
Automatize processos com Ansible e otimize seu tempo de trabalho
Já parou para pensar como seria incrível executar um comando, e quase que instantaneamente, teríamos um processo que normalmente exigiria alguns bons minutos ou horas para executar, com diversas etapas para realizar? Ou aquele gerenciamento que precisa ser realizado diariamente as mesmas etapas repetitivas, como seria mais fácil um simples click e o ambiente estaria provisionado, com outro click um servidor configurado e disponível para ser colocado em produção, ou quem sabe a implantação ou gerencia de uma aplicação.
Para quem ainda imagina ser um sonho esse tipo de realização, te apresento o Ansible, uma ferramenta de códido aberto para uso em automações, gerenciamentos, provisionamentos e diversos outros processos.
O Ansible possui a característica de não precisar de agentes para gerenciar outras máquinas, que são chamadas de nós, é necessário apenas do python instalado nestas máquinas e uma conexão SSH com uma confiança estabelecida, ou seja, o Ansible usa o protocolo SSH para realizar uma comunicação segura com as máquinas que serão gerenciadas, e a partir desta correspondência, é realizado a execução de módulos, que são scripts escritos em python, que realizam as tarefas que foram definidas, existem centenas de módulos cada um com o objetivo de executar um processo específico.
Estes módulos são definidos em arquivos com formato YAML, e são chamados de playbooks, neste arquivo são definidas as etapas que serão necessárias para concluir o objetivo principal ao escolher utilizar o Ansible, como por exemplo, podemos escrever uma playbook para automatizar um Data Center, de maneira completa, seguindo de maneira direta os mesmos passos que poderiam ser realizados manualmente. Ou pode ser realizado até mesmo uma playbook simples, que realizasse um ping em cada nó apenas para testar a conexão.
Como é a estrutura de gerenciamento do Ansible?
Após ter estabelecido uma conexão segura com os servidores alvo, podemos prosseguir com a estrutura de arquivos, dependendo do projeto realizado será necessário arquivos específicos e mais detalhados.
Vamos exemplificar com um projeto simples, que automatiza a criação de um servidor web com a presença do Apache, possibilitando a visualização de uma página web com informações, para entender como o Ansible funciona, este projeto teve como base a execução em uma máquina Debian 10, para uso em outras distribuições talvez seja necessário realizar pequenas modificações. Observe a seguinte estrutura como exemplo:
. ├── ansible.cfg ├── files │ ├── apache.conf.j2 │ └── index.html.j2 ├── inventory.yml └── playbook.yml
Detalhando a estrutura
Temos a playbook, é neste arquivos onde descrevemos tarefas para o Ansible realizar.
O inventory é onde fica armazenado informações sobre os nós, os servidores alvo, de nossas tarefas da playbook.
No diretório files temos dois arquivos com o formato .j2, estes arquivos são templates Jinja2, ou seja são modelos, podemos utilizar modelos de arquivos de configuração como nestes exemplos, para criar um arquivo de configuração durante a automação, juntamente com variáveis, podendo assim customizar facilmente informações de forma automatizada, onde o Ansible verifica as informações passadas nas variáveis e aplica no arquivo do template.
Por fim neste pequeno exemplo temos o ansible.cfg arquivo que suporta informações que realizam o controle e gerenciamento do Ansible.
O que tem ai dentro?
O arquivo ansible.cfg possui o seguinte conteúdo:
ansible.cfg:
[defaults] inventory = inventory.yml interpreter_python: /usr/bin/python3
Através dessas informações vemos que está sendo definido configurações padrões, que definem o arquivo inventory.yml como arquivo principal de inventário, e define o caminho do binário do python3 como padrão para uso, o interpretador Python é usado para execução do módulo em destinos remotos ou como um modo de descoberta automática.
O arquivo do inventory.yml encontramos estes detalhes a seguir:
inventory.yml:
all:
hosts:
192.168.57.200:
ansible_become: true
ansible_become_method: sudo
ansible_become_user: root
ansible_user: root
Para um arquivo de inventário os formatos mais comuns são em INI, que possui um arranjo mais básico, e tem o YAML, o formato utilizado no exemplo acima.
Ao definir all dizemos que todos os nós (hosts), serão afetados pelas execuções, estes nós são definidos dentro do módulo hosts, que no caso deste exemplo possui o IP descrito. Algumas opções de acesso também podem ser definidas neste arquivo de inventário através de variáveis de ambiente do Ansible, segue uma breve explicação:
- ansible_become – Alterna o uso de escalonamento de privilégios, permitindo que você ‘se torne’ outro usuário após o login.
- ansible_become_method – O usuário que seu login/usuário remoto ‘se torna’ ao usar o escalonamento de privilégios, a maioria dos sistemas usará ‘root’ quando nenhum usuário for especificado.
- ansible_become_user – executar operações como este usuário, por padrão é executado como root.
- ansible_user – define o usuário a ser utilizado.
Dentro da pasta files encontramos dois arquivos de template Jinja2:
apache.conf.j2:
<VirtualHost *:{{ port_http }}>
ServerName {{ hostname }}
ServerAlias www.{{ host_alias }}
ServerAdmin root@localhost
DocumentRoot /var/www/html/{{ hostname }}
DirectoryIndex index.html
ErrorLog /var/log/apache2/error.log
TransferLog /var/log/apache2/access.log
</VirtualHost>
index.html.j2:
<!DOCTYPE html>
<html>
<head>
<title>Tux the Pinguin!</title>
</head>
<body>
<h1>Welcome to {{ hostname }}!!</h1>
<h2>Aventuras no mundo do DevOps!</h2>
<h2>Venha conhecer os Cursos da 4Linux e se surpreenda!!</h2>
<a href="https://4linux.com.br/"><h1>VISITE OS CURSOS 4LINUX!</h1></a>
</body>
</html>
O arquivo apache.conf é um arquivo de configuração padrão do serviço do Apache, o que está sendo realizado neste arquivo apache.conf.j2 é adicionar variáveis que podem ser customizadas, ao invés de utilizar informações fixas.
O arquivo index.html.j2 segue o padrão de utilização em diversos servidores web para armazenar conteúdos para uma página base, porém além das informações normais, neste template também pode conter variáveis para uma fácil transformação durante as execuções automatizadas pelo Ansible.
Por fim temos o arquivo protagonista para este esquema, o playbook.yml, existem diferentes formas de organização para cada função que será executadas, podendo ser colocadas dentro de roles, para uma melhor organização e direcionamento, ou se for um projeto sem muitas funções e tarefas, como é o caso deste exemplo, pode ser adicionado diretamente na playbook:
playbook.yml:
- hosts: all
vars:
username: "root"
hostname: "tux.4linux.com.br"
host_alias: www.{{ hostname }}
file_conf: "{{ hostname }}.conf"
site_disabled: true
port_http: "80"
tasks:
- name: Instalando Apache2
apt:
name: apache2
update_cache: yes
state: latest
- name: Criando diretorio para o site
file:
path: "/var/www/html/{{ hostname }}"
state: directory
owner: "{{ username }}"
group: "{{ username }}"
mode: '0755'
- name: Criando o arquivo index da página
template:
src: "files/index.html.j2"
dest: "/var/www/html/{{ hostname }}/index.html"
- name: Criando arquivo de configuração
template:
src: "files/apache.conf.j2"
dest: "/etc/apache2/sites-available/{{ file_conf }}"
- name: Desabilitando o site padrão
command:
cmd: /usr/sbin/a2dissite 000-default.conf
when: site_disabled
notify: Reload_Apache
- name: Habilitando o site criado
command:
cmd: /usr/sbin/a2ensite {{ file_conf }}
notify: Reload_Apache
handlers:
- name: Reload_Apache
service:
name: apache2
state: reloaded
Vamos à uma explicação geral sobre o que este arquivo faz, no módulo hosts, temos all, então todos os nós listado no arquivo inventory.yml serão afetados pelas execuções.
Em vars está sendo estabelecido algumas variáveis e seus valores, que foram aplicadas nos arquivos de templates, principalmente para definir os valores necessários para o arquivos de configuração do Apache, como porta que será utilizada para o serviço e qual o hostname que será utilizado.
Tasks é módulo usado para dizer ao Ansible quais as tarefas devem ser executadas, ao utilizar primeiramente o name, é apenas para ficar fácil de visualizar o que está sendo realizado em determinada etapa, seria basicamente um rótulo para a tarefa.
O apt é utilizado para realizar a instalações de pacotes .deb, passando o name dizemos qual pacote é para ser instalado, com o update_cache, é executado algo equivalente ao apt-get update antes de fazer a instalação, e o state é para especificar qual a versão desejada.
Com o módulo file é possível realizar a criação de um arquivo ou diretório, por exemplo, podendo passar o caminho de onde ele será criado nas máquinas, quem será o owner(dono), o group(grupo dono), e qual o mode(permissão) desta nova criação.
Como temos os templates, podemos utilizar o módulo template, que definimos o local de origem(src), onde ele está armazenado em nossa máquina controladora, e qual o caminho de destino(dest) exato que este arquivo será armazenado na máquinas que está sendo gerenciada.
Com o módulo command, é possível executar comandos à serem executados em cada nó, a partir desta execução com o when, é realizado uma verificação, baseado no valor de uma das variáveis definidas, se essa verificação for verdadeira(true), será iniciado um aviso com o notify.
A função handlers, realiza as execuções baseado nos chamados do módulo notify, por exemplo, se o comando para desabilitar o site padrão do Apache, for executado com sucesso e o site for desabilitado, o notify envia essa informação para um bloco do handlers, que irá executar algo, no caso do exemplo é executado o reload no serviço do Apache.
Resumindo…
Esta playbook, irá realizar a execução em todos os hosts, definidos no inventory.yml, seguindo as configurações definidas em ansible.cfg, fará a instalação do Apache em sua última versão, irá criar um diretório específico para o site que será criado, definindo o caminho, dono, grupo e permissões, criará o index.html a partir do template Jinja2, realizará a criação do principal arquivo de configuração do Apache, a partir do template e das variáveis definidas, desabilitará as configurações do site padrão do Apache, e em seguida habilitará o novo site criado, se tudo ocorrer com sucesso fará a reinicialização do serviço do Apache, finalizando para que esteja acessível via web.
Para iniciar esta automação será necessário o seguinte comando, para realizar a execução da playbook, que realizar todas as etapas definidas:
ansible-playbook playbook.yml
O comando acima deverá ser executado no mesmo local onde o arquivo da playbook se encontra, no caso de ter a seguinte estrutura, acesse a pasta apache, e seguida conseguirá executar(caso não esteja dentro da pasta será necessário passar o caminho absoluto do inventário e da playbook):
apache
├── ansible.cfg
├── files
│ ├── apache.conf.j2
│ └── index.html.j2
├── inventory.yml
└── playbook.yml
Para realizar a verificação se tudo ocorreu com sucesso as etapas, podemos acessar através de um navegador, o endereço IP do host e teremos a seguinte tela:
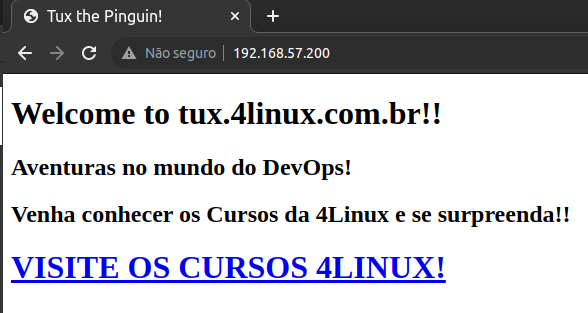
Quer saber mais sobre Ansible? Conquistar a possibilidade de se tornar Especialista em Automação com Ansible e potencializar sua carreira?
Conheça o curso ESPECIALISTA EM AUTOMAÇÃO COM ANSIBLE
Líder em Treinamento e serviços de Consultoria, Suporte e Implantação para o mundo open source. Conheça nossas soluções:
About author

Você pode gostar também

Descubra como o Skaffold pode otimizar seu trabalho com Kubernetes
Olá pessoal! A ideia para este post surgiu quando me deparei com o problema, que todos que trabalham ou vão trabalhar com Kubernetes enfrentam: a necessidade de a cada simples

Desvendando o DevOps: Entenda a Integração, Entrega e Implantação Contínua
Continuous Integration (Integração Continua), Continuous Delivery (Entrega Continua) e Continuous Deployment (Implantação Continua) são práticas DevOps muito populares nos últimos anos, mas o que são e as diferenças entre elas

Dominando o Docker Compose: Guia completo para gerenciamento de multi-contêineres
Como foi visto em nosso post anterior sobre o Docker [1], para realizar a execução de um contêiner basta executar o comando docker container run, porém, e se for necessário






