Provisionamento de Data Platform na Azure com Terraform: Um Guia Prático
Um dos exemplos citados no ebook Governance as Code da 4Linux, é uma plataforma de dados na azure.
Esse exemplo foi baseado no cenário atual em que eu trabalho, onde temos um time chamado Data Platform e temos os times de produtos, que chamamos de Data Products, esses trabalham em cima da plataformas de dados que foram criadas e disponibilizadas por nos.
Então imagine o seguinte cenário:
Produto: Previsão de Vendas
– Requisitos: Azure Data Factory, Storage Accounts, Key Vault
Produto: Analise de Vendas de Produtos
– Requisitos: Azure Data Factory, Storage Accounts, Key Vault
Produto: Analise de Pos Vendas
– Requisitos: Azure Data Factory, Storage Accounts, Key Vault
Note que os diferentes produtos precisam exatamente das mesmas infraestruturas, por isso temos um time chamado Data Platform que tem como objetivo fazer o provisionamento e a governança dessa infraestrutura. Dessa maneira os times focam apenas no desenvolvimento e na analise desses dados.
Vamos assumir o papel desse time de Data Platform e provisionar esses recursos utilizando o terraform.
Todos os codigos estao nesse repositorio:
https://github.com/AlissonMMenezes/azure-dataplatform
Entao o primeiro passo sera criar um modulo do Terraform com todas as configuraçōes necessárias para provisionar essa infraestrutura.
Assim que esse modulo for definido, podemos chama-lo varias vezes com diferentes variáveis e disponibilizar a mesma infraestrutura, porem com diferentes regras.
Vamos comecar.
A estrutura de diretorios deve ficar da seguinte maneira:
azure-dataplatform git:(main) ✗ tree
.
├── LICENSE
├── README.md
├── data_platform
│ ├── main.tf
│ └── variables.tf
├── environments
│ ├── dev
│ │ ├── avp.tf
│ │ └── pv.tf
│ └── prod
├── main.tf
├── provider.tf
└── variables.tf
Dentro do diretorio data_platform, vamos codificar o nosso modulo, que tem 2 arquivos.
main.tf, que deve ter o seguinte conteudo:
resource "azurerm_resource_group" "rg" {
name = var.resource_group_name
location = var.location
}
resource "azurerm_key_vault" "kv" {
name = var.key_vault_name
location = var.location
resource_group_name = var.resource_group_name
enabled_for_disk_encryption = true
tenant_id = var.tenant_id
soft_delete_retention_days = 7
purge_protection_enabled = false
sku_name = "standard"
depends_on = [
azurerm_resource_group.rg
]
}
resource "azurerm_storage_account" "sa" {
name = var.storage_account_name
resource_group_name = var.resource_group_name
location = var.location
account_tier = "Standard"
account_replication_type = "GRS"
is_hns_enabled = "true"
blob_properties {
delete_retention_policy {
days = 7
}
container_delete_retention_policy {
days = 7
}
}
identity {
type = "SystemAssigned"
}
depends_on = [
azurerm_resource_group.rg
]
}
resource "azurerm_storage_data_lake_gen2_filesystem" "datalake" {
name = "data"
storage_account_id = azurerm_storage_account.sa.id
properties = {
hello = "aGVsbG8="
}
depends_on = [
azurerm_storage_account.sa
]
}
resource "azurerm_data_factory" "df" {
name = var.data_factory_name
location = var.location
resource_group_name = var.resource_group_name
identity {
type = "SystemAssigned"
}
depends_on = [
azurerm_key_vault.kv,
azurerm_storage_account.sa
]
}
resource "azurerm_data_factory_linked_service_data_lake_storage_gen2" "dl" {
name = "LS_SA_${var.storage_account_name}"
data_factory_id = azurerm_data_factory.df.id
use_managed_identity = true
url = azurerm_storage_account.sa.primary_dfs_endpoint
}
resource "azurerm_data_factory_linked_service_key_vault" "ls_kv" {
name = "LS_KV_${var.key_vault_name}"
data_factory_id = azurerm_data_factory.df.id
key_vault_id = azurerm_key_vault.kv.id
}
Esse arquivo tem todas as informacoes e recursos que precisamos para provisionar a nossa Data Platform.
Nele e criado.
1 – Resource Group ( Onde agrupamos os recursos dentro de um determinado contexto na nossa conta azure )
2 – Key Vault ( Onde armazenamos todas as nossas chaves de acesso, senhas e etc )
3 – Storage Account ( Que e o Data Lake onde todos os arquivos utilizados pelos Data Engineers podem ser armazenados )
4 – Azure Data Factory ( que seria a ferramenta da Azure para criar Data Pipelines, equivalente ao Airflow )
Fora esses recursos, tambem criamos 2 LinkedServices, esses sao conectores que precisam ser configurados no Data Factory para fazer a conexao com recursos externos, como no nosso exemplo o KeyVault e a Storage Account.
Dentro do varables.tf temos o seguinte codigo:
variable "storage_account_name" {
type = string
description = "Storage Account Name"
}
variable "key_vault_name" {
type = string
description = "Key Vault Name"
}
variable "data_factory_name" {
type = string
description = "Data Factory Name"
}
variable "resource_group_name" {
type = string
description = "Resource Group name"
}
variable "location" {
type = string
description = "location"
default = "eastus"
}
variable "tenant_id" {
type = string
description = "Tenant ID"
default = "8abcf116-35fa-47ac-90ff-0d9db900a1a4"
}
Essas sao as varaveis e os tipos que sao utilizados dentro do nosso modulo de Data Platform, note que a variavel location, tem como por padrao o valor eastus, isso significa que caso nao seja especificado uma regiao em especifico, essa sera utilizada.
Em tenant_id, temos basicamente o ID do Active Directory, entao defina o ID da sua conta na azure.
No diretorio raiz entao, temos o os seguintes codigos:
main.tf
locals {
storage_account_name = lower("${var.product_name}dstoragedp")
key_vault_name = lower("${var.product_name}-d-keyvault-dp")
data_factory_name = lower("${var.product_name}-d-df")
resource_group_name = lower("${var.product_name}-d-rg")
}
module "data-platform" {
storage_account_name = local.storage_account_name
key_vault_name = local.key_vault_name
data_factory_name = local.data_factory_name
resource_group_name = local.resource_group_name
source = "./data_platform"
}
Nesse codigo estamos padronizando os nomes dos recursos de acordo com o nome do produto que vamos provisionar. Entao todas comecam com o nome do produto, seguido do ambiente e o nome do recurso.
Veja que tamos o bloco “module” e nele especificamos a instrucao source = “./data_platform”, que e o diretorio onde colocamos o codigo anterior.
E uma pratica comum definir esse source como um repositorio no Github por exemplo. Assim voce teria uma melhor organizacao, onde o codigo do modulo fica em um repositoro e pode ser reutilizado por toda e empresa e no outro repositorio voce faz o provisionamento dos servicos.
variables.tf ficou da seguinte maneira.
variable "product_name" {
type = string
description = "Product name"
}
Onde temos somente uma variavel.
O provider.tf seguimos com o codigo padrao.
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
}
}
}
# Configure the Microsoft Azure Provider
provider "azurerm" {
features {}
}
Lembre que eu defini um diretorio onde colocaremos os nomes dos produtos como variaveis separados por ambiente.
├── environments
│ ├── dev
│ │ ├── avp.tf
│ │ └── pv.tf
│ └── prod
Pegando como exemplo o pv.tf , ficou da seguinte maneira.
# estou abreviando o nome do projeto Previsao de Vendas como pv
product_name = "pv"
Agora que todos os arquivos ja foram definidos, voce pode executar o terraform init para fazer o download das dependencias:
terraform init
E o terraform apply para criar a sua Data Platform.
➜ azure-dataplatform git:(main) ✗ terraform apply -var-file="environments/dev/pv.tf"
module.data-platform.azurerm_resource_group.rg: Refreshing state... [id=/subscriptions/a198fb66-b65f-4dd9-8845-1cb50f3fc103/resourceGroups/pv-d-rg]
module.data-platform.azurerm_key_vault.kv: Refreshing state... [id=/subscriptions/a198fb66-b65f-4dd9-8845-1cb50f3fc103/resourceGroups/pv-d-rg/providers/Microsoft.KeyVault/vaults/pv-d-keyvault-dp]
module.data-platform.azurerm_storage_account.sa: Refreshing state... [id=/subscriptions/a198fb66-b65f-4dd9-8845-1cb50f3fc103/resourceGroups/pv-d-rg/providers/Microsoft.Storage/storageAccounts/pvdstoragedp]
module.data-platform.azurerm_data_factory.df: Refreshing state... [id=/subscriptions/a198fb66-b65f-4dd9-8845-1cb50f3fc103/resourceGroups/pv-d-rg/providers/Microsoft.DataFactory/factories/pv-d-df]
module.data-platform.azurerm_storage_data_lake_gen2_filesystem.datalake: Refreshing state... [id=https://pvdstoragedp.dfs.core.windows.net/data]
module.data-platform.azurerm_data_factory_linked_service_key_vault.ls_kv: Refreshing state... [id=/subscriptions/a198fb66-b65f-4dd9-8845-1cb50f3fc103/resourceGroups/pv-d-rg/providers/Microsoft.DataFactory/factories/pv-d-df/linkedservices/LS_KV_pv-d-keyvault-dp]
module.data-platform.azurerm_data_factory_linked_service_data_lake_storage_gen2.dl: Refreshing state... [id=/subscriptions/a198fb66-b65f-4dd9-8845-1cb50f3fc103/resourceGroups/pv-d-rg/providers/Microsoft.DataFactory/factories/pv-d-df/linkedservices/LS_SA_pvdstoragedp]
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration and found no differences, so no changes are needed.
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
Perfeito!
Se voce acessar a sua conta azure agora, voce devera ver algo similar a imagem abaixo:
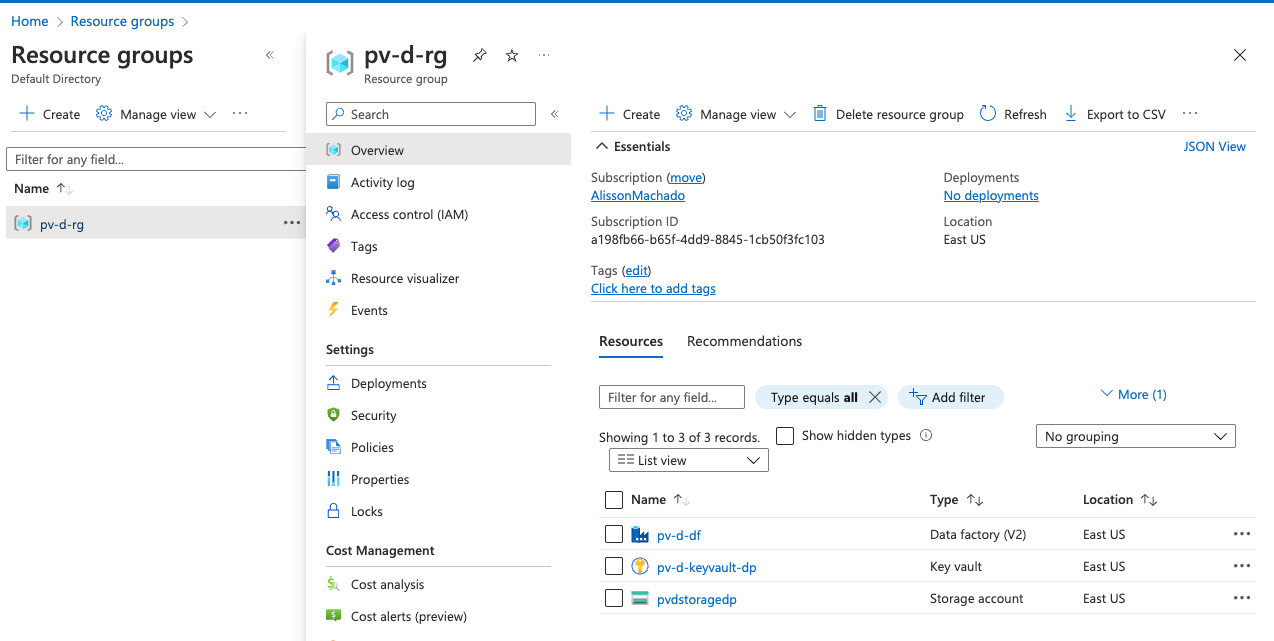
Otimo! Isso mostra que todos os nossos recursos foram provisionados!
Vamos verificar tambem as conexoes atraves dos LinkedServices que criamos durante o provisionamento da Data Platform.
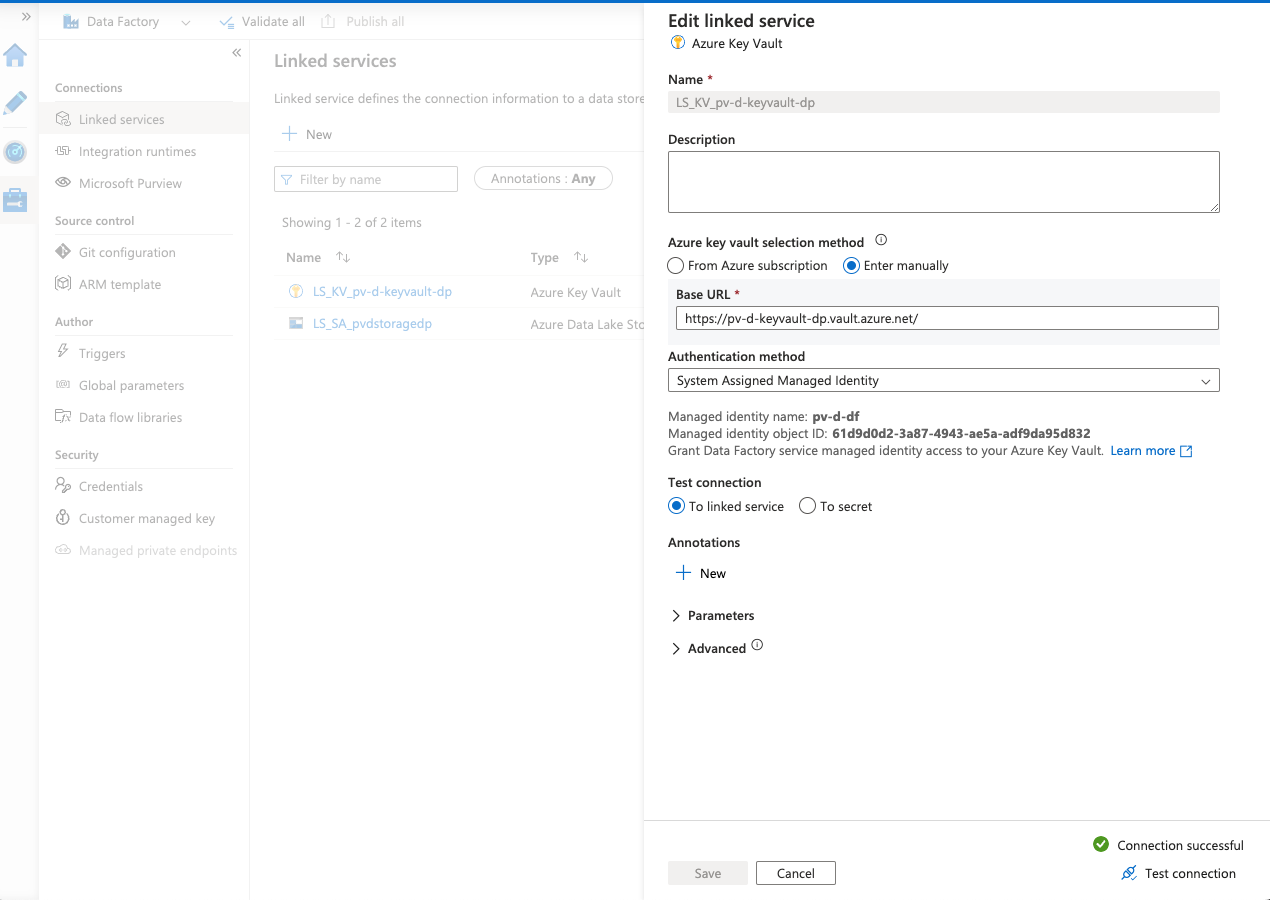
Veja no canto inferior da imagem que ao testar a conexao, o resultado e sucesso!
Entao a nossa plataforma foi provisionada com sucesso e toda as conexoes estao funcionando corretamente.
Agora voce pode modificar os modulos conforme a demanda, pode ser que no seu caso, ao inves de utilizar o Azure Data Factory, os Data Engineers queiram utilizar o Azure Synapse, pois ele da a possibilidade de executar notebooks spark.
Espero que tenha ajudado de alguma forma.
Obrigado =)
About author

Você pode gostar também

Descubra como o MetalLB aprimora o balanceamento de carga em ambientes Kubernetes on-premises
Por que usar o MetalLB em um ambiente on-premises? O MetalLB é uma solução essencial para clusters Kubernetes que não estão sendo executados em um ambiente de nuvem. Em ambientes

Descubra as Oportunidades no Mercado DevOps em Ascensão
Oportunidades no Mercado DevOps O mercado de trabalho para quem conhece DevOps está em acensão, e atualmente é uma das áreas que mais contrata funcionários tanto no Brasil quanto no

Primeiros passos com OpenStack: Como criar um ambiente de testes
Sempre que falamos sobre “primeiros passos” em alguma tecnologia, realizamos algum pequeno teste como um “Hello World” em uma linguagem ou um pequeno blog quando estamos estudando um framework web





