
Migração eficiente de instância MySQL para AWS RDS: Guia passo a passo
O desafio
Recentemente recebemos um desafio de migrarmos uma instância MySQL com 1.7TB para a AWS RDS.
A migração deveria obedecer os seguintes requisitos:
- Migrar integralmente todas as databases;
- A Migração deveria ocorrer com o mínimo de downtime (No máximo 1 hora);
- A instância estava no MySQL 5.5 (Sem suporte)
Possíveis estratégias
- Dump / Restore
- AWS Database Migration Service (DMS)
- Xtrabackup / Restore S3
Falhas iniciais
- Começamos o projeto com um dump restore, que após 6h de execução, foi estimado em 7 dias para conclusão, inviabilizando o projeto;
- O DMS levou 48 horas para sincronizar, já sincronizando também com as alterações de binlog;
- Porém o mesmo não levou os índices nem as opções de auto-incremments nem as Foreing Keys (FKs);
- Os ajustes levariam mais de 7 dias pelas estimativas;
- Realizamos então um novo DMS, já com o dump de estrutura pronto. Porém as estimativas também estavam em mais de 7 dias, inviabilizando o projeto;
- Por fim, sobrou então o xtrabackup, que inicialmente foi ignorado por causa da versão, como estava na 5.5, era incompatível com o RDS.
Utilizamos então uma instância replicada utilizada pelo cliente como backup;
Realizamos a migração para a 5.6 e posteriormente para a 5.7, viabilizando a estratégia;
Os passos serão vistos a seguir
Migrando uma instância MYSQL para o RDS de forma simples
Para migrar a instância, você só vai precisar de 3 coisas:
- Um bucket S3 para armazenar o seu backup (Pode ser até um existente);
- Um backup criado no seu servidor on-premises com XtraBackup;
- Uma role IAM com permissão de acesso ao bucket e permissão para criar o RDS (Pode ser uma role existente);
Limitações
Este processo possui algumas limitações que podem inviabilizar a estratégia:
- O Bucket S3 tem que estar na mesma conta e região do RDS a ser criado;
- O RDS tem que ser novo (Vai ser criado com o comando de restore, não pode ser um existente);
- A partir de fevereiro de 2022, a AWS só permitiu o restore para uma instância na versão maior ou igual a 5.7.
- A nova instância tem que estar na mesma versão majoritária do MySQL, porém é possível fazer um upgrade após a criação da instância.
- Também não é possível restaurar de uma versão minitória menor no RDS, por exemplo, da versão 5.7.36 para 5.7.15
- Porém, é possível restaurar de uma versão minitória no on-premises para uma versão minitória superior, por exemplo da 5.7.15 para a 5.7.36
- O RDS tem um limite de 5TB por arquivo (Cada arquivo, e não o backup completo) e 1 milhão de arquivos no bucket. Caso sua instância atinja alguma destas limitações, você pode realizar a compressão com Gzip (.gz), tar (.tar.gz), ou Percona xbstream (.xbstream);
- Funções e procedures não são importadas automaticamente. Isso ocorre porque o RDS não permite superusuários. Basta fazer um dump das suas procedures e funções e importar no RDS sem a opção *DEFINER*;
- Apesar do técnica também restaurar usuários, os mesmos não são garantidos pela AWS. Então recomendamos que seja feito um dump de privilégios. O mesmo pode ser realizado com a ferramenta da Percona pt-show-grants;
- O parâmetro innodb_data_file_path deve estar configurado de forma única, com o valor padrão: ibdata1:12M:autoextend. No nosso desafio, a instância detinha 3 datafiles. Após a geração do backup, concatenamos os 3 em um só, pela ordem que foram gerados, e alteramos a configuração para o valor default.
- O tamanho máximo da base a ser restaurada depende do tamanho máximo do disco menos o tamanho do backup. Então por exemplo, se o tamanho máximo da database for 64 TB o o tamanho do backup for de 30 TB, o tamanho máximo da base restaurada vai ser de 34 TB;
Passo 1 – Criar o bucket S3
O RDS final deve estar na mesma região do bucket:

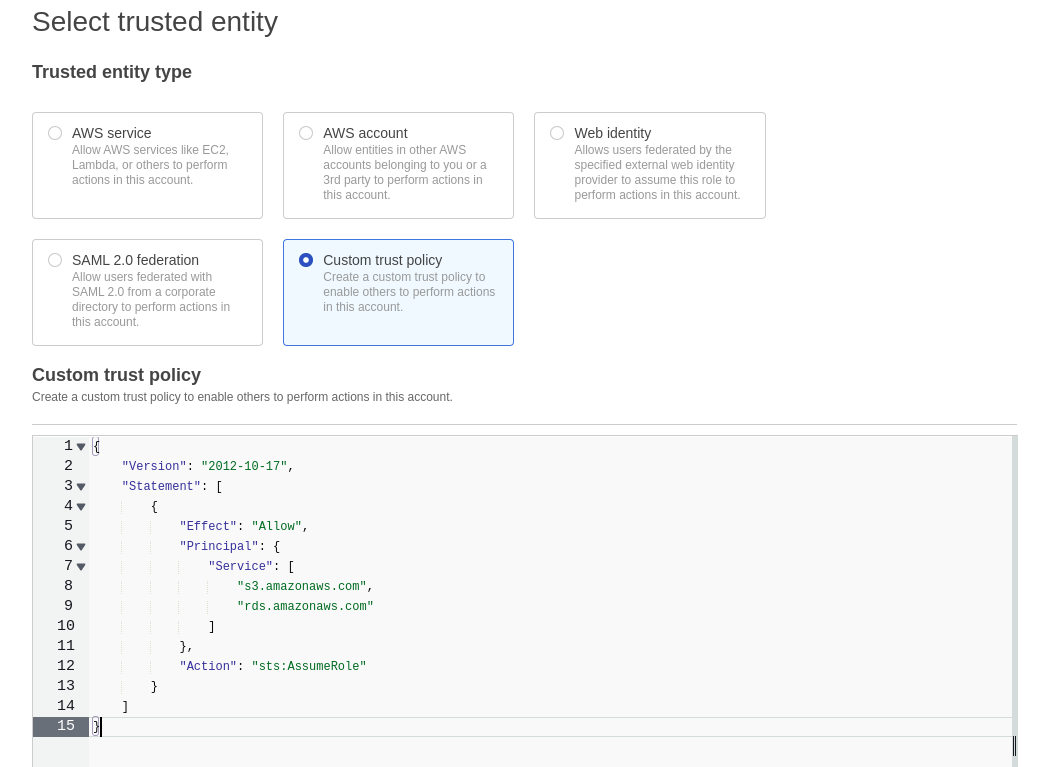
Passo 2 – Criar a Role IAM
O segundo passo do processo é criar uma role IAM para realizar o restore da instância.

{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"s3.amazonaws.com",
"rds.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
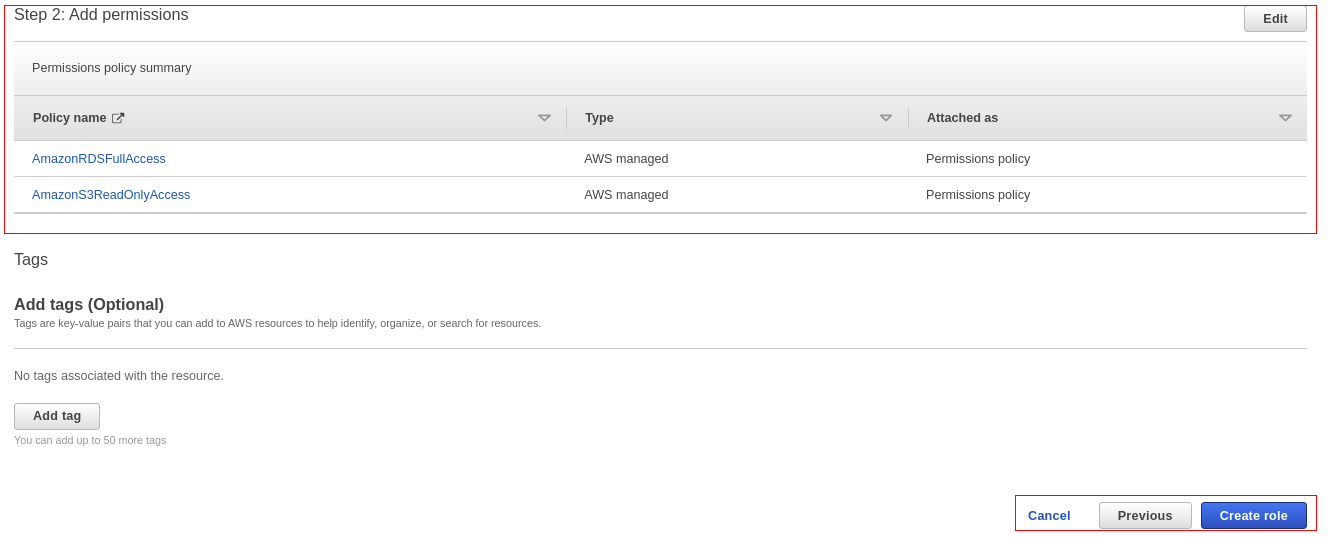
 Na segunda etapa, selecione as permissões:
Na segunda etapa, selecione as permissões:
- AmazonRDSFullAccess
- AmazonS3ReadOnlyAccess
Na terceira e última etapa, digite um nome para a política, confirme as permissões e clique em “Create Role”.
[Atenção!!!]
Esta política criada é o básico para a criação de uma forma simples, e após o procedimento pode ser completamente removida.
Caso seja um requisito de segurança, podem ser acrescidas limitações, para ler apenas o bucket criado e permissão para criação apenas do RDS desejado.
Você pode ver mais sobre políticas da AWS em neste link.
Passo 3 – Gerar o backup
Para gerar o backup não tem muito mistério, pode ser gerado da forma mais simples, conforme documentação da AWS:
xtrabackup --backup --user=<usuario> --password=<senha> --target-dir=</diretorio_backup/>
xtrabackup --backup --user=<myuser> --password=<password> --stream=tar \ --target-dir=</on-premises/s3-restore/backup> | gzip - | split -d --bytes=500MB \ - </on-premises/s3-restore/backup/backup>.tar.gz
Passo 4 – Enviar o backup para o S3
aws s3 sync <diretorio_backup_xtrabackup> s3://<nome_bucket>
aws s3 sync <diretorio_backup_xtrabackup> s3://<nome_bucket>/<diretorio>
Passo 5 – Restaurar o backup do S3

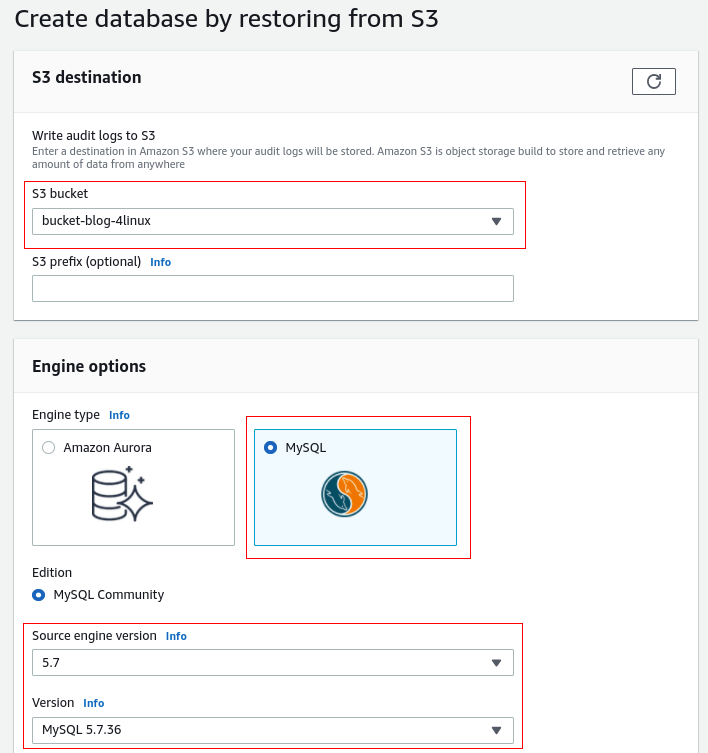
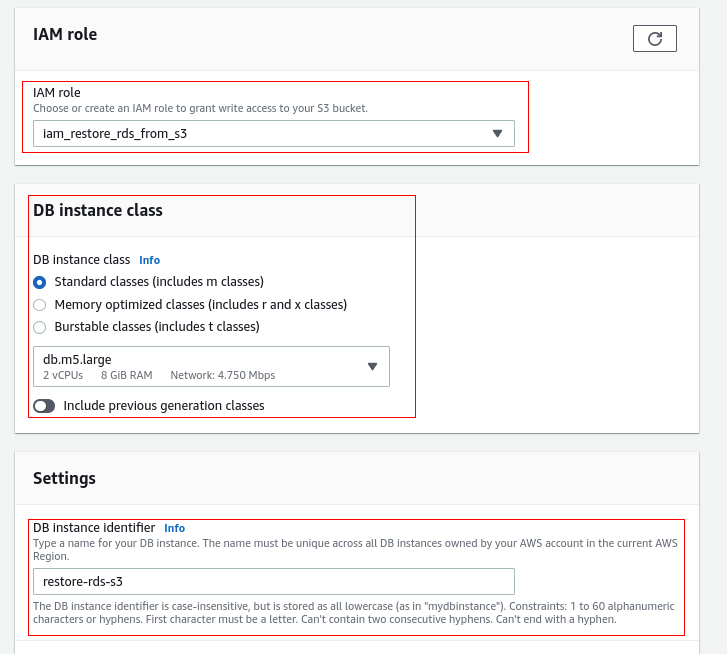
Passo 6 – Validar as procedures, funções e usuários
select * from information_schema.routines where routine_schema not in ('sys');
ou
SHOW CREATE PROCEDURE <database>.<nome_procedure>
SHOW CREATE FUNCTION <database>.<nome_funcao>
Passo 7 – Configurar a instância do RDS como réplica do servidor on-premises
Configurar o apontamento para o master
CALL mysql.rds_set_external_master ('{{ host }}', {{ porta }},'{{ usuario }}', '{{ senha }}', '{{ arquivo de log }}', {{ posicao }}, {{ use_ssl }});Para iniciar a replicação:
CALL mysql.rds_start_replication;
Para parara a replicação:
ALL mysql.rds_stop_replication;
Para consultar a replicação:
SHOW SLAVE STATUS;
Considerações finais
Desta forma, é possível realizar uma migração com o menor tempo de downtime possível, independente do tamanho da base, pois a migração só ocorrerá após a finalização da sincronia do RDS com o master;
Certifique-se de que a réplica irá armazenar binlogs suficiente.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Moodle – Descomplicando a instalação
Caro leitor, nesse artigo vamos tentar descomplicar a instalação do ambiente virtual de aprendizado Moodle para quem está iniciando o uso desta plataforma. Para isso, utilizaremos o Vagrant para provisionar

Entenda o Pool de Conexões no PostgreSQL e Melhore a Performance do seu Banco de Dados
Você que trabalha com o PostgreSQL há um determinado tempo já deve ter visto o seguinte erro “FATAL: sorry, too many clients already”, ou então visto o parâmetro max_connections e

Organize seus objetos de banco de dados com schemas PostgreSQL no Django
Que tal se você pudesse organizar seus objetos de bancos de dados (suas tabelas, views, functions, procedures etc.) em namespaces de acordo com suas respectivas funções no sistema? Neste artigo





