
Guia Prático: Como Instalar e Configurar o Apache Ambari em um Cluster Hadoop
O Apache Ambari é uma plataforma desenvolvida pela Hortonworks que permite instalar, configurar e monitorar um cluster hadoop em poucos minutos. Neste post irei ensinar como instalar o Ambari em um cluster com 1 Namenode, 2 Datanode, 1 maquina com Hbase e Hive.
Preparação do ambiente
Primeiramente vamos preparar o ambiente para a instalação do Ambari, no meu caso estou utilizando um CentOs 7.
Primeiro passo é configurar os hostname de cada máquina, para cada máquina digite o comando abaixo conforme o nome que deseja:
hostname novohostname
Após configurar o hostname vamos configurar o arquivo de hosts, para isso vamos utilizar o comando:
ip a
Ao digitar o comando ip a você recebera uma saída parecida com a imagem abaixo, onde está circulado em vermelho é o seu IP.
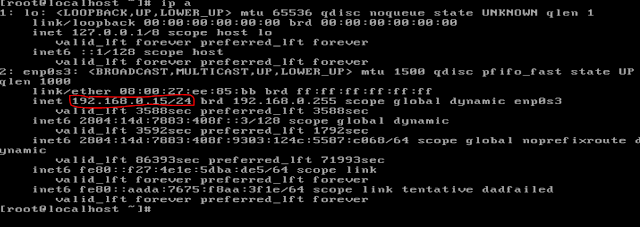
Após pegar o IP de cada máquina vamos editar o /etc/hosts, para isso podemos utilizar o editor de texto vi/vim ou fazer da seguinte forma:
echo "192.168.0.14" datanode1.hadoop.com.br >> /etc/hosts echo "192.168.0.15" namenode.hadoop.com.br >> /etc/hosts echo "192.168.0.16" datanode2.hadoop.com.br >> /etc/hosts echo "192.168.0.17" databases.hadoop.com.br >> /etc/hosts
No meu caso meus ip’s para as máquinas datanodes são 192.168.0.14 e 192.168.0.16, para a máquina namenode 192.168.0.15 e para a máquina de database foi atribuído 192.168.0.17.
PS: Os nomes em vermelho são os hostname de cada máquina, a minha máquina com ip 192.168.0.14 possui o hostname datanode1.hadoop.com.br
Próximo passo é desabilitar o iptables, para isso iremos utilizar o seguinte comando em TODAS as máquinas
systemctl disable firewalld service firewalld stop
Após desabilitar o iptables iremos desabilitar o selinux de TODAS as máquinas, primeiro vamos digitar o comando
setenforce 0
Depois vamos editar o arquivo /etc/selinux/config conforme a imagem abaixo:
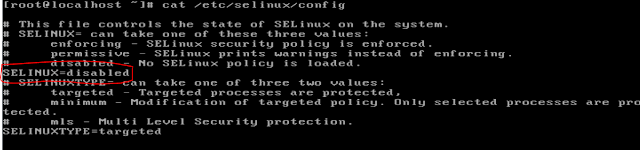
Agora vamos gerar uma chave ssh para que o ambari consiga acessar as máquinas, para isso vamos na máquina namenode e utilizar o seguinte comando:
ssh-keygen
Nas 2 perguntas do comando apenas aperte enter, agora vamos copiar a chave publica para todas a máquinas:
ssh-copy-id datanode1.hadoop.com.br ssh-copy-id datanode2.hadoop.com.br ssh-copy-id namenode.hadoop.com.br ssh-copy-id databases.hadoop.com.br
Precisamos realizar o ssh-copy-id da máquina namenode para ela mesma pois a chave que é gerada é usada.
Para terminamos a preparação do ambiente vamos configurar os repositórios da hortonworks somente na máquina namenode, primeiramente vamos instalar o wget com o comando:
yum install wget -y
Instalação do Ambari
Após instalar o wget vamos configurar o repositório da hortonworks para fazer o download:
wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.5.2.0/ambari.repo -O /etc/yum.repos.d/ambari.repo
Ao terminar de configurar o repositório da hortonworks vamos utilizar o comando abaixo para verificar se o repositório está ok
yum repolist
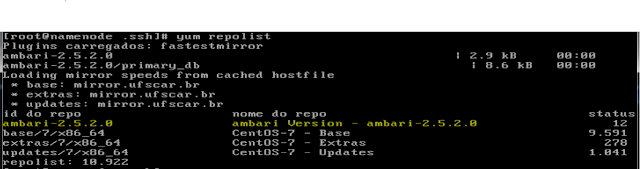
Com o repositório configurado corretamente vamos começar a instalação:
yum install ambari-server -y
Com a instalação concluída vamos começar a configurar:
ambari-server setup
Caso você queria configurar alguma configuração específica, fiquem a vontade caso contrário é só apertar enter na perguntas do terminal.
Após realizar o setup vamos iniciar o servidor com o comando:
ambari-server start
Para verificar se o servidor está rodando basta utilizar o comando:
ambari-server status
Para acessar a página web do servidor basta colocar no browse o ip do seu namenode na porta 8080, o usuário e senha padrão é admin/admin:
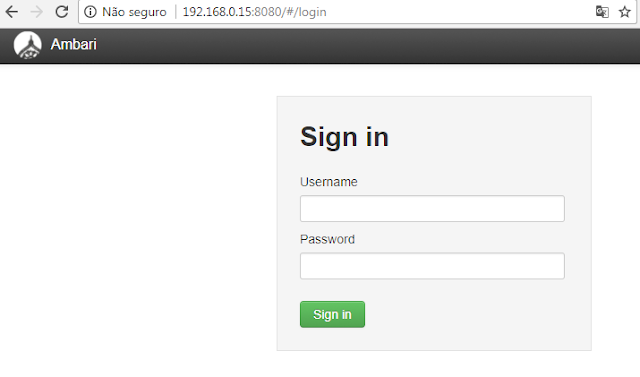
No próximo post irei ensinar como instalar e configurar as ferramentas do ambiente hadoop pelo Apache-Ambari.
About author

Você pode gostar também

Guia completo: Implantação de MongoDB resiliente no Google Kubernetes Engine
Este guia aborda a implantação de um MongoDB resiliente no GKE, incluindo etapas para configurar um StatefulSet, serviço headless e inicializar o conjunto réplica. Aprenda a utilizar recursos do GKE

Descubra como o RabbitMQ pode otimizar o processamento de dados em seu sistema web
O RabbitMQ é um software de controle e gerenciamento de filas de mensagens. Ele recebe e armazena mensagens em filas até que alguém solicite essas mensagens. As mensagens podem ser

Monitoramento Contínuo: A chave para uma infraestrutura de TI sustentável
Eventualmente, mesmo os sistemas e infraestruturas mais sustentáveis precisarão acompanhar os esforços para a prevenção. Por isso, o Continuous monitoring (monitoramento contínuo) é essencial. Técnicas de monitoramento contínuo costumam melhorar






