
Monitoramento de Dados: Como Utilizar o PostgreSQL e o PgPool com Zabbix
Com o mercado tecnológico cada vez mais crescente, o volume de dados aumenta significativamente a cada minuto, e esse volume é armazenado em diversos sistemas de banco de dados distribuídos.
Um estudo é realizado todo ano pela empresa Domo, que visa mostrar a quantidade de dados que são tramitados na internet a cada minuto. Este estudo se chama Data Never Sleeps, está na versão 10.0 e mostra através de um infográfico a quantidade de dados, por tipo de tecnologia, trafegados por cada plataforma.
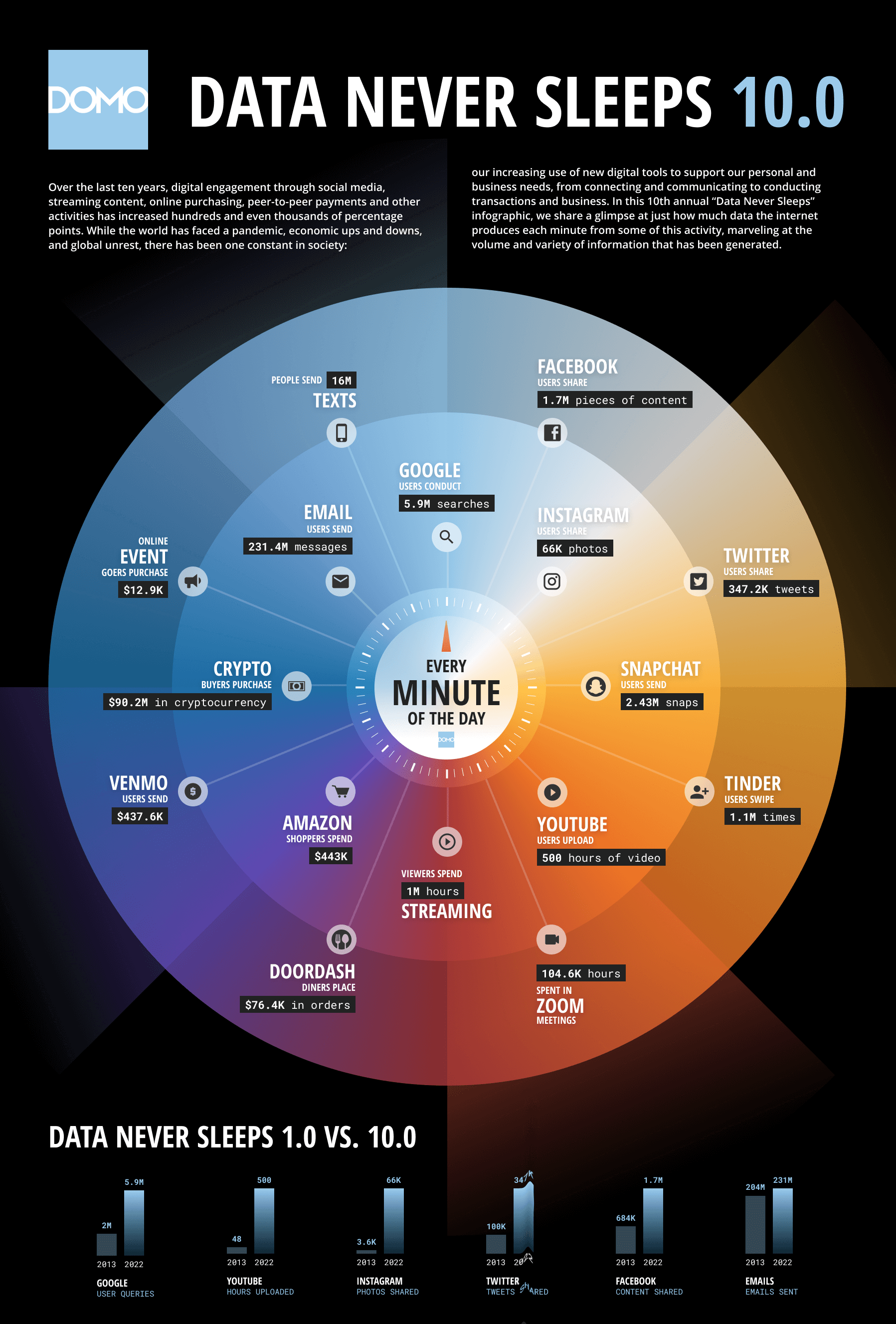
Para suprir a onda de acesso às redes sociais, disponibilização de conteúdos online e com necessidade de obter informações essenciais ao crescimento do negócio, a tecnologia utilizada para armazenamento são os bancos de dados.
Muitas provedoras de sistemas de nuvem, cloud computing, disponibilizam serviços para sustentação desses ambientes, que possuem como premissa de funcionamento a alta disponibilidade aliada ao escalonamento do espaço de armazenamento de acordo com o crescimento da empresa.
Mas muitas empresas ainda possuem sua infraestrutura de serviço baseado em arquitetura on-premise, ou seja, todo o ambiente tecnológico está dentro de seu domínio.
Este tipo de arquitetura exige que toda a responsabilidade de disponibilidade, escalabilidade e disaster recovery seja da própria empresa.
Um dos sistemas de gerenciamento de banco de dados mais utilizados no mercado é o PostgreSQL, software livre que permite a utilização tanto para grandes volumes de dados quanto para pequenos volumes de dados.
Quando há a necessidade da gerência de grandes quantidades de ingestão dados muitas empresas adotam processos que melhoram a performance da aplicação e também de seu armazenamento.
PgPool
Pgpool-II é um middleware que funciona entre servidores PostgreSQL e também como um cliente de banco de dados PostgreSQL. É distribuído sob uma licença semelhante à BSD e MIT. Ele fornece os seguintes recursos:
- Pool de conexões
O Pgpool-II salva as conexões com os servidores PostgreSQL e as reutiliza sempre que uma nova conexão com as mesmas propriedades (ou seja, nome de usuário, banco de dados, versão do protocolo) chegar. Ele reduz a sobrecarga da conexão e melhora a taxa de transferência geral do sistema.
- Replicação
O Pgpool-II pode gerenciar vários servidores PostgreSQL. O uso da função de replicação permite criar um backup em tempo real em 2 ou mais discos físicos, para que o serviço possa continuar sem parar os servidores, em caso de falha do disco.
- Balanceamento de carga
Se um banco de dados for replicado, a execução de uma consulta SELECT em qualquer servidor retornará o mesmo resultado. O Pgpool-II aproveita o recurso de replicação para reduzir a carga em cada servidor PostgreSQL, distribuindo consultas SELECT entre vários servidores, melhorando a taxa de transferência geral do sistema. Na melhor das hipóteses, o desempenho melhora proporcionalmente ao número de servidores PostgreSQL. O balanceamento de carga funciona melhor em uma situação em que há muitos usuários executando muitas consultas ao mesmo tempo.
- Limitando Conexões Excedentes
Há um limite no número máximo de conexões simultâneas com o PostgreSQL, e as conexões são rejeitadas após esse número de conexões. Definir o número máximo de conexões, no entanto, aumenta o consumo de recursos e afeta o desempenho do sistema. Pgpool-II também tem um limite no número máximo de conexões, mas conexões extras serão enfileiradas em vez de retornar um erro imediatamente.
- Watchdog
O Watchdog pode coordenar vários Pgpool-II, criar um sistema de cluster robusto e evitar o ponto único de falha ou cérebro dividido. Watchdog pode executar verificação de vida contra outros nós pgpool-II, para detectar uma falha de Pgpool-II. Se o Pgpool-II ativo cair, o Pgpool-II em espera pode ser promovido a ativo e assumir o IP virtual.
- Cache de consulta de memória
O cache de consulta de memória permite salvar um par de instruções SELECT e seu resultado. Se um SELECT idêntico entrar, o Pgpool-II retorna o valor do cache. Como não há análise SQL nem acesso ao PostgreSQL, o uso no cache de memória é extremamente rápido. Por outro lado, pode ser mais lento que o caminho normal em alguns casos, porque adiciona alguma sobrecarga de armazenamento de dados de cache.
Com uma ferramenta tão poderosa gerenciando toda sua estrutura de dados, o monitoramento sobre seus processos é primordial para o seu funcionamento quanto a execução de seu trabalho para disponibilizar os dados para o sucesso da empresa.
Template para Zabbix Pg_Monz
O Zabbix é uma das ferramentas mais difundidas no mercado quando o assunto é monitoramento, por ser software livre, sua implantação é um grande chamariz para empresas que desejam ter robustez e garantia dos dados que são coletados pelo monitoramento tendo custos zero para aquisição da solução.
Diversas são as formas que o Zabbix promove para realizar coleta de dados pelo sistema de monitoramento, dentre eles, o mais utilizado quando falamos de sistemas é o Zabbix Agent.
Utilizando processos que constantemente realizam consultas de maneira passiva e ativa em ambientes, o Zabbix agent consegue por meio de auxiliadores monitorar banco de dados e ferramentas que compõem esse universo de gerenciamento de dados.
Então vamos para a prática e mostrar como monitorar o PgPool!
Implantação
A implantação consiste na utilização do Zabbix Agent em acionar scripts específicos que fazem a coleta dos dados via psql e envia para o servidor utilizando a ferramenta Zabbix-sender.
Esse acionamento se dá através de templates importados dentro do Zabbix Web.
Há um projeto de código aberto disponível para a comunidade e se chama pg_monz, este projeto possui templates para monitoramento de instâncias PostgreSQL e também para monitoramento de PgPool-II.
Vamos dividir a instalação em duas partes, sendo a primeira as configurações necessárias do PostgreSQL e PgPool e a versão do Zabbix Agent e sua instalação, a segunda parte é a instalação do template para o PgPool.
Primeira parte.
Zabbix Agent
A versão utilizada para este laboratório foi a versão v5.0 LTS do Zabbix, para instruções de instalação você pode consultar o passo a passo neste link aqui.
Utilizaremos como exemplo de sistema operacional o Debian 11 (Bullseye).
Criando o usuário no banco de dados
O primeiro requisito é que o banco de dados possua um usuário criado com permissão de consultas dentro das instâncias PostgreSQL, para isso siga os passos abaixo:
- Crie um usuário com permissão de somente leitura zbx_monitor em sua instância PostgreSQL.
Para versões PostgreSQL 10 ou acima, faça:
CREATE USER zbx_monitor WITH PASSWORD '<PASSWORD>' INHERIT; GRANT pg_monitor TO zbx_monitor;
Para versões PostgreSQL 9.6 ou abaixo, faça:
CREATE USER zbx_monitor WITH PASSWORD '<PASSWORD>'; RANT SELECT ON pg_stat_database TO zbx_monitor; -- To collect WAL metrics, the user must have a `superuser` role. ALTER USER zbx_monitor WITH SUPERUSER;
Com os pré-requisitos devidamente alinhados, podemos instalar e configurar o template do pgpool.
Segunda parte:
Precisamos realizar o clone do repositório para dentro do servidor onde está o Zabbix Agent instalado.
Preparação do Ambiente.
Clone o repositório:
$ git clone https://github.com/Jeovany/pg_monz.git
Pelo terminal instale o pacote utilizando o utilitário apt.
# apt install zabbix-sender
Acesse a pasta clonada.
$ cd pg_monz/
Arquivos de Configuração:
Copie os arquivos de configuração pg_monz para qualquer diretório em todos os servidores monitorados. Por padrão, presume-se que eles sejam instalados em /usr/local/etc.
$ cp usr-local-etc/* /usr/local/etc/
Altere os dados do arquivo abaixo para os parâmetros de conexão ao pgpool, o exemplo abaixo são os parâmetros padrões:
pgpool_funcs.conf
PGPOOLHOST=127.0.0.1 PGPOOLPORT=6432 PGPOOLROLE=pgpool PGPOOLDATABASE=postgres PGPOOLCONF=/opt/pgpool/4.4.3/etc/pgpool.conf
Scripts:
Copie os scripts pg_monz para qualquer diretório em todos os servidores monitorados e adicione-os à permissão de execução.
Por padrão, serão instalados em /usr/local/bin.
</span>
# cp usr-local-bin/* /usr/local/bin
# chmod +x /usr/local/bin/*.sh
userparameter_pgsql.conf:
Copie o arquivo de configuração do parâmetro do usuário para o agente Zabbix userparameter_pgsql.conf para o local especificado da máquina que possui o agente instalado.
Por exemplo, se o agente Zabbix estiver instalado em /etc/zabbix/, copie o arquivo para o seguinte local:
/etc/zabbix/zabbix_agentd.conf.d/userparameter_pgsql.conf
Por padrão, o diretório `/etc/zabbix/zabbix_agentd.d/` vem habilitado como diretório de configuração de *userparameter*. Caso o agent não consiga encontrar o diretório, verifique a chave dentro do arquivo de configuração do agent e adicione a seguinte linha:
Include=/etc/zabbix/zabbix_agentd.conf.d/
Configurando a conexão
Para que o Zabbix Agent consiga se conectar com as instâncias precisamos criar um arquivo para autenticação da conexão, este arquivo segue o padrão estabelecido para leitura do comando psql.
127.0.0.1:5432:*:postgres:somepassword
Altere o IP caso a conexão for para instâncias fora do servidor onde o Zabbix Agent está instalado.
</span> <span style="font-weight: 400;">$ cp pgpass /home/zabbix/.pgpass $ chmod 0600 /home/zabbix/.pgpass $ chown zabbix:zabbix /home/zabbix/.pgpass</span> <span style="font-weight: 400;">
Para finalizar as instalações temos que reiniciar o serviço do Zabbix Agent para que as configurações sejam lidas.
# systemctl restart zabbix-agent
Importação do template.
Faça login na interface Web do Zabbix e importe o template com o seguinte procedimento:
- Selecione a guia [Configuração] – [Modelos] e exiba a lista de modelos;
- Clique em [Importar] no canto superior direito e importe todos os arquivos xml, incluindo o pacote pg_monz em ordem;
- Se for bem-sucedido, os modelos importados serão adicionados à lista de modelos.
Configuração de macros do template.
Com o template importado, vincule-o ao host selecionado e configure os valores das chaves macros: {$PGPOOLLOGDIR}.
Abaixo segue o exemplo configurado no host
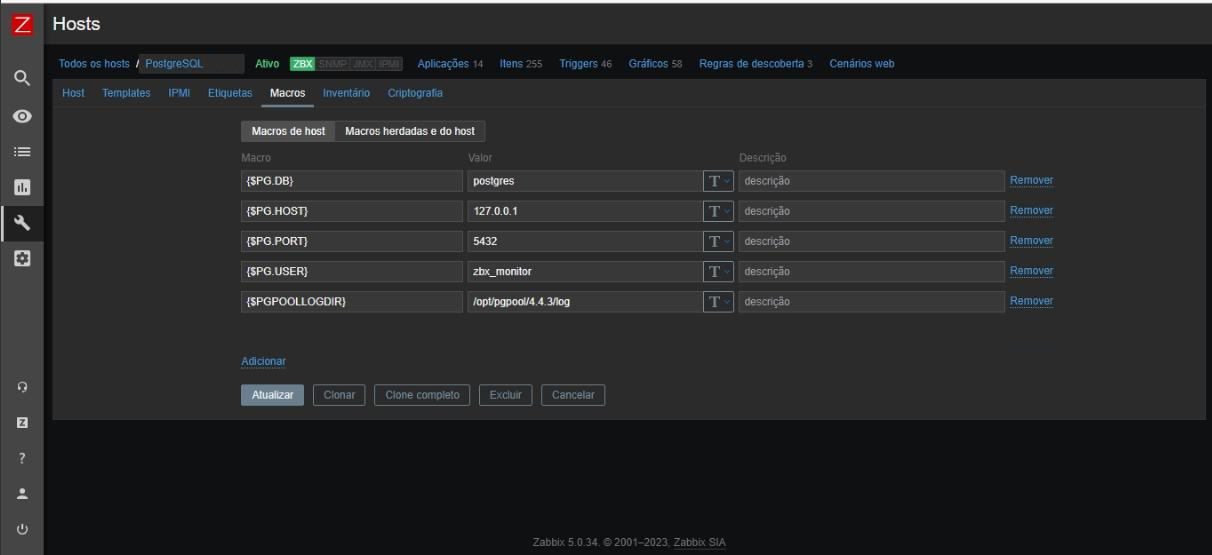
Observação: Crie um novo grupo de host no Zabbix. Este novo grupo destacará somente os hosts de postgresql adicionados a este monitoramento. Outra opção é colocar os novos templates e assim que cada host for adicionado ao grupo, automaticamente os templates serão adicionados ao host e já estarão monitorando os itens.
Triggers e Alertas
Todos os templates já carregam as triggers e regras de alertas sobre os itens monitorados de ambos templates. O envio de alertas está respondendo ao padrão já utilizado pelo Zabbix quando surgem alertas com criticidade alta.
Para ver quais triggers, regras de descobertas e itens que são carregados, basta acessar [Configuração]-[Hosts] e realizar o filtro pelo Host Group criado.
Conclusão
Finalizamos mais um post dinâmico e prático sobre monitoramento. Em nosso blog temos diversos posts com assuntos sobre observabilidade, dicas para certificações e também muito conteúdo prático.
Se quiser aprofundar mais neste assunto, aprender novas tecnologias ou novos processos, temos nossos treinamentos de trilha DevOps, DBA e muito mais. Temos treinamentos corporativos e turmas, então não fique esperando a oportunidade passar por você, vá em busca dela.
Nós da 4linux somos líderes de mercado no assunto opensource para treinamento e consultoria, trazendo sempre a melhor solução com robustez e confiabilidade de entrega.
Entre em contato conosco.


About author

Você pode gostar também

Entenda o SAST e como implementar com o Horusec em seu projeto
Saudações pessoal! Nós já falamos por aqui sobre DevSecOps e como implementar em nosso ciclo de desenvolvimento. Neste post iremos entrar em uma das etapas mais importantes deste ciclo de

Zabbix + Grafana: A Dupla Dinâmica para um Monitoramento de Elite
No universo do monitoramento de TI, duas ferramentas se destacam com frequência: Zabbix, por sua robustez e abrangência, e Grafana, por sua incrível capacidade de visualização de dados. Sozinhas, elas

Prometheus: A revolução do monitoramento open source em TI
Conheça o Prometheus, ferramenta open source de monitoramento adaptada ao atual modelo de TI focada em serviços e opção aos tradicionais Zabbix/Nagios.






