Balancer
A configuração do load balancer felizmente é muito simples graças a própria simplicidade do HAProxy. Apenas por curiosidade, o idealizador e desenvolvedor do HAProxy foi também um dos desenvolvedores do kernel Linux por muito tempo.
Vamos acessar o balancer, lembre-se de sair das outras máquinas virtuais e voltar para o diretório onde está o Vagrantfile:
cd ~/k8s-ha vagrant ssh balancer
Instale os pacotes do HAProxy, e você notará que ele é incrivelmente pequeno:
sudo su apt-get update apt-get install -y haproxy vim
Pronto! Vamos configurá-lo – para simplificar faremos em um único comando:
cat > /etc/haproxy/haproxy.cfg <<EOF global user haproxy group haproxy defaults mode http log global retries 2 timeout connect 3000ms timeout server 5000ms timeout client 5000ms frontend kubernetes bind 172.27.11.200:6443 option tcplog mode tcp default_backend kubernetes-master-nodes backend kubernetes-master-nodes mode tcp balance roundrobin option tcp-check server k8s-master-0 172.27.11.10:6443 check fall 3 rise 2 server k8s-master-1 172.27.11.20:6443 check fall 3 rise 2 server k8s-master-2 172.27.11.30:6443 check fall 3 rise 2 EOF
O arquivo parece um pouco assustador, mas é simples de entender:
- O HAProxy precisa de um frontend responsável por receber as conexões e um backend responsável por receber essas conexões.
- A interface de rede, o ip e a porta em que o HAProxy estará anexado é definido pelo bind.
- O modo de conexão deverá ser tcp e não http como fazemos com balanceadores para webservers.
- balance define o modo de balanceamento, neste caso round-robin – um diferente a cada conexão, existem outros como por exemplo leastconn, o menos carregado.
- tpc-check define que haverá verificação do status dos serviços dos servidores definidos
- server define cada máquina para onde o HAProxy redirecionará a conexão, precisarão de 3 falhas para sair da lista e 2 conexões bem sucedidades para voltar para a lista.
Vamos reiniciar o HAProxy e verificar se a porta está exposta – o que significa que o serviço está funcionando:
systemctl restart haproxy # Reinicia o serviço systemctl status haproxy # Verifica status do serviço ss -nltp | grep 6443 # Procura pelas portas TCP abertas
Pronto! Agora vamos focar na instalação do cluster!
5 – Configurando o primeiro Master
Vamos voltar para os masters. O primeiro master é o responsável por criar a configuração inicial juntamente com os certificados. É sua responsabilidade popular o primeiro etcd que será a base para os demais.
Para iniciar o cluster através do kubeadm é preciso criar um arquivo que indicará onde está o load balancer bem como qual o endereço de rede utilizaremos tanto para a máquina como para os containers.
Vamos criar este arquivo em /root/kubeadm-config.yml:
cat > /root/kubeadm-config.yml <<EOF apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: stable controlPlaneEndpoint: "172.27.11.200:6443" networking: podSubnet: "10.244.0.0/16" --- apiVersion: kubeadm.k8s.io/v1beta2 kind: InitConfiguration localAPIEndpoint: advertiseAddress: "172.27.11.10" bindPort: 6443 EOF
Com o arquivo pronto, vamos finalmente iniciar o primeiro master do cluster:
kubeadm init --config '/root/kubeadm-config.yml' --upload-certs
Ao final da configuração a saída no console será semelhante a seguinte:
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 172.27.11.200:6443 --token 2vjyq3.aaepezlc9szigtcp \ --discovery-token-ca-cert-hash sha256:fabea16da44390b45c1749e6fb4949ced6c82a1abd97cebe46db9bb175fa8566 \ --control-plane --certificate-key f936242f98d7d56a3b48963555eea669020716f81788414edf84044addaa7814 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 172.27.11.200:6443 --token 2vjyq3.aaepezlc9szigtcp \ --discovery-token-ca-cert-hash sha256:fabea16da44390b45c1749e6fb4949ced6c82a1abd97cebe46db9bb175fa8566
A primeira parte lhe explica como copiar o arquivo utilizado para a comunicação do kubectl com o cluster.
As linha seguintes explicam como adicionar outros masters – ou control planes – e outros nodes, respectivamente. Anote a linha de adição dos masters e dos nodes, vamos utilizar a dos masters nas outras máquinas.
Vamos aproveitar e copiar o arquivo de conexão para o usuário root:
mkdir -p /root/.kube cp /etc/kubernetes/admin.conf $HOME/.kube/config
Teste se a conexão com o cluster funciona:
kubectl get nodes
Deverá aparecer algo semelhante:
NAME STATUS ROLES AGE VERSION master1 NotReady master 4m51s v1.16.1
Não tenha receio, as máquinas ficarão Not Ready enquanto não configurarmos a rede, que é o nosso próximo passo!
6 – Configurando a rede no primeiro Master
Para que a comunicação entre os pods funcione, você precisa instalar um dos plugins de rede disponíveis, existem diversos. O Kubernetes não define um plugin de rede padrão, você precisa escolher, e neste caso vamos instalar o plugin do Calico. Caso você não entenda essa passo, sugiro que comece com um cluster simples, faça alguns testes e então volte para cá, você sempre será bem vindo.
Ainda na máquina master1 execute os seguintes comandos para baixar as definições do Calico, modificar a rede para 10.244.0.0/16 utilizada e adicioná-lo ao cluster. O endereço 10.244.0.0/16 foi o que definimos em nosso arquivo de inicialização do cluster:
cd /root wget https://docs.projectcalico.org/v3.9/manifests/calico.yaml sed -i 's?192.168.0.0/16?10.244.0.0/16?g' /root/calico.yaml kubectl apply -f /root/calico.yaml
7 – Configurando os outros Masters
Os passos que deverão ser executados antes de colarmos o comando fornecido pelo primeiro master são os seguintes:
- Instalar o Docker
- Instalar os binários do Kubernetes
- Desativar o swap
- Modificar o docker para utilizar o driver de cgroups para systemd
- Alterar o arquivo /etc/default/kubelet para utilizar o endereço ip correto
O comando que deveremos executar é exatamente o mesmo que o primeiro master nos mostrou com apenas uma modificação:
Deveremos especificar aqui também em qual interface este master estará escutando com a opção –apiserver-advertise-address=ip.da.maquina, neste caso vou exemplificar os comandos a partir da master2:
kubeadm join 172.27.11.200:6443 --token m2bj3h.fjf2tjccajgldqi2 \ --discovery-token-ca-cert-hash sha256:534305ca1b14a916c59f3d413f75158a6479a607ab97e9daf1212603c1683491 \ --control-plane --certificate-key c15d7c091fbbef93b3665b30d16e587fb37c1481f301bc11dc05cb27442c8181 --apiserver-advertise-address=172.27.11.20
Basta esperar um pouquinho… e pronto! Temos agora dois masters!
Execute a mesma sequência no master3 e lembre-se de modificar os endereços!
8 – Testando o Load Balancer e o cluster Multi-Master
Nosso cluster está pronto, vamos verificar! Vá para a máquina master1 pois lá configuramos o usuário root para acessar o cluster:
vagrant ssh master1 sudo su - kubectl get nodes
A saída deverá mostrar os três masters prontos:
NAME STATUS ROLES AGE VERSION master1 Ready master 21m v1.16.1 master2 Ready master 16m v1.16.1 master3 Ready master 4m58s v1.16.1
Seria pedir muito adicionar um outro node, muita gente não terá memória RAM suficiente, neste caso, vamos configurar os masters para aceitarem pods de aplicações:
kubectl taint nodes --all node-role.kubernetes.io/master-
E adicionar um pequeno DaemonSet para criar um pod em cada uma das máquinas:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: sh-cgi
labels:
name: sh-cgi
spec:
selector:
matchLabels:
name: sh-cgi
template:
metadata:
labels:
name: sh-cgi
spec:
containers:
- name: sh-cgi
image: hectorvido/sh-cgi
EOFE veja que existe um pod em cada máquina:
kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE sh-cgi-46xn6 1/1 Running 0 80s 10.244.137.65 master1 sh-cgi-btmq2 1/1 Running 0 80s 10.244.180.4 master2 sh-cgi-fmtjl 1/1 Running 0 80s 10.244.136.1 master3
Pronto! Seu cluster multi-master está funcionando! Para adicionar nodes comuns nessa infraestrutura, basta seguir os passos de instalação e modificação do docker e do /etc/kubelet/default. Porém, ao ingressar a máquina no cluster, executar o outro comando.
Caso você não tenha anotado, poderá pegar outro através do seguinte comando:
kubeadm token create --print-join-command
Obrigado!
E caso tenha mais dúvidas, venha fazer o nosso curso!
Entre em contato agora mesmo com nossos consultores!
About author

Você pode gostar também
Aumente a performance do Moodle com a configuração do MUC
O que é O MUC (Moodle Universal Cache) é um tipo de cache e um cache nada mais é do que um repositório de dados, que torna mais fácil e

Adeus containerd 1.x: as novidades que o Kubernetes 1.34 traz para o seu ambiente
E aí, pessoal! Tudo bem com vocês? Emerson da 4Linux chegando com um tema bem interessante que tem movimentado a comunidade: a nova versão do Kubernetes. Vem comigo para conferir

4Linux lança novos cursos DEVOPS: Integração e Entrega Contínua e Controle de Versões com Git
A 4linux lança esta semana dois novos cursos para atender a crescente procura por profissionais que conheça as ferramentas do mundo DEVOPS. O curso Integração e Entrega Continua com Git,






