
Conhecendo o kernel Linux pelo /proc (parte 4) – comportamentos da memória virtual
No post anterior vimos como o kernel mantem os mapeamentos de memória virtual para memória física e como essa tradução é realizada em tempo de execução pela MMU. Neste post iremos abordar alguns comportamentos relacionados ao uso de memória de virtual, como a “sobre-alocação” de memória, uso de SWAP, estouro de memória RAM e o que pode ocorrer em máquinas com uma grande quantidade de memória RAM.
Posso alocar mais memória do que o total disponível?
Como vimos anteriormente, os processos possuem um espaço de endereçamento virtual que é muito maior e independente do total de memória RAM disponível, isso, em teoria, permite que um processo realize alocação de um espaço muito maior do que o disponível em memória RAM. No entanto, esse comportamento, conhecido como “overcommit memory”, é controlado pelo kernel através do valor definido no arquivo /proc/sys/vm/overcommit_memory onde existem 3 opções:
- 0 – Permite o “overcommit” com uma heurística que evita alocações “massivas” e possui tratamento diferenciado para o usuário root. É a opção padrão da maioria das distribuições.
- 1 – Permite o “overcommit” de maneira irrestrita.
- 2 – Não permite o “overcommit”, e o tamanho máximo de memória alocada não pode ultrapassar o total de SWAP + uma porcentagem da memória RAM (definida em no arquivo /proc/sys/vm/overcommit_ratio)
Nosso primeiro programa de teste, o overcommit-alloc.c, realiza a alocação de uma área única de memória com tamanho definido através do primeiro parâmetro passado no momento da execução:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[]){
char *ptr;
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
ptr=malloc(1024*1024* (unsigned long) megabytes);
if(ptr==NULL){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
printf("Memoria alocada, pressiona qualquer tecla para desalocar\n");
getchar();
free(ptr);
printf("Memoria desalocada, pressiona qualquer tecla para encerrar\n");
getchar();
return 0;
}
Para ver na prática como isso funciona vamos executar nossos exemplos em uma VM com 512MB de RAM utilizando Vagrant (o Vagrantfile encontra-se disponível no repositório do Github) conforme as instruções abaixo:
$ gcc overcommit-alloc.c -o overcommit-alloc.o
$ vagrant up
$ vagrant ssh
vagrant@contrib-stretch:~$ free -m
total used free shared buff/cache available
Mem: 492 33 299 2 159 443
Swap: 1020 0 1020
vagrant@contrib-stretch:~$ cat /proc/sys/vm/overcommit_memory
0
vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 512
Memoria alocada, pressiona qualquer tecla para desalocar
Memoria desalocada, pressiona qualquer tecla para encerrar
vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 1024
Memoria alocada, pressiona qualquer tecla para desalocar
Memoria desalocada, pressiona qualquer tecla para encerrar
vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 1500
Falha ao alocar esta quantidade de memoria
Em um segundo terminal vamos acompanhar o campo “Committed_AS” do arquivo /proc/meminfo, que exibe o total de memória alocado em todo sistema:
root@contrib-stretch:/home/vagrant# cat /proc/meminfo | grep 'Committed_AS' ; # Antes da primeira execucao Committed_AS: 78808 kB root@contrib-stretch:/home/vagrant# cat /proc/meminfo | grep 'Committed_AS' ; # Durante a primeira execucao Committed_AS: 604036 kB root@contrib-stretch:/home/vagrant# cat /proc/meminfo | grep 'Committed_AS' ; # Durante a segunda execucao Committed_AS: 1128168 kB
Neste exemplo estamos com o comportamento de overcommit padrão (0), temos apenas 443MB de memória disponível para uso e podemos ver que conseguimos alocar mais memória do que o disponível quando realizamos a primeira execução com 512MB e quando realizamos a segunda execução com o dobro do total de memória RAM (1024MB). Somente quando tentamos realizar uma alocação mais abusiva (1500MB) a heurística do kernel negou a alocação.
Agora vamos repetir este mesmo exemplo com o arquivo overcommit-multiple-alloc.o, que realiza duas alocações de memória com o tamanho informado na execução:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[]){
char *ptr1,*ptr2;
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
ptr1=malloc(1024*1024* (unsigned long) megabytes);
if(ptr1==NULL){
printf("Falha ao realizar a primeira alocação\n");
return 1;
}
ptr2=malloc(1024*1024* megabytes);
if(ptr2==NULL){
printf("Falha ao realizar a segunda alocação\n");
return 1;
}
printf("Memoria alocada, pressiona qualquer tecla para desalocar\n");
getchar();
free(ptr1);
free(ptr2);
printf("Memoria desalocada, pressiona qualquer tecla para encerrar\n");
getchar();
return 0;
}
$ gcc overcommit-multiple-alloc.c -o overcommit-multiple-alloc.o $ vagrant ssh vagrant@contrib-stretch:~$ /vagrant/overcommit-multiple-alloc.o 512 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar vagrant@contrib-stretch:~$ /vagrant/overcommit-multiple-alloc.o 1024 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar vagrant@contrib-stretch:~$ /vagrant/overcommit-multiple-alloc.o 1500 Falha ao realizar a primeira alocação
Em um segundo terminal vamos acompanhar a alocação total do sistema:
# cat /proc/meminfo | grep 'Committed_AS' ; # Antes da primeira execucao Committed_AS: 79916 kB root@contrib-stretch:/home/vagrant# cat /proc/meminfo | grep 'Committed_AS' ; # Durante a primeira execucao Committed_AS: 1129068 kB root@contrib-stretch:/home/vagrant# cat /proc/meminfo | grep 'Committed_AS' ; # Durante a segunda execucao Committed_AS: 2176748 kB
Através deste segundo exemplo podemos ver que a heurística de controle de overcommit do kernel atua sobre cada alocação de forma isolada, pois nesta execução nosso programa conseguiu alocar dois blocos de 1024MB que somados atingem 2GB, ultrapassando os 1500MB que foram negados no nosso programa anterior, no entanto, também não conseguiu realizar a primeira alocação de 1500MB.
Agora vamos refazer nossos testes alterando o overcommit_memory para 1, ou seja, a alocação deve ser irrestrita:
$ vagrant ssh vagrant@contrib-stretch:~$ sudo su root@contrib-stretch:/home/vagrant# echo 1 > /proc/sys/vm/overcommit_memory root@contrib-stretch:/home/vagrant# exit vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 1500 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 4096 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 16032 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 32096 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar
Neste exemplo iniciamos com a alocação de 1500MB, que já ultrapassava o limite de alocação única no modo heurístico e seguimos alocando 4GB, 16GB, 32GB, e poderíamos continuar alocando memória sem maiores problemas.
Apesar deste modo parecer desnecessário e perigoso para a maioria dos casos, existem cenários onde ele é útil. A própria documentação do kernel cita seu uso com aplicações científicas que precisam realizar alocação de longos arrays esparsos, na qual a utilização de memória efetiva é muito pequena.
Agora vamos realizar novamente nossos testes, porém no modo 2, ou seja, não permitindo a realização do overcommit.
$ vagrant ssh $ vagrant@contrib-stretch:~$ sudo su root@contrib-stretch:/home/vagrant# echo 2 > /proc/sys/vm/overcommit_memory root@contrib-stretch:/home/vagrant# cat /proc/sys/vm/overcommit_ratio 50 root@contrib-stretch:/home/vagrant# exit vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 512 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 1024 Memoria alocada, pressiona qualquer tecla para desalocar Memoria desalocada, pressiona qualquer tecla para encerrar vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc.o 1500 Falha ao alocar esta quantidade de memoria
Na execução acima, mesmo no modo 2, ainda conseguimos alocar mais memória (1024MB) do que o total de memória RAM (512MB). Parece um comportamento inesperado, mas não é. Isso acontece devido ao kernel levar em consideração também o tamanho de swap disponível no sistema. A conta realizada pelo kernel para definir o limite de alocação é: TOTAL_SWAP + ( overcommit_ratio/100 * RAM), que neste caso é 1024MB + (50/100 * 512MB) = 1280MB, por isso conseguimos alocar os 1024MB.
Outro ponto importante é que neste modo, o kernel impõe este limite de forma global, ou seja, se executarmos o programa presente em overcommit-multiple-alloc.o passando o valor de 1024MB como parâmetro, ele deve falhar na segunda alocação:
$ vagrant ssh vagrant@contrib-stretch:~$ /vagrant/overcommit-multiple-alloc.o 1024 Falha ao realizar a segunda alocação
Quando estamos trabalhando com o kernel neste modo, podemos acompanhar através do /proc/meminfo no campo “CommitLimit” e “Committed_AS” o limite de alocação e o total alocado atualmente:
vagrant@contrib-stretch:~$ cat /proc/meminfo | grep 'CommitLimit' CommitLimit: 1297556 kB
A saída acima mostra o limite total de alocação 1297556kB (~1267MB), que é muito próximo do valor que calculamos anteriormente (1280MB).
E se a memória acabar?
Neste caso o kernel irá utilizar o SWAP, que é uma área em disco (podendo ser uma partição ou um arquivo do sistema de arquivos) destinada a armazenar páginas de memória não utilizadas no momento.
O SWAP pode parecer uma necessidade somente de ambientes com pouca memória RAM e muitas pessoas acreditam que quando temos algum uso de SWAP estamos com falta de memória RAM. No entanto, isso nem sempre é verdade, pois o uso de SWAP pode ocorrer em cenários onde existem áreas de memória não utilizadas por um longo período, onde o kernel acaba priorizando a memória RAM para outros fins e acaba movendo essas áreas para SWAP. Esse comportamento acaba sendo benéfico para aplicações que utilizam grandes quantidades de memória em sua inicialização e dificilmente voltam a utilizar a mesma área novamente.
O que realmente indica a falta de memória e representa um problema de desempenho é um fluxo de páginas entrando e saindo do SWAP, pois isso indica que temos processos requisitando páginas em SWAP, o que leva a leitura de disco e o que por sua vez é muito mais lento que o acesso a memória (mesmo com discos de alto desempenho) e com certeza irá degradar a desempenho do sistema.
Outro indício de falta de memória é ver a thread do kernel kswapd constantemente ativa e consumindo CPU, já que ela só deve estar ativa em situações de esgotamento de memória, pois em condições normais o Kernel realiza a liberação de memória através dos seu algoritmos baseados em LRU.
Agora vamos ver como o /proc pode nos mostrar como está o estado do SWAP do nosso sistema, utilizando o overcommit-alloc-initialize.c para estressar o sistema alocando e utilizando uma grande quantidade de memória. O overcommit-alloc-initialize.c é uma variação do overcommit-alloc.c que utiliza a memória alocada preenchendo com o caracter “a”.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
unsigned long i;
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
ptr=malloc(1024*1024* (unsigned long) megabytes);
if(ptr==NULL){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
tmp_ptr=ptr;
for(i=0;i<1024*1024* (unsigned long) megabytes; i++){
strcpy(tmp_ptr,"a");
tmp_ptr++;
}
printf("Memoria alocada, pressiona qualquer tecla para desalocar\n");
getchar();
free(ptr);
printf("Memoria desalocada, pressiona qualquer tecla para encerrar\n");
getchar();
return 0;
}
$ vagrant ssh vagrant@contrib-stretch:~$ sudo su root@contrib-stretch:/home/vagrant# echo 0 > /proc/sys/vm/overcommit_memory root@contrib-stretch:/home/vagrant# exit vagrant@contrib-stretch:~$ /vagrant/overcommit-alloc-initialize.o 1024 Memoria alocada, pressiona qualquer tecla para desalocar
Em outro terminal vamos consultar o estado da máquina:
vagrant@contrib-stretch:~$ cat /proc/meminfo | egrep 'SwapTotal|SwapFree|MemTotal|MemFree|MemAvailable|Cached'
SwapTotal: 1045500 kB
SwapFree: 120524 kB
MemTotal: 504112 kB
MemFree: 305312 kB
MemAvailable: 319176 kB
Buffers: 3380 kB
Cached: 15520 kB
vagrant@contrib-stretch:~$ free -m
total used free shared buff/cache available
Mem: 492 167 298 0 26 311
Swap: 1020 903 117
Na execução acima, inicialmente garantimos que o kernel volte para o modo padrão de “overcommit” (0), e em seguida iniciamos o nosso o
overcommit-alloc-initialize.o solicitando a alocação e utilização de 1GB.
Como nossa máquina tem apenas 512MB de RAM, é certo que essa execução irá utilizar SWAP, o que podemos confirmar através do /proc/meminfo através da diferença entre os campos SwapTotal e SwapFree, o que resulta em 903MB utilizados de SWAP e que ainda existe por volta de 311MB disponíveis para uso em RAM (MemAvailable), o que nos leva a crer que quase todo o conteúdo gerado pelo nosso programa encontra-se em SWAP.
Para checar se é realmente o nosso processo que está consumindo o SWAP, podemos consultar o arquivo /proc/PID/status nos campos VmSwap e VmRSS:
vagrant@contrib-stretch:~$ cat /proc/$(pgrep -f overcommit-alloc-initialize.o)/status | egrep 'VmSwap|VmRSS' VmRSS: 141872 kB VmSwap: 906776 kB
De acordo com a saída acima podemos concluir que quase 100% do uso de SWAP está sendo utilizado pelo nosso processo (885MB) e que ele apenas está consumindo 138MB de memória RAM, o que para esta aplicação é um comportamento extremamente benéfico, já que esta área de memória nunca mais será utilizada.
Agora vamos utilizar uma variação desse programa que realiza a leitura dessa área de memória posteriormente à inicialização, o overcommit-alloc-read.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
unsigned long i;
char str[50];
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
ptr=malloc(1024*1024* (unsigned long) megabytes);
if(ptr==NULL){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
tmp_ptr=ptr;
for(i=0;i<1024*1024* (unsigned long) megabytes; i++){
strcpy(tmp_ptr,"a");
tmp_ptr++;
}
printf("Memoria alocada, pressiona qualquer tecla para iniciar a leitura\n");
getchar();
tmp_ptr=ptr;
for(i=0;i<1024*1024* (unsigned long) megabytes; i++){
sprintf(str,"Aqui: %c",*tmp_ptr);
tmp_ptr++;
}
free(ptr);
printf("Memoria desalocada, pressiona qualquer tecla para encerrar\n");
getchar();
return 0;
}
Neste exemplo vamos utilizar três terminais, uma para execução do overcommit-alloc-read.o, outro para visualizar o resultado do comando top e um último para monitorar o arquivo /proc/vmstat:
Terminal 1:
vagrant@contrib-stretch:~$ time /vagrant/overcommit-alloc-read.o 1024 Memoria alocada, pressiona qualquer tecla para iniciar a leitura Memoria desalocada, pressiona qualquer tecla para encerrar real 1m40.074s user 0m56.712s sys 0m3.660s
Terminal 2:

Terminal 3:
vagrant@contrib-stretch:~$ cat /proc/vmstat | egrep 'pswpin|pswpout' #antes da execução pswpin 796519 pswpout 2249486 vagrant@contrib-stretch:~$ cat /proc/vmstat | egrep 'pswpin|pswpout' #com a memoria alocada pswpin 797068 pswpout 2399606 vagrant@contrib-stretch:~$ cat /proc/vmstat | egrep 'pswpin|pswpout' #apos a execucao pswpin 1059810 pswpout 2664169
Na execução acima realmente sentimos o impacto do uso de SWAP, ou seja, nossa aplicação precisou utilizar uma área de memória virtual que estava armazenada em SWAP, o que elevou nosso tempo de execução por volta de 1min e 40 segundos. Além disso podemos ver no segundo terminal, através do comando top, que a thread do kernel kswapd precisou entrar em ação e que tivemos 4% de uso de CPU por sistema e 4% de espera por IO.
No terceiro terminal, podemos observar através do arquivo /proc/vmstat, nos campos pswpin e pswpout, a quantidade de páginas recuperadas do swap e a quantidade de páginas enviadas para swap respectivamente. Neste caso vemos que logo após a alocação e utilização da área de memória temos 150120 (2399606−2249486) páginas sendo enviadas para SWAP e quando terminamos de ler esta área de memória novamente o sistema precisou carregar 262742 páginas de disco para memória, que é o que realmente impacta na execução do nosso programa.
E se o swap acabar?
Se a memória RAM acabar, a área SWAP acabar e o “overcommit memory” estiver permitido é muito provável que ocorra o famoso OOM (Out Of Memory) Killer, que é um recurso do kernel ativado em situações críticas, para matar processos e liberar memória evitando um possível crash completo do sistema operacional como um kernel panic.
Ao contrário do que possa parecer, o OOM Killer possui um heurística interna para definir qual o processo deve ser morto baseado em um score que leva em conta a memória consumida, o tempo de execução, privilégios (capabilities) e prioridade do processo. De maneira geral, podemos dizer que o objetivo do OOM Killer é tentar obter a maior quantidade de memória matando o menor número de processos possível.
Para entender como isso funciona vamos utilizar o oom-killer.c, que é bem similar ao código anterior, apenas acrescentando algumas confirmações para que possamos monitorá-lo antes, durante e depois da memória ser alocada e utilizada:
oom-killer.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
unsigned long i;
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
printf("Pressione qualquer tecla para alocar a memoria:\n");
getchar();
ptr=malloc(1024*1024* (unsigned long) megabytes);
if(ptr==NULL){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
printf("Pressione qualquer tecla para inicializar a memoria:\n");
getchar();
tmp_ptr=ptr;
for(i=0;i<1024*1024* (unsigned long) megabytes; i++){
strcpy(tmp_ptr,"a");
tmp_ptr++;
}
printf("Memoria alocada, pressiona qualquer tecla para desalocar\n");
getchar();
free(ptr);
printf("Memoria desalocada, pressiona qualquer tecla para encerrar\n");
getchar();
return 0;
}
Neste exemplo vamos utilizar três terminais, um para execução do primeiro oom-killer.o, outro para o /proc e um último para executar um segundo oom-killer.o:
$ gcc oom-killer.c -o oom-killer.o $ vagrant ssh vagrant@contrib-stretch:~$ sudo su root@contrib-stretch:/home/vagrant# echo 1 > /proc/sys/vm/overcommit_memory root@contrib-stretch:/home/vagrant# exit vagrant@contrib-stretch:~$ /vagrant/oom-killer.o 1024 Pressione qualquer tecla para alocar a memoria: Pressione qualquer tecla para inicializar a memoria: Memoria alocada, pressiona qualquer tecla para desalocar
Agora no segundo terminal vamos consultar o score atual para OOM Killer do Kernel (quanto maior o número, maior a probabilidade do processo ser morto) através do /proc/PID/oom_score:
vagrant@contrib-stretch:~$ cat /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score #Sem alocar memoria 0 vagrant@contrib-stretch:~$ cat /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score #Com memoria alocada 0 vagrant@contrib-stretch:~$ cat /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score #Com memoria inicializada 678
No terceiro terminal vamos executar mais um oom-killer.o tentando alocar mais 1GB de memória:
$ /vagrant/oom-killer.o 1024 Pressione qualquer tecla para alocar a memoria: Pressione qualquer tecla para inicializar a memoria: Memoria alocada, pressiona qualquer tecla para desalocar
Agora vamos ver o aconteceu com o primeiro terminal:
vagrant@contrib-stretch:~$ /vagrant/oom-killer.o 1024 Pressione qualquer tecla para alocar a memoria: Pressione qualquer tecla para inicializar a memoria: Memoria alocada, pressiona qualquer tecla para desalocar Killed
Na execução acima podemos ver que o score que define a probabilidade de um processo ser morto, em caso de falta de memória, aumenta consideravelmente conforme o uso residente de memória, afinal o score aumentou de 0 para 678 assim que sua memória foi efetivamente utilizada. Também podemos ver que devido ao alto score do primeiro processo, ele foi o escolhido para o “sacrifício” quando executamos o segundo processo em paralelo.
Outro ponto que podemos observar quando ocorre um OOM Killer são os logs do sistema, que normalmente trazem o processo que estava requerendo memória, a pilha de execução do momento e a listagem de processos do momento do incidente com seu consumo de memória:
root@contrib-stretch:/home/vagrant# tail -n 300 /var/log/syslog Oct 14 02:54:23 contrib-stretch kernel: [1291138.435776] oom-killer.o invoked oom-killer: gfp_mask=0x24280ca(GFP_HIGHUSER_MOVABLE|__GFP_ZERO), nodemask=0, order=0, oom_score_adj=0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435777] oom-killer.o cpuset=/ mems_allowed=0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435782] CPU: 0 PID: 28628 Comm: oom-killer.o Tainted: G O 4.9.0-12-amd64 #1 Debian 4.9.210-1 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435782] Hardware name: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435784] 0000000000000000 ffffffff92736bfe ffffab79c0387cf0 ffff8d57dd355000 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435786] ffffffff92609adb 0000000000000000 0000000000000000 0000000c92755c09 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435788] ffff8d57daa9d0c0 ffffffff9258d587 0000004200000000 0000000000000001 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435790] Call Trace: Oct 14 02:54:23 contrib-stretch kernel: [1291138.435815] [] ? dump_stack+0x66/0x88 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435819] [] ? dump_header+0x78/0x1fd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435821] [] ? get_page_from_freelist+0x3f7/0xb20 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435823] [] ? oom_kill_process+0x22a/0x3f0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435824] [] ? out_of_memory+0x111/0x470 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435826] [] ? __alloc_pages_slowpath+0xa1f/0xb30 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435827] [] ? __alloc_pages_nodemask+0x201/0x260 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435829] [] ? alloc_pages_vma+0xaa/0x280 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435831] [] ? handle_mm_fault+0x10ff/0x1350 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435832] [] ? __do_page_fault+0x255/0x4f0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435836] [] ? schedule+0x32/0x80 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435838] [] ? page_fault+0x28/0x30 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435867] Mem-Info: Oct 14 02:54:23 contrib-stretch kernel: [1291138.435870] active_anon:58278 inactive_anon:58312 isolated_anon:0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435870] active_file:11 inactive_file:17 isolated_file:0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435870] unevictable:0 dirty:0 writeback:7 unstable:0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435870] slab_reclaimable:1927 slab_unreclaimable:2281 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435870] mapped:30 shmem:28 pagetables:1353 bounce:0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435870] free:1131 free_pcp:60 free_cma:0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435872] Node 0 active_anon:233112kB inactive_anon:233248kB active_file:44kB inactive_file:68kB unevictable:0kB isolated(anon):0kB isolated(file):0kB mapped:120kB dirty:0kB writeback:28kB shmem:112kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB unstable:0kB pages_scanned:3372 all_unreclaimable? yes Oct 14 02:54:23 contrib-stretch kernel: [1291138.435873] Node 0 DMA free:1908kB min:88kB low:108kB high:128kB active_anon:13716kB inactive_anon:184kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:15992kB managed:15908kB mlocked:0kB slab_reclaimable:0kB slab_unreclaimable:12kB kernel_stack:0kB pagetables:84kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB Oct 14 02:54:23 contrib-stretch kernel: [1291138.435876] lowmem_reserve[]: 0 455 455 455 455 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435878] Node 0 DMA32 free:2616kB min:2684kB low:3352kB high:4020kB active_anon:219388kB inactive_anon:233068kB active_file:44kB inactive_file:68kB unevictable:0kB writepending:28kB present:507840kB managed:488204kB mlocked:0kB slab_reclaimable:7708kB slab_unreclaimable:9112kB kernel_stack:1456kB pagetables:5328kB bounce:0kB free_pcp:240kB local_pcp:240kB free_cma:0kB Oct 14 02:54:23 contrib-stretch kernel: [1291138.435881] lowmem_reserve[]: 0 0 0 0 0 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435884] Node 0 DMA: 1*4kB (U) 0*8kB 1*16kB (M) 1*32kB (M) 1*64kB (U) 2*128kB (UM) 2*256kB (UM) 0*512kB 1*1024kB (U) 0*2048kB 0*4096kB = 1908kB Oct 14 02:54:23 contrib-stretch kernel: [1291138.435892] Node 0 DMA32: 116*4kB (UME) 71*8kB (E) 9*16kB (E) 11*32kB (UME) 1*64kB (U) 0*128kB 0*256kB 2*512kB (UM) 0*1024kB 0*2048kB 0*4096kB = 2616kB Oct 14 02:54:23 contrib-stretch kernel: [1291138.435901] Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB Oct 14 02:54:23 contrib-stretch kernel: [1291138.435902] 373 total pagecache pages Oct 14 02:54:23 contrib-stretch kernel: [1291138.435903] 300 pages in swap cache Oct 14 02:54:23 contrib-stretch kernel: [1291138.435904] Swap cache stats: add 4816960, delete 4816660, find 1408928/1597656 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435904] Free swap = 0kB Oct 14 02:54:23 contrib-stretch kernel: [1291138.435904] Total swap = 1045500kB Oct 14 02:54:23 contrib-stretch kernel: [1291138.435905] 130958 pages RAM Oct 14 02:54:23 contrib-stretch kernel: [1291138.435905] 0 pages HighMem/MovableOnly Oct 14 02:54:23 contrib-stretch kernel: [1291138.435906] 4930 pages reserved Oct 14 02:54:23 contrib-stretch kernel: [1291138.435906] 0 pages hwpoisoned Oct 14 02:54:23 contrib-stretch kernel: [1291138.435907] [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name Oct 14 02:54:23 contrib-stretch kernel: [1291138.435910] [ 188] 0 188 13890 31 23 3 95 0 systemd-journal Oct 14 02:54:23 contrib-stretch kernel: [1291138.435912] [ 197] 0 197 11515 0 23 3 296 -1000 systemd-udevd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435913] [ 347] 0 347 11625 24 29 3 115 0 systemd-logind Oct 14 02:54:23 contrib-stretch kernel: [1291138.435915] [ 348] 0 348 7409 8 19 3 55 0 cron Oct 14 02:54:23 contrib-stretch kernel: [1291138.435916] [ 349] 105 349 11278 0 26 3 120 -900 dbus-daemon Oct 14 02:54:23 contrib-stretch kernel: [1291138.435918] [ 361] 0 361 62528 18 29 3 206 0 rsyslogd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435919] [ 376] 0 376 3631 0 12 3 37 0 agetty Oct 14 02:54:23 contrib-stretch kernel: [1291138.435921] [ 404] 0 404 17489 0 39 3 206 -1000 sshd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435922] [ 437] 0 437 78758 0 30 3 174 0 VBoxService Oct 14 02:54:23 contrib-stretch kernel: [1291138.435923] [ 671] 107 671 14038 0 31 3 191 0 exim4 Oct 14 02:54:23 contrib-stretch kernel: [1291138.435925] [ 761] 0 761 5089 0 14 3 258 0 dhclient Oct 14 02:54:23 contrib-stretch kernel: [1291138.435927] [20620] 1000 20620 16210 0 35 3 216 0 systemd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435928] [20621] 1000 20621 20618 0 41 3 400 0 (sd-pam) Oct 14 02:54:23 contrib-stretch kernel: [1291138.435930] [28561] 0 28561 23795 1 49 4 241 0 sshd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435931] [28567] 1000 28567 23871 43 48 4 229 0 sshd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435932] [28568] 1000 28568 5228 0 14 3 414 0 bash Oct 14 02:54:23 contrib-stretch kernel: [1291138.435934] [28603] 0 28603 23795 1 50 3 241 0 sshd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435935] [28609] 1000 28609 23864 28 49 3 242 0 sshd Oct 14 02:54:23 contrib-stretch kernel: [1291138.435936] [28610] 1000 28610 5249 210 15 3 213 0 bash Oct 14 02:54:23 contrib-stretch kernel: [1291138.435938] [28620] 1000 28620 263185 5435 520 4 256726 0 oom-killer.o Oct 14 02:54:23 contrib-stretch kernel: [1291138.435939] [28628] 1000 28628 263185 110295 225 4 0 0 oom-killer.o Oct 14 02:54:23 contrib-stretch kernel: [1291138.435940] Out of memory: Kill process 28620 (oom-killer.o) score 678 or sacrifice child Oct 14 02:54:23 contrib-stretch kernel: [1291138.436071] Killed process 28620 (oom-killer.o) total-vm:1052740kB, anon-rss:21740kB, file-rss:0kB, shmem-rss:0kB
No entanto, existem alguns parâmetros que nos permitem alterar o processo de escolha do OOM Killer, o primeiro parâmetro que vamos ver é definido no /proc/PID/oom_score_adj e nos permite somar ou reduzir o score do processo em questão.
Terminal 1:
vagrant@contrib-stretch:~$ /vagrant/oom-killer.o 1024 Pressione qualquer tecla para alocar a memoria: Pressione qualquer tecla para inicializar a memoria: Memoria alocada, pressiona qualquer tecla para desalocar
Terminal 2:
vagrant@contrib-stretch:~$ cat /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score 678 vagrant@contrib-stretch:~$ sudo su root@contrib-stretch:/home/vagrant# echo '-100' > /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score_adj root@contrib-stretch:/home/vagrant# cat /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score 578 root@contrib-stretch:/home/vagrant# echo '-800' > /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score_adj root@contrib-stretch:/home/vagrant# exit vagrant@contrib-stretch:~$ cat /proc/$(pgrep -f /vagrant/oom-killer.o)/oom_score 0
Terminal 3:
vagrant@contrib-stretch:~$ /vagrant/oom-killer.o 1024 Pressione qualquer tecla para alocar a memoria: Pressione qualquer tecla para inicializar a memoria: Killed
Neste exemplo acima podemos ver que com o parâmetro oom_score_adj do primeiro processo definido para -800, seu score caiu para 0, o que levou o OOM Killer selecionar o segundo processo para o “sacrifício”.
O outro parâmetro que podemos ajustar é o /proc/PID/oom_adj que tem efeito similar ao oom_score_adj, no entanto ele encontra-se depreciado desde a versão 2.6.36 do kernel.
Por fim ainda temos a possibilidade de desabilitar completamente o OOM Killer através do /proc/sys/vm/panic_on_oom, no entanto isso não é algo muito recomendado, pois pode levar a um kernel panic com crash total do sistema, o que pode ser visto na execução abaixo:
Terminal 1:
$ vagrant shh vagrant@contrib-stretch:~$ sudo su root@contrib-stretch:/home/vagrant# echo 1 > /proc/sys/vm/panic_on_oom root@contrib-stretch:/home/vagrant# exit vagrant@contrib-stretch:~$ /vagrant/oom-killer.o 1024 Pressione qualquer tecla para alocar a memoria: Pressione qualquer tecla para inicializar a memoria: Memoria alocada, pressiona qualquer tecla para desalocar
Terminal 2:
$ vagrant ssh vagrant@contrib-stretch:~$ /vagrant/oom-killer.o 1024 Pressione qualquer tecla para alocar a memoria: Pressione qualquer tecla para inicializar a memoria:
Apos esse momento a máquina congela, e só podemos ver o que ocorreu através do console do VirtualBox:
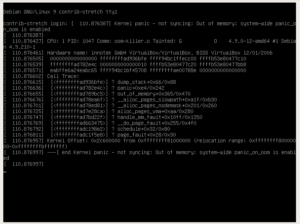
Como podemos ver, ocorreu um kernel panic e agora somente um reboot forçado para retomar o acesso a máquina, o que reforça a recomendação de manter o OOM Killer sempre ativo, e se esse comportamento do OOM Killer for inadequado para o seu ambiente é preferível ajustar o “overcommit_memory” para o modo 2 (modo restritivo), onde o kernel não vai permitir a super-alocação de memória, o que por sua vez diminui drasticamente a probabilidade de um evento de falta de memória ocorrer.
E se tiver muita memória RAM?
Ter uma grande quantidade de memória RAM no sistema pode parece ser uma excelente ideia para minimizar a probabilidade do uso SWAP e evitar situações de estouro de memória e ativação do OOM Killer. No entanto, quando se trabalha com grandes quantidades de memória RAM passamos a enfrentar novos desafios relacionados a gerência de um número excessivo de páginas de memória.
Imagine um servidor com 1TB de memória RAM, onde temos processos que utilizam mais de 100GB de memória, realizando um cálculo rápido, levando em conta uma página de memória de 4KB, esses processos teriam de lidar com algo em torno de 26 milhões de páginas cada. Isso pode impactar diretamente no desempenho do sistema, pois o kernel teria de gerenciar tabelas de mapeamento com milhões de páginas em diversos processos e levando em conta a capacidade do TLB de um processador moderno (Intel Sky Lake/Core I3/5/7 de 6 geração) de 128 entradas para instruções, 64 entradas para dados, 1536 entradas compartilhadas de segundo nível, seria inevitável o esgotamento do TLB, o que iria forçar a MMU percorrer a PGD constantemente para encontrar as páginas solicitadas.
Felizmente o kernel possui um recurso para minimizar este problema, o “HugePages”, que basicamente é a capacidade de trabalhar com páginas de memória maiores do que o normal, no caso da arquitetura x86-64 e além das páginas de 4KB, temos a possibilidade de trabalhar com páginas de 2MB e 1GB.
De maneira geral o HugePages tem o objetivo de:
- Diminuir o overhead do kernel sobre a manutenção das tabelas de mapeamento de memória dos processos
- Aproveitar melhor o TLB, que é um recurso escasso e de fundamental importância para o desempenho dos processos
Atualmente o kernel permite a utilização explícita de HugePages através do “Hugetlbpage” e a utilização de forma transparente, que não requer alterações nas aplicações, através do THP (Transparent Huge Pages).
Hugetlbpage
O Hugetlbpage permite o uso de HugePages de forma explícita pelas aplicações através de chamadas “mmap” ou através do uso de memória compartilhada. No entanto, para ambos os métodos é necessário indicar previamente para o kernel o número de HugesPages a ser reservado na memória RAM através do /proc/sys/vm/nr_hugepages e uma quantidade adicional de páginas que o kernel tentará alocar, caso seja necessário, através do /proc/sys/vm/nr_overcommit_hugepages.
Vale lembrar que as páginas reservadas para HugePages não podem ser utilizadas para outros fins e também não podem ser enviadas para swap, então o ideal é não exagerar nesta configuração e utilizá-la de acordo com o necessário especificado pelas aplicações.
O tamanho da HugePage padrão pode ser consultado através do /proc/meminfo no item “Hugepagesize” e só pode ser alterado no boot através do parâmetro default_hugepagesz.
Para realizar a alocação através da chamada mmap temos duas opções: a primeira é realizar a chamada requerendo memória anonima com a flag MAP_HUGETLB e a segunda é realizar a chamada requerendo o mapeamento de arquivo em memória que resida em um ponto de montagem do tipo hugetlbfs, que deve ser montado previamente.
Para alocação através do uso de memória compartilhada (shmget e shmat) é necessário o uso da flag SHM_HUGETLB e que o usuário que é dono processo pertença ao grupo definido no arquivo /proc/sys/vm/hugetlb_shm_group.
Para ver como tudo isso tudo funciona na prática, preparamos dois programas que alocam e utilizam uma quantidade de memória via MMAP, sendo que um utiliza HugePages e o outro não:
hugepage-off.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
unsigned long i;
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
ptr=mmap(0,1024*1024* (unsigned long) megabytes,PROT_WRITE|PROT_READ,MAP_PRIVATE|MAP_ANONYMOUS,-1,0);
if(ptr==MAP_FAILED){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
tmp_ptr=ptr;
for(i=0;i+1<1024*1024* (unsigned long) megabytes; i++){
strcpy(tmp_ptr,"a");
tmp_ptr++;
}
printf("Memoria alocada\n");
munmap(ptr,1024*1024* (unsigned long) megabytes);
printf("Memoria desalocada\n");
return 0;
}
hugepage-on.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
unsigned long i;
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
ptr=mmap(0,1024*1024* (unsigned long) megabytes,PROT_WRITE|PROT_READ,MAP_HUGETLB|MAP_PRIVATE|MAP_ANONYMOUS,-1,0);
if(ptr==MAP_FAILED){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
tmp_ptr=ptr;
for(i=0;i-1<1024*1024* (unsigned long) megabytes; i++){
strcpy(tmp_ptr,"a");
tmp_ptr++;
}
printf("Memoria alocada\n");
munmap(ptr,1024*1024* (unsigned long) megabytes);
printf("Memoria desalocada\n");
return 0;
}
Inicialmente vamos tentar iniciar o hugepage-on.o com 200MB de memória:
$ ./hugepage-on.o 200 Falha ao alocar esta quantidade de memoria
Isso acontence devido a não existirem HugePages disponíveis para alocação, o que pode ser visto através do /proc/meminfo nos campos HugePages_Total e HugePages_Free:
# cat /proc/meminfo | grep '^Huge' HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB
A saída acima indica que não existem HugePages disponíveis e que não existe nenhuma reserva de memória para HugePages, o que pode ser verificado e alterado através do /proc/sys/vm/nr_hugepages:
# cat /proc/sys/vm/nr_hugepages 0 # echo 200 > /proc/sys/vm/nr_hugepages # cat /proc/meminfo | grep '^Huge' HugePages_Total: 78 HugePages_Free: 78 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB
Apesar de parecer um comportamento inesperado, solicitar a reserva de uma quantidade de páginas para HugePages no nr_hugepages e visualizar uma quantidade menor no /proc/meminfo, é um comportamento perfeitamente normal, pois é comum que o kernel não consiga reservar a quantidade de memória solicitada devido a fragmentação da memória RAM. A única forma de garantir a reserva é incluir o parâmetro hugepages=N no boot do kernel.
No nosso caso, o kernel só conseguiu reservar 78 páginas, o que daria por volta de 156MB, por isso vamos executar nossos testes alocando 140MB:
# time ./hugepage-off.o 140 Memoria alocada Memoria desalocada real 0m0,445s user 0m0,392s sys 0m0,045s # time ./hugepage-on.o 140 Memoria alocada Memoria desalocada real 0m0,004s user 0m0,001s sys 0m0,003s
Na execução acima podemos ver que, mesmo com uma quantidade pequena de memória, ou seja. “140MB”, temos uma diferença de desempenho considerável, por volta de 400ms para a versão sem HugePages e 4ms para versão com HugePages.
Para ver a diferença entre as execuções vamos utilizar a ferramenta perf-stat:
# perf stat -d ./hugepage-off.o 140
Memoria alocada
Memoria desalocada
Performance counter stats for './hugepage-off.o 140':
372,114365 task-clock (msec) # 0,991 CPUs utilized
10 context-switches # 0,027 K/sec
0 cpu-migrations # 0,000 K/sec
35.891 page-faults # 0,096 M/sec
1.288.594.148 cycles # 3,463 GHz (48,50%)
1.729.499.101 instructions # 1,34 insn per cycle (61,32%)
162.942.345 branches # 437,882 M/sec (61,31%)
199.318 branch-misses # 0,12% of all branches (62,29%)
762.267.431 L1-dcache-loads # 2048,476 M/sec (63,37%)
2.971.196 L1-dcache-load-misses # 0,39% of all L1-dcache hits (64,40%)
95.096 LLC-loads # 0,256 M/sec (50,60%)
36.332 LLC-load-misses # 38,21% of all LL-cache hits (49,53%)
0,375599296 seconds time elapsed
# perf stat -d ./hugepage-on.o 140
Memoria alocada
Memoria desalocada
Performance counter stats for './hugepage-on.o 140':
1,622347 task-clock (msec) # 0,647 CPUs utilized
0 context-switches # 0,000 K/sec
0 cpu-migrations # 0,000 K/sec
53 page-faults # 0,033 M/sec
902.901 cycles # 0,557 GHz (29,37%)
732.331 instructions # 0,81 insn per cycle
143.505 branches # 88,455 M/sec
7.045 branch-misses # 4,91% of all branches
200.320 L1-dcache-loads # 123,475 M/sec
16.217 L1-dcache-load-misses # 8,10% of all L1-dcache hits
LLC-loads (0,00%)
LLC-load-misses (0,00%)
0,002507633 seconds time elapsed
A saída do perf-stat mostra que a execução da versão sem HugePages gastou um número muito maior de ciclos de CPU do que a versão com HugePages, ~1 bilhão de ciclos e 900 mil ciclos respectivamente. Outro ponto que podemos ver, é que o número de “page faults” também é muito maior na versão sem HugePages, 35mil page faults vs 53 page faults na versão com HugePages.
THP – Transparent Huge Pages
O THP permite o uso de HugePages de maneira transparente para as aplicações que utilizam memória anônima (mmap), tmpfs ou memória compartilhada. Quando habilitado, a cada minor page fault o kernel tentará alocar uma HugePage de 2MB, porém, devido ao THP não possuir uma reserva de memória como o Hugetlbpage, não existem garantias de que essa alocação terá sucesso. Quando essa tentativa de formar uma HugePage falha devido a fragmentação, ocorre o fallback para tamanho de página normal, de forma transparente para a aplicação e assim que páginas forem liberadas e a desfragmentação ocorrer, o khugepaged move as páginas comuns de maneira automática para formar uma HugePage.
Vale salientar que, com o passar do tempo, mesmo alocações de pequenos blocos de memória, com tamanho inferior a uma HugePage podem ser movidos para áreas contíguas de memória física e serem transformadas em HugePages pelo khugepaged.
O khugepaged é uma thread do kernel que é executado a cada X milisegundos e varre uma quantidade Y de páginas, cujo objetivo é unir páginas simples e transformá-las em HugePages. Opcionalmente ele também pode realizar a desfragmentação da meméria. Sua configuração é realizada através dos seguintes arquivos:
- /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs: define o intervalo entre as rodadas do khugepaged (X)
- /sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan: define o número máximo de páginas a serem varridas por rodada (Y)
- /sys/kernel/mm/transparent_hugepage/khugepaged/defrag: permite habilitar ou desabilitar a desfragmentação pelo khugepaged
Um efeito colateral do uso do THP é um possível disperdício de memória, pois caso as aplicações realizem alocações de memória onde só se utilizam alguns bytes efetivamente, a alocação física de memória será de 2MB ao invés de apenas 4KB. Outro efeito colateral é relacionado a um possível uso excessivo de CPU para desfragmentação dependendo do workload da aplicação. Normalmente bancos de dados acabam sofrendo destes efeitos colaterais e não recomendam o uso do THP.
Por esses motivos o kernel permite que o THP seja desativado completamente ou ser ativado somente quando indicado pela aplicação, através da chamada madvise(MADV_HUGEPAGE).
Essa configuração é realizada através do /sys/kernel/mm/transparent_hugepage/enabled e pode conter os seguintes valores:
- always – O THP estará sempre habilitado, toda alocação de memória anônima de qualquer processo estará sujeita a utilização de HugePages
- madvise – O THP estará habilitado, porém, somente as alocações de processos que efetuarem a chamada madvise(MADV_HUGEPAGE) estarão sujeitas a se tornar uma HugePage. Esta é a opção padrão das versões atuais do kernel
- never – O THP estará completamente desabilitado
Outro ponto que podemos ajustar, é o comportamento da desfragmentação da memória, através do /sys/kernel/mm/transparent_hugepage/defrag. Nele indicamos como o kernel deve proceder quando o ocorre uma tentativa de alocação de uma HugePage onde não existe memória contígua suficiente para formar uma HugePage e que permite o seguintes comportamentos:
- Always: o kernel irá aguardar a tentativa de “reivindicar” e compactar memória para dar espaço para uma HugePage
- Defer: o kernel opta pela alocação de uma página simples e em seguida acorda o Kswapd e o Kcompactd para desfragmentar memória. Assim que houver espaço disponível o khugepaged irpa mover as páginas simples para uma HugePage
- Defer+MAdvise: terá o mesmo comportamento do “always” para chamadas com “madvise” e para o restante utilizara o “defer”
- Madvise: somente chamadas com “madvise” vão reivindicar memória para HugePages, que utilizará o mesmo comportamento do “always”
- Never: nunca tenta realizar o defrag
Lembrando que estes parâmetros não são do proc, então para persistir após uma reinicialização é necessário alterá-los nos parâmetros do kernel no momento do boot.
Através do /proc podemos monitorar o uso geral do THP através do /proc/meminfo nos campos “AnonHugePages” e “ShmemHugePages”, onde podemos visualizar a quantidade total de memória utilizada para memória anônima e para memória compartilhada respectivamente. Alem do meminfo também temos o /proc/vmstat onde podemos visualizar em detalhes o comportamento do THP através dos seguintes campos:
- thp_fault_alloc – É um contador que é incrementado toda vez que uma HugePage é alocada com sucesso
- thp_collapse_alloc – É um contador que é incrementado toda vez que o khugepaged identifica uma área de memória que pode ser transformada em uma HugePage
- thp_fault_fallback – É um contador que é incrementado toda vez que a alocação de uma HugePage falha e o kernel utiliza uma página simples.
- thp_split_page – É um contador que é incrementado toda vez que uma HugePage é divida em páginas comuns e acontece com páginas antigas por conta de reivindicação de memória.
- compact_stall – É um contador que é incrementado toda vez que um processo aguarda a compactação para liberação de uma HugePage
- compact_pages_moved – É um contador que é incrementado toda vez que uma página precisa ser movida de uma região de memória para compactar a memória e liberar espaço para uma HugePage. Observar esse item é importante, pois um grande aumento neste item indica que está ocorrendo um grande número de operações de cópia de conteúdo entre regiões de memória, comportamento que pode impactar no desempenho e minimizar o benefício do uso do THP.
Para realizar testes em cima do THP desenvolvemos o thp-test.c onde alocamos uma área de memória anônima baseada no primeiro parâmetro passado na execução, e em seguida preenchemos esta área de memória com o caracter “A” através de acessos randômicos seguidos de acessos sequenciais de 8MB.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
unsigned long i,n,total_size,offset;
if(argc < 2){
printf("Usage: <Size allocation (megabytes)>");
}
int megabytes = atoi(argv[1]);
total_size = 1024*1024* (unsigned long) megabytes;
ptr=mmap(0,1024*1024* (unsigned long) megabytes,PROT_WRITE|PROT_READ,MAP_PRIVATE|MAP_ANONYMOUS,-1,0);
if(ptr==MAP_FAILED){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
tmp_ptr=ptr;
for(i=0;i+1< (unsigned long) megabytes; i++){
offset=((unsigned long) random()) % (total_size + 1);
for(n=0;n<8388608;n++){
if(tmp_ptr+offset+n >= (tmp_ptr+total_size)-1 ){
break;
}
strcpy(tmp_ptr+offset+n,"a");
}
}
printf("Memoria alocada\n");
munmap(ptr,1024*1024* (unsigned long) megabytes);
printf("Memoria desalocada\n");
return 0;
}
$ gcc thp-test.c thp-test.o
$ sudo su
# cat /proc/meminfo | egrep 'AnonHugePages|ShmemHugePages'
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
# cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
# perf stat -e dTLB-loads,dTLB-load-misses,dTLB-stores,dTLB-store-misses -e cycles ./thp-test.o 200
Memoria alocada
Memoria desalocada
Performance counter stats for './thp-test.o 200':
16.534.503.996 dTLB-loads
89.952 dTLB-load-misses # 0,00% of all dTLB cache hits
3.324.761.221 dTLB-stores
664.147 dTLB-store-misses
17.053.408.632 cycles
4,897094809 seconds time elapsed
# cat /proc/vmstat | egrep 'thp'
thp_fault_alloc 0
thp_fault_fallback 0
thp_collapse_alloc 0
thp_collapse_alloc_failed 0
thp_file_alloc 0
thp_file_mapped 0
thp_split_page 0
thp_split_page_failed 0
thp_deferred_split_page 0
thp_split_pmd 0
thp_split_pud 0
thp_zero_page_alloc 0
thp_zero_page_alloc_failed 0
thp_swpout 0
thp_swpout_fallback 0
# echo 'always' > /sys/kernel/mm/transparent_hugepage/enabled
# perf stat -e dTLB-loads,dTLB-load-misses,dTLB-stores,dTLB-store-misses -e cycles ./thp-test.o 200
Memoria alocada
Memoria desalocada
Performance counter stats for './thp-test.o 200':
16.507.602.661 dTLB-loads
31.461 dTLB-load-misses # 0,00% of all dTLB cache hits
3.308.502.249 dTLB-stores
223.286 dTLB-store-misses
16.816.673.023 cycles
4,834108739 seconds time elapsed
# cat /proc/vmstat | egrep 'thp'
thp_fault_alloc 103
thp_fault_fallback 0
thp_collapse_alloc 0
thp_collapse_alloc_failed 0
thp_file_alloc 0
thp_file_mapped 0
thp_split_page 0
thp_split_page_failed 0
thp_deferred_split_page 103
thp_split_pmd 0
thp_split_pud 0
thp_zero_page_alloc 0
thp_zero_page_alloc_failed 0
thp_swpout 0
thp_swpout_fallback 0
Na execução acima podemos ver que:
- Não existia uso de THP no momento, o que pode ser visto através do /proc/meminfo
- No /sys/kernel/mm/transparent_hugepage/enabled vimos que o THP estava configurado para ser utilizado somente caso a aplicação assim indicasse com o madvise
- Após a primeira execução do thp-test.o vimos no /proc/vmstat que nenhum recurso de THP havia sido usado até então
- Sabendo que nossa aplicação não chama o madvise, alteramos o /sys/kernel/mm/transparent_hugepage/enabled para always
- Executamos nossa aplicação novamente, o que resultou no uso de aproximadamente 103 HugePages, conforme observado no /proc/vmstat
Apesar do tempo de execução dos dois testes serem muito próximos, o perf stat mostra claramente o melhor aproveitamento do TLB na execução com THP, através de um número muito menor “dTLB-load-misses” e “dTLB-store-misses” assim como na quantidade de ciclos de CPU utilizados.
Próximos passos
No próximo post iremos abordar mais algumas funcionalidades da memória virtual, como memória compartilhada e page cache etc.
Até lá!
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também
Guia passo a passo para instalar o Ceph em ambiente mononode
Houve um tempo atrás que tive que criar um Storage para um ambiente de Openstack usando o FreeNAS. Devo dizer que não encontrei uma única documentação que explicasse como seria

Monitoramento de Banco de Dados com o PMM da Percona
O que é o PMM? O Percona Monitoring and Management (PMM) é uma solução open source para observabilidade, monitoramento e gerenciamento de bancos de dados, com suporte a MySQL/MariaDB, PostgreSQL

Guia Completo: Como Utilizar o Vagrant para Gerenciar Máquinas Virtuais
Introdução Vagrant é uma ferramenta para criação e gerenciamento de máquinas virtuais de forma automatizada. Ele é usado principalmente para fins de desenvolvimento, permitindo que seja criado um ambiente de






