
Conhecendo o Kernel Linux pelo /proc (parte 3) – Mapeamento de memória virtual
Como vimos nos posts anteriores, o Linux trabalha com conceito de memória virtual, ou seja, cada processo tem seu próprio endereçamento virtual totalmente isolados dos outros processos, porém o que não vimos ainda é como esse endereçamento de memória é mantido pelo kernel e como ele é traduzido para os endereços de memória física. Esse entendimento irá facilitar a compreensão de algumas das funcionalidades do Kernel que podemos configurar e monitorar no /proc, por isso iremos dedicar esse post a este assunto.
Como o Kernel mantém o mapeamento de memória ?
O Kernel Linux possui uma estrutura chamada mm_struct->pgd associada a cada processo existente no sistema operacional. É através dessa estrutura que o Kernel mantém o mapeamento dos endereços de memória virtual do processo para um endereço físico em RAM.
Esta estrutura foi implementada utilizando o conceito de tabelas de páginas multinível, mas para facilitar o entendimento vamos começar mostrando como seria uma simples tabela de píginas, suas limitações e como uma estrutura multinível pode solucionar estas limitações.
Como funcionaria o mecanismo de tabela de páginas simples ?
O primeiro conceito a ser esclarecido aqui é o da página, que nada mais é que um bloco contíguo de tamanho fixo de memória, e cada página de memória virtual terá uma página equivalente em RAM. O tamanho da página varia de acordo com a arquitetura (algumas suportam múltiplos tamanhos), no entanto, um valor comum de tamanho nas arquiteturas x86-64 é de 4096 bytes (4kB).
Outro fator importante para implementar um mecanismo de tabelas de páginas, é saber quantos bits a arquitetura fornece para endereçarmos a memória e com isso saber o tamanho da memória virtual de cada processo. Por exemplo, com 16 bits, podemos endereçar até (2^16) 64kB de memória por processo.
Sabendo o total da memória virtual, podemos calcular a quantidade de páginas presente nesta arquitetura, dividindo o total da memória virtual pelo tamanho da página, o que no exemplo anterior seria 64kB/4kB, o que resultaria em aproximadamente 16 páginas por processo.
Sabendo a quantidade de páginas podemos calcular a quantidade de bits necessário para endereçá-las, fazendo o log (número de páginas) na base 2, que no exemplo anterior seria log(16) na base 2, o que resultaria em 4 bits. Desta forma ainda temos 12 bits para realizar o offset e endereçar os 4096 bytes dentro da página.
Com essas informações podemos implementar uma tabela com 16 entradas indexadas pelo número da página as quais apontam para o endereço inicial da pagina física de memória, conforme a imagem abaixo:
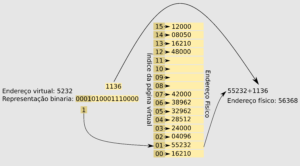
Endereçamento de memória.
Pelo exemplo mostrado na figura acima, podemos ver que qualquer endereço pode ser traduzido calculando o número da páginas somado ao seu offset.
Neste exemplo ainda vemos que existem índices não preenchidos, pois ainda não foram utilizados. Para tratar esses casos, normalmente são incluídas flags aos índices para indicar se esta página já possui mapeamento e também para indicar as permissões de acesso à página.
Desta forma o Kernel apenas precisa armazenar o endereço inicial desta tabela na estrutura do processo, pois a partir desse endereço basta realizar um offset com o índice da página virtual para encontrar o endereço da pagina física. Por isso é necessário que a tabela contenha o índice para as 16 páginas, mesmo se o processo utilize um número reduzido de páginas.
A grande limitação deste tipo de implementação é quando trabalhamos com arquiteturas que permitem endereçar quantidades maiores de memória. Podemos utilizar a arquitetura x86 como exemplo, onde temos 32bits para endereçar memória, o que por sua vez leva cada processo a ter 4GB de memória virtual disponível. Levando em conta o uso de páginas de 4kB temos por volta de 1 milhão de páginas virtuais por processo. Manter tabelas de páginas com essa quantidade de itens por processo seria inviável, por isso, boa parte dos sistemas operacionais modernos utiliza o sistema de páginas multinível.
Como funcionaria uma tabela de páginas multinível ?
Manter a tabela de páginas com milhões de entradas não utilizadas, ou até bilhões em arquiteturas que utilizam 48bits(AMD64), em cada processo, torna essa implementação inviável atualmente. Para resolver esse problema podemos criar uma estrutura onde criamos tabelas com vários níveis, onde começamos com tabelas com blocos maiores de memória virtual, as quais apontam para subtabelas, que ao fim apontam para as páginas físicas.
Tabela multinível.
Na imagem acima temos uma arquitetura 32bits utilizando dois níveis de página de memória, de forma que utilizamos 10 bits para cada nível e os 12 bits restantes para o offset na página. Nesta configuração temos o primeiro nível com 1024 entradas, onde cada entrada aponta para um segundo nível com mais 1024 entradas. A grande vantagem desta implementação é que só precisamos ter o primeiro nível com as 1024 entradas completas na tabela, as subtabelas só precisam existir quando alguma página esta sendo utilizada naquela subtabela.
Como é a implementação no kernel Linux atualmente ?
Para tornar viável o uso de grande quantidades de memória, em arquiteturas 64bits, onde temos 48bits para endereçamento, a implementação atual do Linux utiliza uma estrutura de 4 níveis, as quais são nomeadas de:
- Page Global Directory (PGD)
- Page Upper Directory (PUD)
- Page Middle Directory (PMD)
- Page Table (PT)
Recentemente foi incluído um nível adicional chamado P4D, entre o PGD e o PUD, que utiliza uma extensão da arquitetura x86-64 incluído na plataforma Ice Lake da Intel. Neste modo temos 56bits para endereçamento, o que permite trabalhar com 128 PiB de memória virtual.
Como dito anteriormente, o kernel mantem uma estrutura de memória (mm_struc) para cada processo existente, e é nesta estrutura que temos o apontamento para a PGD (mm_struct->pgd), ou seja, é através dela que o kernel mantém o mapeamento de memória virtual de cada processo e é através dela que podemos resolver os endereços físicos de memória de um determinado processo.
Para ilustrar melhor como isso funciona criamos um pequeno módulo de kernel que nos permite resolver “manualmente” um endereço virtual de um determinado processo e ver seu conteúdo (disponível em https://github.com/wfelipew/kernel-mem-demo).
mod_pagedemo.c:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/debugfs.h>
#include <linux/proc_fs.h>
#include <linux/sysctl.h>
#include <linux/sched.h>
#include <linux/seq_file.h>
#include <linux/mm.h>
#include <asm/pgtable.h>
#include <linux/highmem.h>
unsigned long pagedemo_pid[2];
static struct ctl_table pagedemo_table[] = {
{
.procname = "pagedemo_pid",
.maxlen = 2*sizeof(unsigned long),
.mode = 0644,
.data = &pagedemo_pid,
.proc_handler = &proc_doulongvec_minmax,
},
{}
};
static struct ctl_table_header* pagedemo_header;
static int get_pgd(struct seq_file *m, void *v){
pgd_t *start_pgd;
unsigned long start_phy_addr;
pgd_t *pgd;
p4d_t *p4d;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
unsigned long page_with_flags, page_without_flags, page_offset, phy_address;
char *content;
struct page *page;
/* Try to get task structure by pid */
struct task_struct* task = pid_task(find_vpid((pid_t)pagedemo_pid[0]), PIDTYPE_PID);
/* Check is proccess exists */
if(task == NULL){
seq_printf(m,"Error: PID=%lu - Procces not exists\n",pagedemo_pid[0]);
return 0;
}
/* Get page offset*/
page_offset = pagedemo_pid[1] & ~PAGE_MASK;
/* If process exists get pointer to PGD through the mm member */
start_pgd = task->mm->pgd; /*Get PGD on kernel virtual address*/
start_phy_addr = __pa(start_pgd); /*Translate to phisycal address*/
/*Get PGD entry adress of current virtual address*/
pgd = pgd_offset(task->mm, pagedemo_pid[1]);
if (pgd_none(*pgd)){
seq_printf(m,"Error: VirtualAddress is not mapped in PGD\n");
return 0;
}
/*Get P4D entry address of current virtual address*/
p4d = p4d_offset(pgd,pagedemo_pid[1]);
if (p4d_none(*p4d)){
seq_printf(m,"Error: VirtualAddress is not mapped in P4D\n");
return 0;
}
/*Get PUD entry address of current virtual address*/
pud = pud_offset(p4d,pagedemo_pid[1]);
if (pud_none(*pud)){
seq_printf(m,"Error: VirtualAddress is not mapped in PUD\n");
return 0;_
}
/*Get PMD entry address of current virtual address*/
pmd = pmd_offset(pud,pagedemo_pid[1]);
if (pmd_none(*pmd)){
seq_printf(m,"Error: VirtualAddress is not mapped in PMD\n");
return 0;
}
/*Get PTE entry address of current virtual address*/
pte = pte_offset_kernel(pmd,pagedemo_pid[1]);
if (pte_none(*pte)){
seq_printf(m,"Error: VirtualAddress is not mapped in PTE\n");
return 0;
}
/*Get page struct from PTE pointer*/
page = pte_page(*pte);
/*Map page to kernel virtual adress*/
content= (char *) kmap(page);
/*Remove flags bits from PTE using PAGE_MASK*/
page_with_flags = pte_val(*pte) ;
page_without_flags = pte_val(*pte) & PAGE_MASK ;
/*Sum page offset*/
phy_address = page_without_flags | page_offset;
seq_printf(m,"PID:%lu VirtualAddress:%lu\n PGDStartAddress: 0x%0lx, 0x%0lx \n",pagedemo_pid[0],pagedemo_pid[1],(unsigned long)start_pgd, start_phy_addr);
seq_printf(m,"PGD entry address: %lu\n",pgd_val(*pgd));
seq_printf(m,"P4D entry address: %lu\n",p4d_val(*p4d));
seq_printf(m,"PUD entry address: %lu\n",pud_val(*pud));
seq_printf(m,"PMD entry address: %lu\n",pmd_val(*pmd));
seq_printf(m,"PTE entry address: %lu\n",pte_val(*pte));
seq_printf(m,"\n\nPAGE (with flags) entry address: %lu\n",page_with_flags);
seq_printf(m,"PAGE (without flags) entry address: %lu\n",page_without_flags);
seq_printf(m,"PAGE offset: %lu\n",page_offset);
seq_printf(m,"Virtual Adress:%lu Physical Address:%lu\n",pagedemo_pid[1],phy_address);
/*Show memory content*/
seq_printf(m,"Content :%s\n",content+page_offset);
/*Unmap memory*/
kunmap(page);
return 0;
}
static int pagedemo_open(struct inode *inode,struct file *filed){
return single_open(filed,get_pgd,NULL);
}
static const struct file_operations pgdemo_fops = {
.open = pagedemo_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
static int pagetable_init(void){
printk(KERN_ALERT "Start pagetable demo , choose your PID\n");
printk("PGDIR_SHIFT = %d\n", PGDIR_SHIFT);
pagedemo_header=register_sysctl_table(pagedemo_table);
if (!pagedemo_header) {
printk(KERN_ALERT "Error: Failed to register sample_parent_table\n");
return -EFAULT;
}
proc_create("pagedemo_pid", 0600, NULL, &pgdemo_fops);
return 0;
}
static void pagetable_exit(void){
printk(KERN_INFO "Finish");
unregister_sysctl_table(pagedemo_header);
remove_proc_entry("pagedemo_pid",NULL);
}
module_init(pagetable_init);
module_exit(pagetable_exit);
MODULE_AUTHOR("William Felipe Welter");
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Resolve physical memory address of a given virtual memory proccess of a given proccess and show their content");
Este módulo funciona da seguinte forma:
Após o carregamento, são criados dois arquivos no /proc, o primeiro é o arquivo /proc/sys/pagedemo_pid, onde iremos informar o PID e um endereço de memória de um processo e o arquivo /proc/pagedemo_pid, onde serão exibidos os passos para resolução do endereço físico final e de seu conteúdo.
Toda lógica de resolução esta na função get_pgd() onde inicialmente obtemos a estrutura do processo através do seu PID, de posse desta estrutura obtemos a mm_struct que contém o ponteiro para a PGD (mm_struct->pgd), a partir desse ponto utilizamos uma série de macros e funções do kernel para navegar até encontrar o endereço da página.
Alem de encontrar a página também extraímos o offset do endereço em relação a página e utilizamos as funções kmap/kunmap para mapear esses endereços para a memória virtual do kernel e permitir seu acesso.
Para demonstrar este processo também criamos uma variação dos códigos anteriores que além de preencher uma área de memória com o caracter “a”, também exibe o endereço virtual utilizado.
heapmem-alloc-initialize-position.c:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int hello(int n);
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
ptr=malloc(1024*1024);
if(ptr==NULL){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
tmp_ptr=ptr;
for(int i=0;i<(1024*1024);i++){
strcpy(tmp_ptr,"a");
tmp_ptr+=1;
}
printf("Endereco inicial:%p\n Memoria alocada, pressiona qualquer tecla para desalocar\n",ptr);
getchar();
free(ptr);
printf("Memoria desalocada, pressiona qualquer tecla para encerrar\n");
getchar();
return 0;
}
Em um primeiro terminal vamos executar o heapmem-alloc-initialize-position:
$ gcc heapmem-alloc-initialize-position.c -o heapmem-alloc-initialize-position.o $ ./heapmem-alloc-initialize-position.o Endereco inicial:0x7f7a63ab1010 Memoria alocada, pressiona qualquer tecla para desalocar
Em outro terminal vamos consultar esse endereço (Hexa:0x7f7a63ab1010/Decimal:140163634892816) através do módulo que criamos:
# make # insmod mod_pagedemo.ko # pgrep heapmem-alloc 29312 # echo "29312 140163634892816" > /proc/sys/pagedemo_pid # cat /proc/pagedemo_pid PID:29312 VirtualAddress:140163634892816 PGD entry address: 9223372041989996647 P4D entry address: 9223372041989996647 PUD entry address: 5135224935 PMD entry address: 5135229031 PTE entry address: 9223372050568771687 PAGE (with flags) entry address: 9223372050568771687 PAGE (without flags) entry address: 9223372050568769536 PAGE offset: 16 Virtual Adress:140163634892816 Physical Address:9223372050568769552 Content :aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa....
Na saída acima vemos todos os passos para se obter o endereço o físico, onde inicialmente obtemos o endereço da PGD (9223372041989996647), em seguida do P4D (que neste caso é o mesmo da PGD pois a CPU em questão não possui suporte aos 5 níveis), depois o PUD(5135224935), passando pelo PMD(5135229031) e por fim obtendo o endereço da página (9223372050568771687).
De posse do endereço da página, removemos os bits referentes as flags (9223372050568769536) e somamos com o offset (16) e assim obtemos o endereço físico dessa área de memória (9223372050568769552).
Como a memória virtual é mapeada para a memória física em tempo de execução?
O processo de tradução do endereço de memória memória virtual para um endereço físico é realizado de forma transparente na CPU pelo MMU (Memory Management Unit), que se trata de um hardware localizado entre a CPU e a memória, normalmente faz parte do próprio processador.
O MMU normalmente é apontado para a área de memória que contém a estrutura dos mapeamentos de memória do processo atual, que é mantida pelo Kernel (mm_struct->pgd). Na arquitetura x86 esse apontamento é realizado copiando o apontamento da PGD para o registrador CR3.
O que acontece é que, se tivermos somente o MMU, toda instrução que precisa resolver endereços de memória iria realizar vários acessos a memória e percorrer toda estrutura de mapeamento, da “PGD” a “PTE”, até encontrar a página solicitada. Todo esse processo gera um overhead que seria inaceitável e tornaria inviável a implementação da memória virtual.
Para solucionar esse problema existe o “TLB” (Translate Lookaside Buffer), um buffer acoplado ao MMU, que atua como uma espécie de cache que armazena os mapeamentos de memória, de maneira que, quando a CPU precisa resolver um endereço, a MMU apenas precisar consultar o TLB para resolver o endereço físico.
Como o TLB é populado?
A resposta é: depende… Dependendo da arquitetura ele pode ser gerenciado pelo próprio hardware ou por software, no caso do x86-64 a gerencia do “TLB” é via hardware, ou seja, toda vez que a CPU precisar resolver um endereço a MMU consulta o TLB e caso esse endereço não exista, a MMU irá percorrer toda a estrutura de mapeamento de memória até encontrar o mapeamento necessário e assim popular o TLB com o mapeamento solicitado. No entanto, caso o endereço não seja encontrado, seja por ele não existir, ou por falta de permissão, ou devido a área de memória ter sido movida para o espaço de swap, a MMU irá emitir uma exceção do tipo “page fault” e gerar uma interrupção na CPU, esta exceção deve ser tratada pelo Kernel.
As “page faults” podem ser de dois tipos:
- Minor Page Faults: acontece quando o endereço solicitado ainda não possui um mapeamento para memória física. É o que ocorre quando utilizamos pela primeira vez uma área previamente alocada, seja uma variável ou área alocada via malloc (heap ou área de memória anônima).
- Major Page Faults: acontece quando o endereço solicitado existe, porem a página não se encontra armazenada na memória RAM, de forma que é necessário realizar leitura em disco para restaurar esta página para memória. É o que ocorre quando uma instrução precisa de uma área de memória que se encontra em swap, neste cenário ocorre um Major Fault, o que fará com que o kernel realize a leitura em disco da página em questão e a armazene novamente em memória RAM.
Para exemplificar estes comportamentos criamos o programa page-faults.c, que funciona da seguinte forma:
- Realizamos a alocação de uma área de 1048576 bytes de memória através do malloc()
- Preenchemos essa área com caracteres “A”
- Desalocamos essa área
- Realizamos o mapeamento de um arquivo em memória
- Percorremos todos bytes do arquivo através da memória.
- Vale observar que também utilizamos a função posix_fadvise() com a flag POSIX_FADV_DONTNEED para indicar ao KERNEL que não realize cache do arquivo.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <fcntl.h>
int hello(int n);
int main(int argc, char* argv[]){
char *ptr, *tmp_ptr;
int fd;
struct stat st;
ptr=malloc(1024*1024);
if(ptr==NULL){
printf("Falha ao alocar esta quantidade de memoria\n");
return 1;
}
printf("Memoria alocada. Pressione qualquer tecla para preencher a memoria\n");
getchar();
tmp_ptr=ptr;
for(int i=0;i<(1024*1024);i++){
strcpy(tmp_ptr,"a");
tmp_ptr+=1;
}
printf("Memoria preenchida. Pressione qualquer tecla para desalocar\n");
getchar();
free(ptr);
printf("Pressione qualquer tecla mapear o arquivo %s em memoria\n",argv[1]);
getchar();
fd = open(argv[1],O_RDONLY);
stat(argv[1],&st);
posix_fadvise(fd, 0, st.st_size, POSIX_FADV_DONTNEED);
ptr=mmap(NULL,st.st_size,PROT_READ,MAP_SHARED,fd,0);
close(fd);
if( ptr == MAP_FAILED ){
printf("Falha ao realizar o mapeamento\n");
return 1;
}
printf("Arquivo mapeado com sucesso. Pressione qualquer tecla para percorrer os bytes do arquivo\n");
getchar();
int total=0;
for( int count=0; count < st.st_size; count++ ){
total+= ptr[count];
}
printf("Pressione qualquer tecla desfazer o mapeamento\n");
getchar();
munmap(ptr,0);
return 0;
}
As estatísticas de minor e major faults podem ser consultadas através do /proc/[pid]/stat nas colunas 10 e 12 respectivamente, as quais iremos consultar durante a execução do nosso programa page-faults:
$ gcc page-faults.c -o page-faults.o $ dd if=/dev/zero of=teste.out bs=4096 count=40000 $ sudo echo 0 > /sys/block/sda/queue/read_ahead_kb $ ./page-faults.o teste.out Memoria alocada. Pressione qualquer tecla para preencher a memoria Memoria preenchida. Pressione qualquer tecla para desalocar Pressione qualquer tecla mapear o arquivo teste.out em memoria Arquivo mapeado com sucesso. Pressione qualquer tecla para percorrer os bytes do arquivo Pressione qualquer tecla desfazer o mapeamento
Em outro terminal:
$ cat /proc/$(pgrep -f ./page-faults.o)/stat | awk '{ print "Minor:" $10 " Major:" $12}' ; #Com a memoria alocada e não prenchida
Minor:74 Major:0
$ cat /proc/$(pgrep -f ./page-faults.o)/stat | awk '{ print "Minor:" $10 " Major:" $12}' ; #Com a memoria preenchida:
Minor:330 Major:0
$ cat /proc/$(pgrep -f ./page-faults.o)/stat | awk '{ print "Minor:" $10 " Major:" $12}' ; #Com a memoria desalocada:
Minor:332 Major:0
$ cat /proc/$(pgrep -f ./page-faults.o)/stat | awk '{ print "Minor:" $10 " Major:" $12}' ; #Com o mapeamento do arquivo realizado:
Minor:332 Major:0
$ cat /proc/$(pgrep -f ./page-faults.o)/stat | awk '{ print "Minor:" $10 " Major:" $12}' ; #Com todo arquivo percorrido:
Minor:332 Major:40000
Antes de executar o page-faults.o criamos o arquivo teste.out através do comando dd com 163840000 bytes (156,25MB) e desabilitamos o comportamento de read ahead no kernel através do arquivo /sys/block/sda/queue/read_ahead_kb, o que se faz necessário neste exemplo para evitar que o kernel tente realizar uma leitura adiantada das próximas páginas e evite um major fault (nos próximos posts iremos detalhar melhor esse comportamento).
Com o programa em execução vemos que mesmo com 1048576 bytes de memória alocada os minor page faults ocorrem somente após sua incialização, onde temos 256 minor faults(330 – 74), considerando que o tamanho da página é de 4096, basta multiplicar esse valor por 256 e temos 1048576 que é exatamente o valor alocado. Ja os “major faults” só ocorrem após a leitura do arquivo mapeado em memória, que neste caso foram “40000”, o que multiplicado por 4096 resulta em 163840000 que é o exato tamanho do arquivo.
O que acontece quando ocorre uma troca de contexto ?
A cada troca de contexto o kernel atualiza o registrador “CR3” apontando para a PGD do novo processo. Quando esta operação é realizada ocorre a limpeza (flush) completa do TLB, já que as entradas de mapeamentos presentes são referentes ao processo anterior e não podem ser misturadas às entradas do novo processo.
No entanto a partir da versão 4.14 do kernel esse comportamento foi alterado para trabalhar utilizando o recurso PCID da arquitetura x86-64. Esta funcionalidade permite que as entradas do TLB tenham uma identificação com o ID do processo referente a entrada, e também permite o armazenamento do ID do processo corrente em bits específicos do registrador “CR3”. Dessa forma não é necessária a limpeza do TLB a cada troca de contexto, pois o TLB “sabe” quais entradas são válidas ao processo atual. Para habilitar essa funcionalidade o kernel precisa definir o bit PCID do registrador “CR4”.
Vale salientar que a implementação do Linux não utiliza exatamente o PID do processo para a atrelar ao PCID, pois existem apenas 12bits disponíveis para o PCID, o que resultaria e um número máximo de 4096, o que é bem menor em relação aos PIDs possíveis no Linux.
Próximos passos
No próximo post iremos focar em alguns comportamentos relacionados ao uso de memória de virtual, como a superalocação de memória, uso de SWAP, estouro de memória de RAM e o que pode ocorrer em máquinas com uma grande quantidade de memória RAM.
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Guia passo a passo para configurar um ReplicatSet no MongoDB
O MongoDB é um banco com foco em escalabilidade horizontal, sendo assim ele possui um recurso chamado ReplicatSet que serve para replicar os dados em um cluster de servidores para

Descubra como otimizar sua experiência de jogos no Linux
Jogar é um excelente passatempo. Pessoas de todos os cantos do mundo se reúnem em grupos, seja para atirar, pilotar, construir, ou simplesmente socializar enquanto salvamos alguns reféns em perigo

Aprenda a usar a base de dados Pagila para testes no PostgreSQL
Quando comecei aprender sobre banco de dados, senti falta de bases de dados prontas para fins de teste com o PostgreSQL. Eu queria aplicar conceitos aprendidos sobre SELECT, INSERT, UPDATE






