
Conexão com Cluster Kafka Hospedado em Kubernetes: Guia Completo
Nesse artigo vamos discutir questões relacionadas a como disponibilizar um cluster kafka hospedado em um k8s para aplicações que estejam hospedadas fora do cluster kubernetes. Não vamos tratar da instalação de um cluster kafka propriamente dito nem de configurações específicas ou instalação do kubernetes. O objetivo principal é discutir questões relacionadas a conexão ao cluster kafka quando ele está hospedado em um ambiente k8s. Partimos do principio que o leitor tenha entendimento básico do kubernetes: pods, kubectl, services, etc.
O kafka foi desenhado para ser um sistema distruído e com alta disponibilidade que poderia ser executado em equipametos de baixo custo. A arquitetura de brokers, topicos, partições e réplicas, que fornece alta disponibilide e paralelismo, dispensa a necessidade de um elemento que gerencie o acesso distribuído ao cluster e tem como premissa que os clientes possam ter acesso direto a todos os brokers. Essa necessidade de acesso direto é uma das preocupações que se precisa ter quando estamos executando o cluster em ambientes
O que é o Kafka
O Apache Kafka é um sistema de mensagens usado para criar aplicações de streaming, ou seja, aquelas com fluxo de dados contínuo, baseado em em um sistema de mensagems do tipo publish/subscribe. A arquitetura do kafka (baseado em brokers, tópicos, partições e réplicas) torna o sistema altamente escalável, distribuído e tolerante a falhas, ideal para o tratamento de grandes volumes de dados em stream.
Um sistema de mensagens (também chamado de mensageria) permite desacoplar a geração dos dados do seu processamento de forma assíncrona, assim, uma aplicação pode continuar funcionando sem esperar a outra terminar seu processamento a utilização de sistemas de mensageria tem o potencial por exemplo de diminuir a necessidade de leitura, por exemplo, do banco de dados.
Alguns conceitos básicos que são importantes quando falamos de kafka são:
- Broker: o servidor kafka, ou instância do kafka;
- Mensagem: dado ou informação que deve ser trafegada.
- Tópicos: servem para categorizar e armazenar as mensagens produzidas.
- Producer: é quem produz uma mensagem para um tópico.
- Consumer: é quem consome as mensagens produzidas em um tópico.
Juntamente com os conceitos de brokers e tópicos, dois outros conceitos são importantes para entender a conexão dos clientes (producer/consumer) ao cluster kafka, são eles particionameto e replicação.
Partição
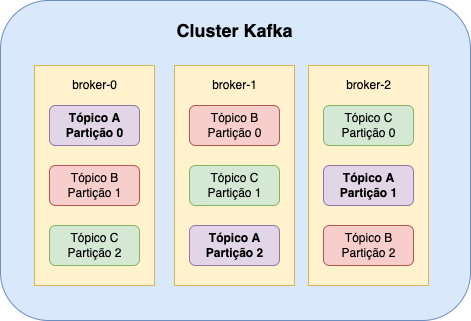
Tópicos são divididos em partições que são a forma como o kafka fornece paralelismo de leitura e escrita nos tópicos, cada produtor/consumidor pode escrever/ler mensagens em diversas partições de um tópico ao mesmo tempo. Enquanto o tópico é um conceito lógico no Kafka, uma partição é a menor unidade de armazenamento que contém um subconjunto de registros pertencentes a um tópico. Além disso, em um ambiente com multiplos brokers as partições de um mesmo tópico são distribuídas entre os brokers.
 Replicas
Replicas
Enquanto o particionamento fornece paralelismo e escalabilidade para leituras e escritas, as réplicas adicionam disponibilidade. A replicação é ativada a nível de partição, ou seja, quando habilitamos a replicação para um tópico, definimos que o kafka mantenha cópias dos tópicos replicados em mais de um worker.
A funcinalidade de replição trás embutida nele mais dois conceitos: Leader e In Sync Replica (ISR), as partições “leader” são as partições de leitura e escrita, é delas que consumimos e produzimos as mensagens, enquanto as partições in sync são partições de “stand by”, atualizadas a cada ação da leader.
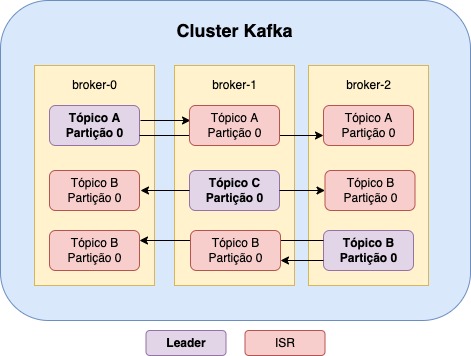
Vamos supor um caso em que temos o tópico A com a partição 0, com sua leader no broker-0 e uma ISR no broker-1, caso o o broker-0 caia, o kafka vai procurar imediatamente pela in sync que esteja mais atualizada em relação a leader e a promove a leader, garantindo assim a disponibilidade do cluster.
O comando abaixo cria um tópico com 3 partições e duas réplicas, ou seja, vamos ter a partição leader e duas in sync replicas, para cada partição:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 2 --partitions 3 --topic pedido
Só é possível o uso de réplicas quanto o cluster tem 2 ou mais brokers e o número máximo de réplicas é a mesma quantidade de brokers que temos no cluster.
Como funciona a conexão ao cluster Kafka
O Kafka é um sistema distribuído. Os dados são lidos e gravados na replica Leader de uma determinada partição, que pode estar em qualquer um dos brokers em um cluster. Quando um cliente (produtor/consumidor) for iniciado, ele solicitará metadados sobre qual broker é o líder de uma partição – e pode fazer isso para qualquer broker. Os metadados retornados incluirão os “endpoints” disponíveis para o broker Leader para essa partição e o cliente usará esses “endpoints” para se conectar ao broker para ler/gravar dados conforme necessário.
Um cliente também pode estar consumindo ou produzindo de mais de uma partição e/ou tópico ao mesmo tempo, de forma paralela, que de um modo geral estarão distribuídos entre os brokers do cluster. Como já foi dito se o broker que armazena a partição leader ficar indisponível por algum motivo o cliente precisa estar apto a consumir/produzir no seu in sync replica de forma praticamente imediata. Para entender o acesso a um cluster kafka é importante entender os conceitos relacionados a bootstrap-servers, listeners, e advertised_listeners.
bootstrap-servers
Um cluster kafka pode ter centenas ou mesmo milhares de brokers. Como dizer aos clientes aos quais se conectar? Especificar todos os milhares de brokers kafka na configuração dos clientes seria problemático e a lista seria muito longa. Em vez disso, o que podemos fazer é escolher de dois a três brokers e considerá-los como bootstrap-servers onde um cliente se conecta inicialmente para obter a lista de todos os brokers do cluster, além de outros metadados relacionados a tópicos e partições. Em resumo, o bootstrap-servers é um parâmtero configurado no cliente para indicar qual servidor ele vai usar para buscar as informações sobre o cluster kafka no momento da criação da conexão com o cluster.
É importante reforçar que os clientes (produtores ou consumidores) fazem uso de todos os servidores, independentemente de quais servidores são especificados em bootstrap.servers.
listeners X advertised.listeners
Vamos falar um pouco agora sobre dois parâmetros importantes na configuração de conexão do cluster kafka que são listeners e advertised.listeners presentes no kafka/server.properties.
O parâmetro listeners é uma lista de listeners separada por vírgulas, são o host/ip e a porta à qual o Kafka se liga para escutar por conexões. Em outras palavras, é o que o broker usará para criar soquetes de servidor. Para redes mais complexas, pode ser um endereço IP associado a uma determinada interface de rede em uma máquina. O padrão é 0.0.0.0, o que significa escutar em todas as interfaces.
Já o parâmetro advertised.listeners é uma lista separada por vírgulas de listeneres com seu host/ip e porta. Esses são as informações que são retornados aos clientes quando se conectam a um broker no contexto /bootstrap.
Abixo um exemplo de configuração do listeners e advertised.listeners:
# grep listeners /etc/kafka/server.properties.broker-0 | grep -v ^# listeners=PLAINTEXT://:9092,OUTSIDE://:9094 advertised.listeners=PLAINTEXT://:broker-0:9092,CONNECTIONS_FROM_HOST://:30221 advertised.listeners=PLAINTEXT://:9092,OUTSIDE://192.168.56.71:32400
Na configuração acima os brokers irão abrir sockets escutando as portas 9092 e 9094. Perceba que temos duas linhas advertised e nelas os advertised.listeneres CONNECTIONS_FROM_HOST e OUTSIDE referenciam portas que não são efetivamente escutadas pelos brokers, iremos entender o porque disso quando estivermos falando da configuração do k8s.
Cada listener, quando recebe uma conexão em seu contexto /bootstrap, informará de volta para o cliente o endereço no qual pode ser alcançado. O endereço no qual você alcança um broker depende da rede usada. Ao se conectar a um broker, o listener que será retornado ao cliente será o listener ao qual você se conectou (com base na porta). No caso do nosso exemplo, conexões dentro do k8s serão feitas utilizando a porta 9092 e conexões externas ao k8s devem utilizar a porta 9094.
Podemos usar o aplicativo kafkacat para fazer algumas manipulações no cluster kafka via linha de comando. Vamos utilizá-lo para validar os retornos que o cliente recebe quando conectando a diferentes portas do listener. Para os exemplos abaixo vamos utilizar a opção port-forward para conectar diretamente aos pods dos workers
$ kubectl port-forward -n kafka-cluster broker-0 9092:9092 Forwarding from 127.0.0.1:9092 -> 9092 $ kafkacat -L -b localhost:9092 Handling connection for 9092 Metadata for all topics (from broker -1: localhost:9092/bootstrap): 3 brokers: broker 0 at broker-0.kafka.kafka-cluster.svc.cluster.local:9092 broker 2 at broker-2.kafka.kafka-cluster.svc.cluster.local:9092 broker 1 at broker-1.kafka.kafka-cluster.svc.cluster.local:9092 0 topics:
O parâmetro ‘-b’ do kafkacat indica qual endereço deve ser utilizado para bootstrap, perceba que ao realizar o port-forward para a porta 9092 recebmos como retornos os endereços internos do cluster kubernetes. Após realizar a consulta acima e obter os endereços dos brokers (broker-0.kafka.kafka-cluster.svc.cluster.local:9092, broker-2.kafka.kafka-cluster.svc.cluster.local:9092, broker-1.kafka.kafka-cluster.svc.cluster.local:9092) a aplicação iria tentar se conectar diretamente aos endereços dos brokers e se estiver rodando fora do cluster kubernetes ela não terá acesso aos endereços retornados. Vamos fazer a mesma verificação agora para a porta 9094:
$ kubectl port-forward -n kafka-cluster broker-0 9094:9094 Forwarding from 127.0.0.1:9094 -> 9094 $ kafkacat -L -b localhost:9094 Handling connection for 9094 Metadata for all topics (from broker -1: localhost:9094/bootstrap): 3 brokers: broker 0 at 192.168.56.71:32400 broker 2 at 192.168.56.72:32402 broker 1 at 192.168.56.72:32401 0 topics:
Perceba que, como havíamos dito, o retorno para o cliente de quais brokers devem ser utilizados para se conectar irá mudar a depender da porta em que o broker recebe a solicitação de bootstrap.
Consumindo o cluster Kafka de fora do k8s
A maneira mais comum de expor algum aplicativo no k8s é usando um service. Os serviços do Kubernetes funcionam como balanceadores de carga de camada 4. Eles fornecem um endereço DNS estável, onde os clientes podem se conectar. E eles apenas encaminham as conexões para um dos pods que estão rodando o serviço.
Isso funciona razoavelmente bem com a maioria dos aplicativos stateless que desejam apenas se conectar aleatoriamente a um dos backends por trás do serviço. Mas pode ficar muito mais complicado se seu aplicativo exigir algum tipo de aderência devido a algum estado associado a um pod específico, como por exemplo uma aderência de dados – quando um cliente precisa se conectar a um pod específico porque este contém alguns dados específicos.
Este é o caso de Kafka. Um serviço Kubernetes pode ser usado apenas para a conexão inicial – ele levará o cliente a um dos brokers dentro do cluster onde ele poderá obter os metadados. Mas as conexões subsequentes não podem ser feitas por meio desse serviço porque ele encaminharia a conexão aleatoriamente para um dos brokers do cluster em vez de levá-la a um broker específico.
Vamos lidar com essa questão usando a opção advertised.listeners na configuração do broker de forma que permita que os clientes se conectem diretamente ao broker. Em conjunto com o uso de serviços do tipo NodePort no kubernetes.
Conectando de dentro do mesmo cluster k8s
Conectar ao cluster kafka para clientes rodando dentro do mesmo cluster Kubernetes é bem simples. Cada pod tem seu próprio endereço IP, que outros aplicativos podem usar para se conectar diretamente a ele. Isso normalmente não é usado por aplicativos Kubernetes. Uma das razões é que o Kubernetes não oferece nenhuma maneira simples de descobrir esses endereços IP. Em vez disso, o Kubernetes usa os serviços com seus nomes DNS estáveis como o principal mecanismo de descoberta e atribui endereços de DNS internos aos pods.
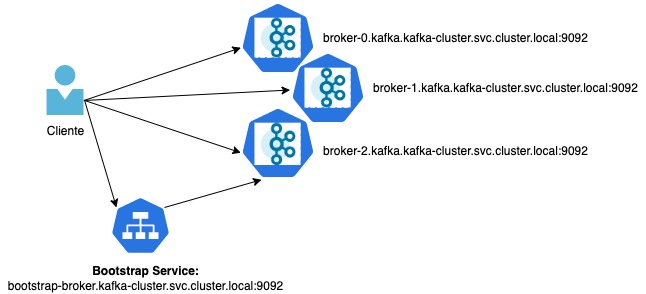
Nesse cenário o fluxo de conexão é:
- A conexão inicial é feita usando um serviço regular do Kubernetes para obter os metadados.
- As conexões subsequentes são abertas usando os nomes DNS fornecidos aos pods pelo kubernetes e configurados no parâmetro advertised.listeners de cada broker.
O resultado é exatamente o que vimos acima, quando fizemos uma conexão com a porta 9092, que foi a definida para ser utilizada em conexões internas, e recebemos como retorno a lista de endereços DNS internos dos brokers.
Conectando de fora do cluster k8s
O acesso ao cluster kafka fica um pouco mais complicado quando tentamos acessar o kafka de fora do cluster k8s.
Embora existam algumas ferramentas que permitiam “conectar” rede Kubernetes com a rede LAN fora do Kubernetes, a maioria dos clusters Kubernetes é executada em sua própria rede, separada do mundo externo. Isso significa que endereços IP de pod ou nomes DNS não podem ser resolvidos para nenhum cliente executando fora do cluster.
Exatamente daí, vem a necessidade de usarmos um listener Kafka separado para acesso de dentro e de fora do cluster, porque os endereços anunciados precisarão ser diferentes.
No nosso caso, resolvemos essa questão com o uso de serviços do tipo NodePort. Quando esse serviço é criado, o Kubernetes aloca uma porta em todos os nós do cluster Kubernetes e garante que todo o tráfego para essa porta seja roteado para o serviço e, eventualmente, para os pods por trás desse serviço.
Não importa em qual nó seu pod está sendo executado. As portas do nó estarão abertas em todos os nós e o tráfego sempre chegará ao seu pod. Portanto, seus clientes podem se conectar ao NodePort em qualquer um dos nós e deixar o Kubernetes lidar com o resto.
Expondo o kafka usando NodePort
A primeira coisa que precisamos lidar é como os clientes acessarão os brokers individualmente. A questão é que, como abordado acima, ter um serviço que faça o encaminhamento aletaorio para os brokers do cluster não funcionará com o Kafka pois os clientes precisam ser capazes de alcançar cada um dos brokers diretamente.
Para tratar essa questão vamos criar services adicionais – um para cada broker Kafka. Portanto, em um cluster Kafka com N brokers, teremos N+1 serviços NodePort:
- Um que pode ser usado pelos clientes Kafka como serviço de bootstrap para a conexão inicial e para receber os metadados sobre o cluster Kafka.
- Outros N serviços – um para cada broker – para encaminhar diretamente para os brokers.
Cada um desses serviços será atribuído a uma porta de nó diferente, para que o tráfego para os diferentes agentes possa ser diferenciado.
O yaml abaixo mostra um exemplo de criação de um desses serviços:
apiVersion: v1 kind: Service metadata: name: kafka-out-broker-0 namespace: kafka-cluster spec: type: NodePort selector: statefulset.kubernetes.io/pod-name: broker-0 ports: - port: 9094 targetPort: 9094 protocol: TCP nodePort: 32400
Desde o Kubernetes 1.9, cada pod tem um stateful set que é rotulado automaticamente com statefulset.kubernetes.io/pod-name que contém o nome do pod. Usando esse rótulo no seletor de pod dentro da definição de serviço do Kubernetes é que nos permite segmentar apenas os agentes Kafka individuais e não todo o cluster Kafka. Esse é o grande “pulo do gato” da nossa implementação.
O detalhe do serviço após o yaml aplicado no kubernetes:
$ kubectl describe svc -n kafka-cluster kafka-out-broker-0 Name: kafka-out-broker-0 Namespace: kafka-cluster #... Selector: statefulset.kubernetes.io/pod-name=broker-0 #... IP: 10.104.210.239 IPs: 10.104.210.239 Port: <unset> 9094/TCP TargetPort: 9094/TCP NodePort: <unset> 32400/TCP Endpoints: 10.244.1.16:9094 #...
Vamos ver como ficaram todos os serviços:
$ kubectl get svc -n kafka-cluster NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE bootstrap-broker ClusterIP 10.96.173.138 <none> 9092/TCP 24h kafka NodePort 10.111.167.40 <none> 9092:30221/TCP 24h kafka-out-broker-0 NodePort 10.104.210.239 <none> 9094:32400/TCP 24h kafka-out-broker-1 NodePort 10.99.92.187 <none> 9094:32401/TCP 24h kafka-out-broker-2 NodePort 10.102.188.47 <none> 9094:32402/TCP 24h kafka-out-service NodePort 10.105.243.94 <none> 9094:32094/TCP 11s 24h
Agora testando o acesso ao cluster de uma máquina fora da rede sem realizar o port-forward apontando para o serviço ‘kafka-out-service’:
$ kafkacat -L -b 192.168.56.70:32094 Metadata for all topics (from broker -1: 192.168.56.70:32094/bootstrap): 3 brokers: broker 0 at 192.168.56.71:32400 (controller) broker 2 at 192.168.56.72:32402 broker 1 at 192.168.56.72:32401 1 topics: topic "pedido" with 3 partitions: partition 0, leader 2, replicas: 2,0, isrs: 2,0 partition 1, leader 1, replicas: 1,2, isrs: 1,2 partition 2, leader 0, replicas: 0,1, isrs: 0,1
Mas os services NodePort são a infraestrutura que pode rotear o tráfego para os brokers. Ainda precisamos configurar os brokers Kafka para anunciar o endereço correto, para que os clientes usem essa infraestrutura, mostramos isso acima na configuração do advertised.listeners de um dos brokers que tem o endereço do nó onde o pod está sendo executado:
advertised.listeners=PLAINTEXT://:9092,OUTSIDE://192.168.56.71:32400
O ideal é que isso seja configurado no momento em que o pode for iniciado para pegar o ip correto do nó. Essa configuração pode variar a depender da implementação do kafka que você estiver utilizando para realizar o deploy no kubernetes, no nosso caso, foi feita ums substituição via configmap que retorna o ip do nó:
...
OUTSIDE_HOST=$(kubectl get node "$NODE_NAME" -o jsonpath='{.status.addresses[?(@.type=="InternalIP")].address}')
OUTSIDE_PORT=$((32400 + ${KAFKA_BROKER_ID}))
...
É importante destacar que o uso de nodeports services pode ter implicações de segurança, desse modo é importante ter uma atenção especial em relação ao controle de acesso via rede a portas sensíveis (no caso de serviços do tipo NodePort o range é TCP:30000-32767). Certifique-se de que sua rede bloqueie o acesso às portas sensíveis e considere limitar o acesso apenas a redes confiáveis.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
CURSOSCONSULTORIAราคาบอลหมูบิน168สล็อตทดลองเล่นฟรีทดลองสล็อต PGเว็บสล็อต PG
ทดลองเล่นสล็อตสล็อต pgทดลองเล่นสล็อต PGสล็อตเว็บตรงทดลองเล่นสล็อต pg
About author

Você pode gostar também

Curiosidades DeepSeek Liang Wenfeng
DeepSeek e Liang Wenfeng: Curiosidades e o Futuro da IA Por trás da DeepSeek, há uma história fascinante de inovação e ousadia. Neste post, exploramos algumas curiosidades sobre a trajetória

Descubra como a filosofia DevOps pode impulsionar o sucesso do seu negócio
DevOps é fundado na construção de uma cultura de colaboração, visando a entrega de software de maneira mais rápida e confiável. Pode ser compreendido como uma filosofia de gestão, englobando

Como usar o Kustomize no Kubernetes
Olá pessoal, hoje no blog da 4Linux, vamos falar de uma sensacional para Kubernetes chamada Kustomize. Bora lá!! O que é o Kustomize? O Kustomize é uma ferramenta nativa do






