Guia Prático: Como Configurar um Cluster de Sharding no MongoDB
Sharding, no MongoDB, consiste uma forma para distribuir informações através de múltiplos servidores, dispondo de um grande cluster de dados.
O Recurso de Sharding é utilizando quando se trabalha com grandes datasets. Em certa semana, por exemplo, precisei configurar um cluster de mongodb com 3 máquinas guardando 3 terabytes de dados. Neste caso, trata-se de, Pré-Requisito, criar um cluster com sharding e replicação.
Mas, por que usar os dois recursos?
Porque a replicação garante a redundância dos seus dados. O sharding permite que você aumente o tamanho do seu dataset. No futuro, 3 terabytes podem não ser suficientes para armazenar todos os dados, sendo assim, bastará adicionar mais um servidor no sharding, desse modo o tamanho total de armazenamento aumentará.
Arquitetura do cluster.
Observe uma imagem da arquitetura de cluster.
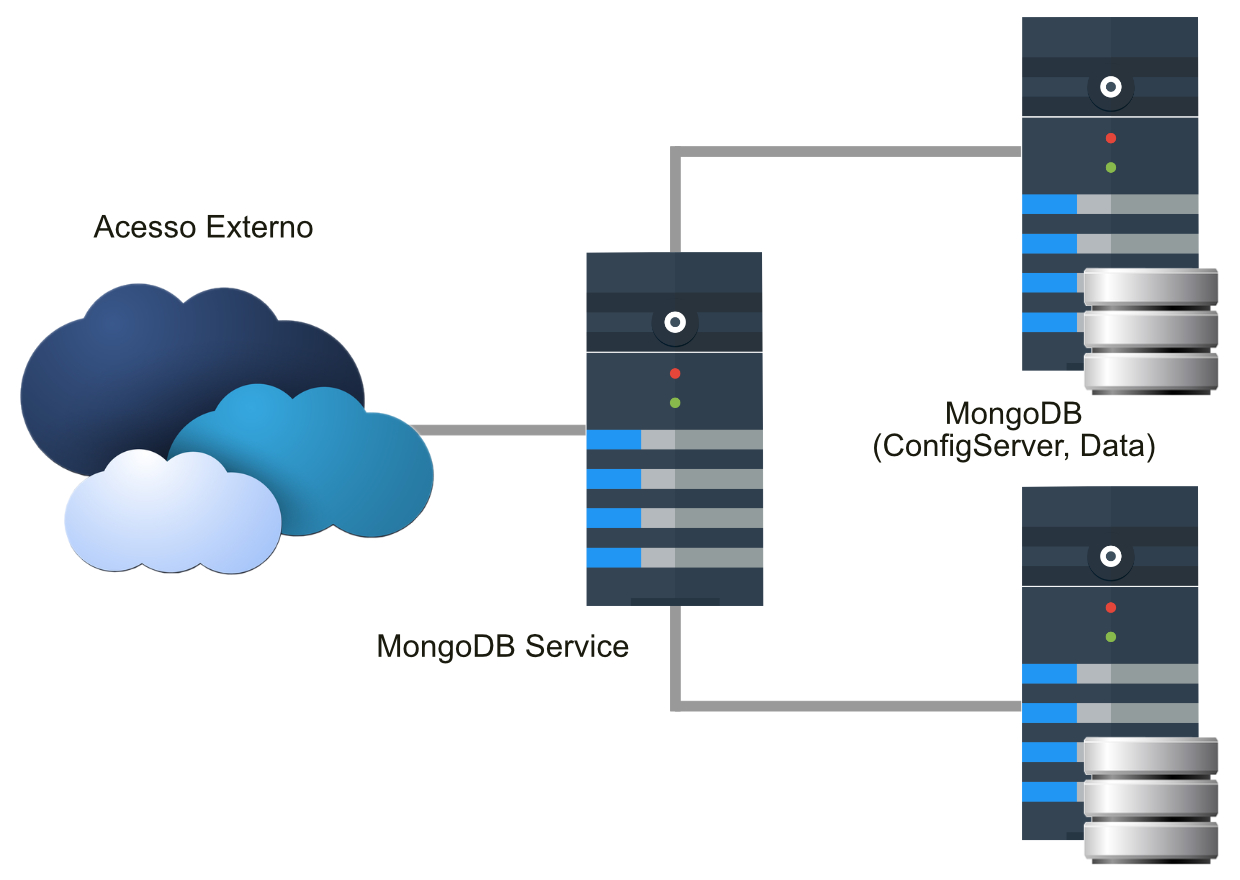
Entenda a arquitetura.
No diagrama apresentado, temos a representação de 1 servidor rodando o serviço chamado MongoService, responsável por balancear a carga entre os 2 servidores, atrás dele, que estarão replicados. Em uma arquitetura ideal, seria interessante contar, pelo menos, com 2 servidores executando o MongoService, garantindo uma alta disponibilidade, possuindo também um proxy-loadbalancer na frente. Nessa arquitetura, foi colocado apenas um, pois o cliente disponibilizou somente 3 máquinas.
Atrás desse servidor com o MongoService, temos 2 servidores. Em cada um deles serão executados 2 serviços do MongoDB, de forma diferente. Um dos servidores armazenará os dados, será chamado de DataServer, o outro denominado ConfigServer manterá os metadados do cluster.
Uma arquitetura minima, viável, para criar um cluster de sharding, reune pelo menos 6 máquinas. A seguir uma imagem da documentação oficial do mongodb.

Na imagem acima observamos:
– 2 servidores MongoService.
– 2 ConfigServer em Réplica.
– 2 Servidores em Shard em réplica.
Bom… Agora chega de imagens e arquitetura, vamos por a mão na massa…
Observe a seguir os apontamentos do meu arquivo /etc/hosts. Compartilhei as notas, pois toda a configuração será feita através de nomes. Lembrando, esse arquivo deve ser copiado para todas as máquinas, permitindo que conversem através dos nomes.
vim /etc/hosts 192.168.0.108 mongoservice 192.168.0.106 mongodb1 192.168.0.107 mongodb2
Para fazer a instalação do mongodb, será necessário configurar o repositório e fazer a instalação dos pacotes, nas 3 máquinas, conforme as instruções abaixo.
Configurando os repositórios.
vim /etc/yum.repos.d/mongodb-org-3.4.repo # conteudo abaixo foi adicionado no arquivo acima [mongodb-org-3.4] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
Agora a instalação.
yum -y install mongodb-org
Criando o Sharding e o ConfigServer.
Primeiro acesse o servidor mongodb1 e rode os seguintes comandos:
mkdir -p /data/{db,configdb}
mongod --replSet "rs0" --shardsvr --port 27017 &
mongod --configsvr --replSet configReplSet &
Executados os comandos acima, devem existir 2 serviços rodando na máquina, um na porta 27017 e outro na porta 27019.
Para validar execute o comando abaixo:
[root@localhost system]# ss -ntpl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:27019 *:* users:(("mongod",pid=11751,fd=6))
LISTEN 0 128 *:22 *:* users:(("sshd",pid=1147,fd=3))
LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=1947,fd=13))
LISTEN 0 128 *:27017 *:* users:(("mongod",pid=11685,fd=6))
LISTEN 0 128 :::22 :::* users:(("sshd",pid=1147,fd=4))
LISTEN 0 100 ::1:25 :::* users:(("master",pid=1947,fd=14))
Veja que os serviços citados, são mostrados na saída do comando ss -ntpl.
Agora, faça a mesma coisa no mongodb2.
Criando a réplica dos dados.
Para criar a réplica dos dados em qualquer um dos servidores, você pode digitar as instruções abaixo:
[root@localhost ~]# mongo
MongoDB shell version v3.4.3
connecting to: mongodb://127.0.0.1:27017
MongoDB server version: 3.4.3
Server has startup warnings:
2017-04-16T23:19:10.154-0400 I CONTROL [initandlisten]
2017-04-16T23:19:10.154-0400 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
2017-04-16T23:19:10.154-0400 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
2017-04-16T23:19:10.154-0400 I CONTROL [initandlisten] ** WARNING: You are running this process as the root user, which is not recommended.
2017-04-16T23:19:10.154-0400 I CONTROL [initandlisten]
> rs.initiate( {
_id : "rs0",
members: [ { _id : 0, host : "mongodb1:27017" } ]
})
Com os comandos apresentados, o próprio servidor foi adicionado ao replicaset rs0, criado anteriormente. Agora, para adicionar o segundo servidor execute as linhas abaixo:
[root@localhost ~]# mongo
MongoDB shell version v3.4.3
connecting to: mongodb://127.0.0.1:27017
MongoDB server version: 3.4.3
> rs0:PRIMARY> rs.add("mongodb2")
{ "ok" : 1 }
Para validar que estão em replica, você pode acessar o console do segundo servidor e validar se está aparecendo como SECONDARY:
[root@localhost ~]# mongo MongoDB shell version v3.4.3 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.4.3 rs0:SECONDARY>
Na saída do comando mostrado verificamos, no console, que o servidor faz parte do rs0, está como SECONDARY.
Para fazer a réplica do configserver em qualquer um dos dois servidores, você pode executar as seguintes instruções dentro do console do mongodb.
[root@localhost ~]# mongo localhost:27019
MongoDB shell version v3.4.3
connecting to: localhost:27019
MongoDB server version: 3.4.3
Server has startup warnings:
2017-04-16T23:15:10.890-0400 I CONTROL [initandlisten]
2017-04-16T23:15:10.890-0400 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
2017-04-16T23:15:10.890-0400 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
2017-04-16T23:15:10.890-0400 I CONTROL [initandlisten] ** WARNING: You are running this process as the root user, which is not recommended.
2017-04-16T23:15:10.890-0400 I CONTROL [initandlisten]
>
> rs.initiate( {
... _id: "configReplSet",
... configsvr: true,
... members: [
... { _id: 0, host: "mongodb1:27019" },
... { _id: 1, host: "mongodb2:27019" }
... ]
... } )
{ "ok" : 1 }
configReplSet:OTHER>
No exemplo, o cliente do mongodb foi executado para acessar a porta 27019, responsável por fazer a replicação do configserver, sendo a réplica criada nesta.
Com todas as réplicas configuradas, chegou o momento de configurar o service.
Acesseo servidor mongoservice e execute o seguinte comando:
mongos --configdb configReplSet/mongodb1:27019,mongodb2:27019 &
Esse comando iniciará um processo na porta 27017.
[root@localhost ~]# ss -ntpl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:* users:(("sshd",pid=1078,fd=3))
LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=1546,fd=13))
LISTEN 0 128 *:27017 *:* users:(("mongos",pid=11497,fd=4))
LISTEN 0 128 :::22 :::* users:(("sshd",pid=1078,fd=4))
LISTEN 0 100 ::1:25 :::* users:(("master",pid=1546,fd=14))
O mongoservice será o ponto de acesso para as réplicas configuradas no começo do artigo, este acesso será da seguinte maneira:
[root@localhost ~]# mongo mongoservice/admin Welcome to the MongoDB shell. mongos>
Note que agora o console está diferente, ao invés de ficar somente o sinal de maior ( > ), aparece mongos>, pois estamos acessando o service e não a base diretamente.
Para adicionar o nosso cluster de shard execute a linha:
> sh.addShard( "rs0/mongodb1:27017,mongodb2:27017" )
2017-04-16T23:45:03.496-0400 I NETWORK [conn2] Starting new replica set monitor for rs0/mongodb1:27017,mongodb2:27017
{ "shardAdded" : "rs0", "ok" : 1 }
A saída do comando mostra que o shard foi adicionado com sucesso.
No MongoService você pode adicionar quantos clusters de shard precisar.
Para criar um banco de dados dentro do seu cluster será necessário executar a instrução:
mongos> sh.enableSharding("alisson")
2017-04-16T23:46:51.918-0400 I SHARDING [conn2] distributed lock 'alisson' acquired for 'enableSharding', ts : 58f43aab9202a5538a1cb23c
2017-04-16T23:46:51.919-0400 I ASIO [NetworkInterfaceASIO-ShardRegistry-0] Connecting to mongodb1:27017
2017-04-16T23:46:51.920-0400 I ASIO [NetworkInterfaceASIO-ShardRegistry-0] Successfully connected to mongodb1:27017
2017-04-16T23:46:51.921-0400 I SHARDING [conn2] Placing [alisson] on: rs0
2017-04-16T23:46:51.921-0400 I SHARDING [conn2] Enabling sharding for database [alisson] in config db
2017-04-16T23:46:51.979-0400 I SHARDING [conn2] distributed lock with ts: 58f43aab9202a5538a1cb23c' unlocked.
{ "ok" : 1 }
Você poderá, acessar o banco de dados, criar um documento e fazer uma busca, para certificar-se de que já funciona:
mongos> use alisson;
switched to db alisson
mongos> db.documentos.insert({"nome":"teste"})
WriteResult({ "nInserted" : 1 })
mongos> db.documentos.find()
2017-04-16T23:48:19.957-0400 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-0-0] Connecting to mongodb1:27017
2017-04-16T23:48:19.958-0400 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-0-0] Successfully connected to mongodb1:27017
{ "_id" : ObjectId("58f43afd058b0dbab981298e"), "nome" : "teste" }
mongos> show dbs;
admin 0.000GB
alisson 0.000GB
config 0.000GB
mongos> show collections;
documentos
Veja que ao fazer o find do documento, é mostrado no log que o dado foi buscado dentro do servidor mongodb1.
Eu reiniciei o servidor primary, fazendo a mesma busca. Observe que a busca ocorreu no segundo servidor:
mongos> db.documentos.find()
2017-04-17T00:02:22.177-0400 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-0-0] Connecting to mongodb2:27017
2017-04-17T00:02:22.179-0400 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-0-0] Successfully connected to mongodb2:27017
{ "_id" : ObjectId("58f43afd058b0dbab981298e"), "nome" : "teste" }
Ao finalizar é importante adicionar autenticação ao mongodb, uma vez que por padrão, o usuário é anônimo.
Basta executar os comandos:
use admin
db.createUser(
{
user: "alisson",
pwd: "alisson123",
roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
}
)
alissonmachado.com.brทดลองเล่นสล็อต pgสล็อตเว็บตรงเว็บสล็อตเว็บตรงสล็อตjoker123สล็อต88ทดลองเล่นสล็อต PGเว็บดูบอลฟรีเว็บสล็อต PGufabet911สล็อตเว็บตรง
About author

Você pode gostar também

Engenheiro de Dados: a profissão essencial na era da informação
Profissões tendem a desaparecer e surgir com outras roupagens em um mundo onde a quantidade de conhecimento cresce exponencialmente. Embora esse fenômeno cause crises em algumas áreas, ele pode ser

4Linux atualiza seus cursos na área de Big Data!
Conheça os cursos de Big Data da 4Linux A fim de atender demandas específicas do mercado por profissionais de Ciência de Dados e Engenharia de Dados, a 4Linux decidiu reformular

OpenClaw na prática: 10 ideias reais para usar no dia a dia
Quando alguém conhece o OpenClaw, a primeira dúvida quase sempre é a mesma: beleza, mas onde isso realmente pode ser usado no dia a dia? Na teoria, muita coisa parece






